1. Introducción
En la actualidad, se reconoce que muchas regiones tienen un elevado producto interno bruto (PIB) per cápita, gracias al uso que hacen del conocimiento (Organización para la Cooperación y el Desarrollo Económico [OCDE], 2018); al respecto, diversos índices tratan de dar cuenta de ello (González, Alvarado y Martínez, 2004). La ventaja de estos índices radica en que capturan una representación de la categoría que ocupan las regiones en la competitividad y el uso del conocimiento (Arancegui, Martíns, Franco-Rodríguez y Alonso, 2011); además, ofrecen un análisis descriptivo del porqué unas regiones son más competitivas que otras en la economía del conocimiento, pero no explican la forma en que el conocimiento se produce ni la direccionalidad de los determinantes que participan en su producción (Arancegui et al., 2011).
Los analistas, conscientes de esta limitación desde la década de 1980, han implementado el marco analítico de la función de producción del conocimiento (FPC) regional, para explicar cómo se crea y usa el conocimiento en los territorios (Varga y Horváth, 2015). Desde los trabajos seminales de Griliches (1979) y Anselin, Varga y Acs (1997), la FPC se ha perfeccionado, incluyendo variables que describen los flujos de conocimiento o spillovers (SP) y modelos de econometría espacial (Dall’erba, Kang y Fang, 2017). A pesar de los avances logrados con la FPC, muchos autores han planteado que la producción de conocimiento (PRC) y su relación con el espacio geográfico es un fenómeno complejo, en el que, además del alcance de los SP, es importante tener en cuenta el ambiente institucional (Sotarauta, 2015).
Con el fin de llenar este vacío, Cooke, Uranga y Etxebarria (1997) introdujeron al análisis de la PRC el marco analítico de los sistemas regionales de innovación (SRI), mientras que Moulaert y Sekia (2003) introdujeron el concepto de modelos de innovación territorial (MIT). Bajo este marco, Meusburger (2013) y Jeannerat y Crevoisier (2016), entre otros investigadores, han llamado la atención sobre las dificultades que entraña la relación entre conocimiento y desarrollo, pues el conocimiento tiene propiedades distintas a los demás factores de producción. En efecto, Romer (1990) plantea que el conocimiento tiene la propiedad de exclusión parcial en el corto plazo, la no rivalidad en el largo plazo y la no convexidad de las curvas de costos. Asimismo, en una región, el conocimiento tiene la propiedad de ser acumulativo, colectivo, genérico y específico, a la vez que es sensible de ser combinado y recombinado (Johnson, Lorenz y Lundvall, 2002; Meusburger, 2013; Antonelli y Colombelli, 2015; Karlsson, Johansson, Kobayashi y Stough, 2014).
Los teóricos de la gestión del conocimiento han mostrado que este se presenta de manera explícita o tácita (Nonaka y Takeuchi, 1995). Por una parte, Asheim, Boschma y Cooke (2011) plantean que en una región existe conocimiento simbólico, analítico y sintético. Meusburger (2013) argumenta que la utilidad del conocimiento es dependiente del contexto, por lo que este no es solo información empaquetada en bienes que tienen valor de uso, además, es un elemento central de la toma de decisiones y de la acción social. Por otra parte, Johnson et al. (2002) han trabajado la hipótesis de que la competitividad de las regiones depende del conocimiento colectivo y del aprendizaje de las firmas e individuos. Storper y Venables (2004) destacan la importancia de las relaciones cara a cara para la generación de riqueza. Asimismo, Balland, Boschma y Frenken (2014) resaltan el papel de las proximidades como fuente de innovación y PRC.
Bajo estas ideas, se construyen indicadores compuestos para describir las propiedades del conocimiento (Arancegui et al., 2011). A partir de estos indicadores, se han planteado escalafones de clasificación y FPC, con los que se pretende capturar el desempeño de los territorios en la economía (Arancegui et al., 2011; Buesa, Hejis y Baumert, 2010). Pero si bien todas estas contribuciones al análisis del SRI son relevantes, no constituyen una teoría (Uyarra y Flanagan, 2010) y resultan en un concepto a veces confuso (Markusen, 2003). Es así como al explicar la producción del conocimiento y su relación con el espacio geográfico, se plantean desafíos teóricos, metodológicos y empíricos (Meusburger, 2013; Jeannerat y Crevoisier, 2016) en el marco de los SRI (Cooke et al., 1997) o los MIT (Moulaert y Sekia, 2003).
Para superar esta problemática, desde 1980 se han desarrollado proyectos que reúnen equipos interdisciplinarios de varios países europeos para estudiar la producción del conocimiento y su relación con el espacio. Sobresalen el proyecto de Milieux Innovateurs (Aydalot, 1986), el de Eurodite (Jeannerat y Crevoisier, 2016) y el de Espacios de Conocimiento de Meusburger (2013). Todos tienen como común denominador encontrar conceptos y formas de medición de la producción del conocimiento en el espacio (Tödtling y Trippl, 2005; Thierstein, Lüthi, Kruse, Gabi y Glanzmann, 2008; Jeannerat y Crevoisier, 2016).
En este contexto, el artículo propone un modelo de medición de la FPC, que explique la producción del conocimiento y su relación con el espacio geográfico y que ayude a comprender cómo se arraiga, circula y explota el conocimiento en las regiones más competitivas en la actual economía. De esta forma, el primer objetivo de este trabajo fue proponer una FPC basada en variables latentes o constructos que representen y describan las propiedades del conocimiento de las regiones. El segundo objetivo fue validar la consistencia y fiabilidad de las variables latentes y la estructura de la FPC propuesta.
Este documento se divide en cinco partes. Después de esta introducción, se realiza una revisión de la literatura, en la que se evidencia que existen cuestiones pendientes por revisar, tales como: i) cuál es la forma correcta de la función de producción; ii) cómo medir los SP o flujos de conocimientos dentro y entre territorios; y iii) cuál es la mejor proxy para medir el conocimiento de una región (Jeannerat y Crevoisier, 2016; Autant-Bernard y LeSage, 2019; Neves-Sequeira y Cunha-Neves, 2020). Luego, se plantea la metodología de construcción y cálculo de las variables latentes de la FPC, donde además se muestra la validez y consistencia de los constructos que la componen. En la cuarta sección se presentan los resultados y en el último apartado se plantean las principales conclusiones y recomendaciones.
2. La producción de conocimiento en las regiones
En la década de 1990, dos aspectos ocuparon la agenda de los investigadores del cambio técnico: el de la producción del conocimiento (Johnson et al., 2002) y el del nivel territorial en donde esta toma lugar (Cooke et al., 1997). Autores como Moulaert y Sekia (2003), Fritsch y Slavtchev (2011) han resaltado el papel de los SRI, para explicar la producción del conocimiento y su relación con el espacio.
Los SRI se describen como el ámbito donde las instituciones y organizaciones se articulan para producir y explotar el conocimiento, en un marco que pretende capturar las propiedades del conocimiento y explicar cómo se transforma en riqueza (Cooke et al., 1997; OCDE, 2018). A este marco se han incorporado conceptos tales como la educación superior o universitaria, la capacidad de adsorción, el capital intelectual, la capacidad de innovación, el capital financiero o de riesgo, la producción de patentes, la generación de servicios intensivos en conocimiento, la actividad empresarial y el mercado de trabajo (Arancegui et al., 2011).
Para operar estos conceptos, se suelen aplicar técnicas de análisis multivariante hasta obtener indicadores compuestos (Arancegui et al., 2011). A partir de ellos, se construyen índices o rankings de clasificación de regiones (González et al., 2004). También se plantean FPC donde sobresalen los trabajos de Fritsch y Slavtchev (2011), Buesa et al. (2010), Autant-Bernard y LeSage (2019). Luego, se calcula el rendimiento y la eficiencia de los SRI (Fritsch y Slavtchev, 2011). Además, se realizan estudios de corte transversal para comparar regiones e identificar jerarquías de competitividad y derivar conclusiones de política científica, tecnológica e industrial (Tödtling y Trippl, 2005; Arancegui et al., 2011). No obstante, las investigaciones de los SRI basados en indicadores compuestos o en FPC construidos con variables latentes son objeto de muchas críticas a nivel teórico, metodológico y empírico (Doloreux y Parto, 2004; Tödtling y Trippl, 2005; Thierstein, et al. 2008; Arancegui et al., 2011).
En cuanto al nivel teórico, se plantean desafíos en la construcción y planteamiento del instrumento. Por ejemplo, las patentes son un input, si lo que se pretende medir es el impacto de la producción del conocimiento en el desempeño económico de una región (Michie, Oughton y Pianta, 2002; Autant-Bernard y LeSage 2019); pero si lo que se pretende es evaluar la producción del conocimiento en una región, las patentes son variable output (Fritsch y Slavtchev, 2011). Ahora bien, dada la maleabilidad del marco de los SRI, las variables son interpretadas de diversas maneras. Por citar algunas, se tiene el caso de la variable educación, que en algunos trabajos es proxy de la capacidad de adsorción o de aprendizaje (Strauf y Scherer, 2008), de filtro social, como señal de atracción de la inversión extranjera o localización empresarial (Lewin y Massini, 2004), o determinante del nivel de desarrollo económico (Rodríguez-Pose y Tselios, 2007).
En el plano empírico, recurrir a un gran número de variables usadas para describir la complejidad de los SRI enfrenta la dificultad de la dispersión, la consecución y la ausencia de datos (Arancegui et al., 2011); lo que hace que las investigaciones realizadas, aun para un mismo conjunto de regiones, no lleguen a resultados equivalentes (Grupp y Mogee, 2004).
La flexibilidad en el uso del SRI es posible gracias a que este es un marco analítico más que una teoría (Uyarra y Flanagan, 2010); hecho que permite realizar investigaciones en las que el uso de una variable en un determinado factor o en otro obedece a la formación e interés del investigador, a la clase y objetivos del estudio y, como es lógico, a la disponibilidad de la información (Grupp y Mogee, 2004). Pero esta flexibilidad hace del concepto de SRI un marco confuso (Markusen, 2003).
Esta confusión proviene de la posible evaluación del concepto mediante distintas variables y que, a su vez, un factor lo componen variables que pueden estar incluidas en distintos factores a juicio del investigador. Este hecho genera una especie de entropía conceptual, debido a que se vuelve incierta la relación entre el concepto de un componente del sistema, la dimensión que lo representa, el factor o conjunto de variables que lo miden y los datos que describen los hechos empíricos que dan cuenta del fenómeno que pretende explicar (Rigdon, 2016).
Esta variedad de trabajos en la literatura reciente ha llevado a que se planteen investigaciones en las que se evalúe la heterogeneidad de los coeficientes en las FPC y en las que se utilicen distintas variables para evaluar las diferentes clases de regiones según su intensidad innovadora (Autant-Bernard y LeSage, 2019). Por otro lado, Neves-Sequeira y Cunha-Neves (2020) plantean que en la literatura sobre FPC se identifican al menos cuatro ramas: la primera se distingue por medir la dispersión en generación de conocimiento regional usando los gastos de investigación y desarrollo (I+D); la segunda se basa en la innovación de las empresas usando variables dicotómicas; la tercera parte del modelo de Aghion y Howitt, en el cual se mide la tasa de probabilidad de innovación, y, finalmente, la cuarta se distingue por medir el conocimiento usando la función de producción de Romer (1990).
Esta investigación se inscribe en la cuarta rama y avanza considerando como constructo la combinación de patentes, publicaciones y servicios intensivos en conocimiento como proxy del conocimiento producido en una región. La finalidad de este documento es plantear una propuesta de modelación basada en variables latentes como alternativa metodológica a la construcción de la FPC en un espacio geográfico.
2.1. Propuesta de una FPC basada en variables latentes
En el marco de la producción del conocimiento y su relación con el espacio, en el año 2005, se formuló el proyecto Eurodite, a partir del cual se acuñó el concepto de dinámica territorial del conocimiento (TKDs, por sus siglas en inglés de territorial knowledge dynamics), con el que se pretende encontrar la forma en que el conocimiento se produce en un territorio en contexto de globalización (Jeannerat y Crevoisier, 2016). Otro esfuerzo similar se halla en el proyecto Espacios de Conocimiento iniciado en Alemania desde el 2006; aquí se persigue analizar el proceso de producción, distribución espacial, aplicación y las disparidades territoriales en la disponibilidad del conocimiento (Meusburger, 2013).
La presente investigación se enmarca en estos esfuerzos, cuyo común denominador es encontrar nuevos conceptos y formas para medir la producción del conocimiento en los territorios. Se avanza en el planteamiento de una FPC basa-da en constructos. Esta postura teórica se justifica en que el conocimiento es un concepto amplio, con el que se describen muchos sucesos y características de un sujeto (Johnson et al., 2002), en este caso regiones (Meusburger, 2013). Para situaciones donde la ciencia tropieza con estas dificultades, el uso de constructos es una alternativa teórica adecuada (Kerlinger y Lee, 2002; Rigdon, 2016).
Si bien una variable latente es un indicador compuesto como los usados tradicionalmente, al verificarse como constructo, tiene que cumplir con tres propiedades: que tenga validez de contenido o descripción de un fenómeno, que permita medir lo que describe y que sea estadísticamente confiable (Kerlinger y Lee, 2002). La novedad de la presente investigación radica entonces en que a las variables latentes propuestas se les obliga a pasar las pruebas de estas propiedades; en este caso, representar, medir y dar fiabilidad a las propiedades del conocimiento y su producción en el espacio geográfico.
Este documento parte de la idea de que el conocimiento se concibe como el conjunto de saberes, destrezas y habilidades que resultan de la relación entre la experiencia del sujeto y la información del medio circundante (Meusburger, 2013). En un espacio geográfico, el conocimiento está presente en los sucesos, rutinas, habilidades, acciones, etc. (Capello y Lenzi, 2013). De ahí que para capturar el conocimiento es más procedente formular constructos que variables observables (Kerlinger y Lee, 2002).
Asheim et al. (2011), Scuotto, Del Giudice, Bresciani y Meissner (2017) plantean que, en una región, el producto del conocimiento se evidencia de manera analítica en las ciencias, sintética en las ingenierías y simbólica en las artes. Bajo esta premisa, se plantea como variable latente dependiente en la FPC la producción del conocimiento PRC, siguiendo la tradición de Griliches (1979). Este constructo está compuesto por tres variables manifiestas: las solicitudes de patentes; las publicaciones científicas, que suelen ser las más usadas (Michie et al., 2002); y a estas se les agrega las solicitudes de patentes en TIC, para resaltar la importancia de esta tecnología en los últimos años (Buesa et al., 2010; Arancegui et al., 2011). De igual manera, la PRC aquí planteada se determina por cuatro constructos: el de los recursos humanos (HUM); los gastos en I+D (GID); el de SP; y el de entorno innovador (EIN). Cada uno de los anteriores recoge al menos una de las propiedades del conocimiento.
En este trabajo se asume que el constructo HUM describe la propiedad del conocimiento como tácito y explícito; a la vez como saber de los individuos (Johnson et al., 2002; Cowan, David y Foray, 2000). El conocimiento implica saber el qué, el cómo, el por qué y saber quién sabe qué de los fenómenos naturales y sociales (Johnson et al., 2002; Karlsson et al., 2014). Cada una de las categorías de saberes representa el nivel educativo de la región que está en su base del crecimiento endógeno (Romer, 1990).
A partir de la categoría de saberes, se derivan las variables manifiestas que componen el constructo de HUM. Como proxy del saber qué, el nivel más básico del conocimiento, se toma a los matriculados en educación secundaria; los trabajos de Rodríguez-Pose (2013) usan esta variable como filtro social, o el mínimo básico de una región para competir. Por su parte, el saber cómo y el porqué, que en esencia implican un mayor nivel de conocimiento, se representan con el número de matriculados en educación superior (Crescenzi y Rodríguez-Pose, 2011). Finalmente, el saber quién sabe qué, lo cual implica redes (Strambach y Klement, 2011), se mide mediante el personal dedicado a las actividades de I+D.
El segundo constructo determinante de la PRC son los GID, que son fundamentales en el crecimiento endógeno (Romer, 1990; OCDE, 2018). A través de esta variable latente, se captura la propiedad del conocimiento como un bien privado y de parcial exclusión en el corto plazo; y de no rival en el largo plazo (Romer, 1990). Con este constructo también se trata de capturar la capacidad de absorción de una región, que se describe como los esfuerzos o asignación de recursos para la formación, aprendizaje y emprendimiento de las actividades propias de la innovación (Cohen y Levinthal; 1990).
Partiendo de estas ideas, se propone que el GID lo componen tres indicadores: i) los gastos en investigación de las empresas y el esfuerzo innovador en investigación aplicada; ii) los gastos en investigación del sector público fundamentalmente en investigación básica, y iii) los gastos de las universidades en investigación y desarrollo. Estos indicadores juntos constituyen el apalancamiento de las actividades que están detrás de la producción del conocimiento (Romer, 1990) y en el crecimiento regional (OCDE, 2018).
El tercer determinante de la PRC son los SP. Con este constructo se describe el conjunto de efectos secundarios que surge cuando el conocimiento científico o tecnológico creado por un agente desborda o rebosa sus límites, pasando a ser de dominio público y utilizado por terceros, por poca o ninguna retribución (Jaffe, Trajtenberg y Henderson, 1993; Audretsch, Lehmann, Menter y Seitz, 2019). En la literatura se afirma que los SP son básicamente flujos de conocimiento que provienen de las patentes, las publicaciones, los educa-dos a nivel superior, los servicios y el personal dedicado a las actividades de I+D (Jaffe et al., 1993; Audretsch et al., 2019; Crescenzi y Rodríguez-Pose 2011; Rodríguez-Pose, 2013).
Audretsch et al. (2019) han resaltado que las empresas son las que más se benefician de los SP en cualquiera de sus manifestaciones. Pero en el marco de crecimiento endógeno, las empresas tienen que realizar esfuerzos, es decir, incrementar el GID para aprovechar los SP (Karlsson et al., 2014). Bajo las anteriores premisas, este documento plantea que el constructo SP representa o describe el desbordamiento del conocimiento que es capaz de capturar cada empresa.
Para medir los SP en una región, se tomó el GID total, se relacionó con los distintos flujos de conocimiento y se dividió por el número de empresas localizadas en el territorio. Así concebido, el constructo de SP está constituido por cinco variables, que describen efectos secundarios de los SP: i) la de derivados de las patentes, ii) las publicaciones, iii) la asociada con la educación superior, iv) la del personal en actividades de investigación y v) la de los derivados de los servicios intensivos en conocimiento.
El cuarto constructo determinante de la FPC es el EIN, o los milieux innovateurs, desarrollado por el Grupo Europeo de Investigación en Entornos Innovadores (GREMI, por sus siglas en francés). Con este término se describe el conjunto de condiciones de un territorio, que facilitan, impulsan y permiten que se renueve la producción y la innovación (Aydalot, 1986; Bramanti, 1999; Capello y Lenzi, 2013).
Bramanti (1999), en una revisión de literatura, plantea que el EIN es un proceso de enfoque relacional en el que el territorio es el producto de la innovación, el aprendizaje, las redes y la gobernanza. Más recientemente, a los EIN se les ha agregado el ambiente y sostenibilidad como quinto elemento (Kasmi, 2018).
Además de los anteriores cinco elementos, en este trabajo, el EIN es un constructo que captura la cantidad del conocimiento explícito contenido y codificado en libros y medios magnéticos (Johnson et al., 2002), así como el conocimiento tácito contenido en las habilidades de las personas e incorporado en la cultura y rutina de las organizaciones (Cowan et al., 2000), el conjunto de canales o conductos por donde circula el conocimiento (Maskell, Bathelt y Malmberg, 2006), la historia y el aprendizaje de las organizaciones (Strambach y Klement, 2011), las condiciones que facilitan las relaciones cara a cara (Storper y Venables, 2004) y, por último, el conjunto de proximidades que permiten que el conocimiento se arraigue (Balland et al., 2014).
El constructo del EIN está compuesto por todo el conjunto de recursos y capacidades contenidos en el territorio (Bathelt y Glückler, 2005; Kasmi, 2018). Entran en esta categoría: el personal educado en todos los niveles, las empresas, las patentes, las publicaciones, los recursos financieros dedicados a la investigación, las viviendas y demás elementos que suelen intervenir en la producción, calidad de vida e innovación y sostenibilidad (Aydalot, 1986; Kasmi, 2018).
Teniendo en cuenta los constructos planteados, la FPC se define por la siguiente ecuación: PRC=f\left(HUM\ GID,EIN,SP\right). La estructura de la FPC (figura 1) se construye como un diagrama de flujo, en el que se especifica a través de cada ruta (dirección de flechas) que los cuatro factores determinantes, GID, HUM, SP, EIN, afectan de manera directa la PRC científico y tecnológico.
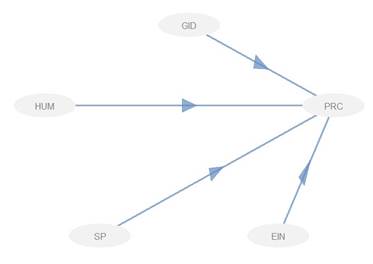
La figura 1 permite plantear las hipótesis de la presente investigación, donde la H1 pretende mostrar que cada uno de los constructos son unidimensionales fiables y confiables, esto es, representan bien las propiedades del conocimiento y su relación con el espacio geográfico. La segunda hipótesis, H2, defiende la idea de que existe una relación directa y significativa entre la PRC con HUM GID, SP y EIN.
3. Metodología
En este apartado se describe la obtención de la muestra, la construcción de las variables y la aplicación de la técnica para la contrastación de las hipótesis.
3.1. Selección de la muestra y tratamiento de la información
En este trabajo se tomaron como regiones objeto de la muestra aquellas que cumplieron con las siguientes condiciones: que fueran calificadas como Nivel Territorial 2 (TL2 por sus siglas en inglés) por la OCDE o Nomenclatura de unidades territoriales estadísticas 2 (NUT2 por sus siglas en francés) por la Unión Europea. A la vez que estuviesen calificadas y evaluadas por el Índice de Competitividad del Conocimiento Mundial (WKCI por sus siglas en inglés) (Huggins y Izushi, 2008), por el Banco Interamericano de Desarrollo (BID) y por la Comisión Económica para América Latina (CEPAL) como regiones importantes por su conocimiento.
Para identificar las regiones, se construyó una matriz de coincidencias, las cuales se evidencian en la tabla 1, tomando como referencia los reportes del WKCI, estudios de la CEPAL, del BID e informes de la OCDE. Se aceptó como región objeto de estudio aquella que estuviera en tres de los reportes.
Tabla 1 Muestra de las principales regiones globales basadas en el conocimiento en el mundo con base en las TL2 de la OCDE.
| Fuentes de información | Regiones ganadoras identificadas | Regiones clasificadas | Resultado de la matriz de coincidencias | Número de regiones que coinciden |
|---|---|---|---|---|
| WKCI | 145 | 108 | WKCI/GAWC/OCDE | 108 |
| GAWC | 298 | 116 | BID/CEPAL/OCDE | 32 |
| OCDE | 23 | 23 | ||
| CEPAL | 182 | 32 | ||
| BID | 9 | 9 | ||
| Total | 514 | 288 | Total | 140 |
Nota: de las regiones clasificadas en WKCI, GAWC y OCDE, se incorporan 108 en el presente estudio; mientras que, de la OCDE, CEPAL y el BID se incorporan 32 regiones, principalmente las latinoamericanas.
Fuente: elaboración propia
La tabla 1 muestra que 140 territorios califican como objeto de análisis, de los cuales 108 coinciden en los listados del WKCI, el Índice de Globalización y Ciudades Mundiales (GAWC, por sus siglas en inglés) y la OCDE; aquí entran las regiones más competitivas del mundo y 32 aparecen en los listados de OCDE, BID, GAWC y CEPAL.
Del total de 140 regiones que califican como competitivas en la economía del conocimiento, se descaron tres, debido a la falta de datos. Las 137 regiones se localizan en 38 países. El tipo de regiones objeto de análisis son de las más representativas del mundo, como California, Londres, Nueva York, Shanghái; siendo Alemania y Estados Unidos los países que cuentan con mayor número de regiones incluidas en la muestra, 10 y 30, respectivamente. Se tomó como periodo de análisis de la información datos para las variables de entrada o exógenas para el año 2010 y los indicadores de resultados que miden la PRC para el año 2012. Esta diferencia de tiempo se justifica en el hecho de que las variables input en la innovación tienen un efecto retardo en las variables output (Fritsch y Slavtchev, 2011). Igualmente, se tomaron estos dos periodos ya que al momento de construir la investigación existía la mayor cantidad de datos posibles para todas las regiones, más de un 98%.
3.2. Tratamiento de las variables
Para algunas de las regiones de China y Latinoamérica faltaron datos, sobre todo en aquellas variables relacionadas con las patentes; por lo que, para obtener los datos faltantes, estos fueron estimados utilizando el método de imputación múltiple de regresión, a través del programa SPSS versión 22. En promedio, para cada una de las variables obtenidas se imputaron dos regiones, equivalente al 1,46%. Cuando se imputan variables suele hacerse análisis de sensibilidad para comparar los resultados con y sin imputación, pero, dado que es un número tan bajo de datos imputados para cada variable, no se hace necesario este paso (Saltelli, Tarantola, Campolongo y Ratto, 2004).
En la exploración de datos, se encontró que había datos atípicos; por ejemplo, en el caso de la variable observable número de solicitud de patentes, como es apenas lógico, dado el tipo de regiones de la muestra, existen algunas por encima de la media como las alemanas, japonesas y norteamericanas; y otras muy alejadas como las colombianas y la gran mayoría de las latinoamericanas. Con el fin de reducir la desviación, se aplicaron transformaciones algebraicas a las variables. En efecto, 9 de las 26 variables fueron transformadas.
Para capturar el hecho de que en la muestra existen regiones de diferente nivel de desarrollo, se realizó un proceso de ajuste a los constructos de SP y EIN, debido a que son solo comparables entre regiones similares en etapa de desarrollo y renta per cápita. Este ajuste se realizó tomando la clasificación que hace la OCDE (2012) de los países y regiones en tres niveles: los países altamente innovadores, los eficientes en los recursos y los que se basan en recursos naturales o requerimientos básicos; y aquellos países que se encuentran en situación intermedia en cada uno de los niveles.
Tomando estos niveles como referencia para establecer los constructos de SP y EIN, se les sumó, a los valores de la variable latente, 1 a las regiones de menor nivel de desarrollo, 2 a las siguientes, 3 y 4 a las de mayor desarrollo y renta per cápita, con lo que se buscó que dichas variables capturaran la diferencia en nivel de desarrollo. El proceso de construcción de las variables se recoge en la tabla A1 de los anexos, en donde la primera columna muestra los cinco bloques teóricos que describen los componentes con los que se construye FPC, EIN, HUM, SP, PRC y GID. En la segunda columna se muestran los indicadores o variables observables que componen cada variable latente. De la columna tercera a la séptima se muestra el tratamiento al que fue sometida cada variable observable para construir el modelo.
3.3. Estimación de los constructos y estructura de la FPC mediante la técnica de PLS
Para lograr el cometido de una propuesta de FPC con constructos que superen pruebas de representatividad, fiabilidad y operatividad, en este trabajo se utiliza la técnica PLS Path Modeling, cuyo objetivo es predecir haciendo mínimas las varianzas residuales (Wold, 1975). Los trabajos que se construyen con indicadores compuestos carecen de normalidad multivariante (Arancegui et al., 2011) y este trabajo no escapa a este impase. Por tal razón, se usó la técnica de PLS, pues a partir de ella se puede obtener estimadores fiables bajo otras clases de distribución de los datos (Wold, 1975; Tubadji y Pelzel, 2015).
La presente propuesta, al igual que todas las de esta clase, enfrenta la dificultad de que proviene de un marco referencial como el de los SRI (Markusen, 2003). La técnica PLS-PM es flexible en cuestiones de especificación, debido a que es más exploratoria que confirmatoria (Henseler, Ringle y Sinkovics, 2009; Tubadji y Pelzel, 2015), por lo que es muy útil en este trabajo, debido a que esta investigación es exploratoria.
La otra dificultad que enfrenta este trabajo es que el tamaño de la muestra de 137 regiones no es suficiente para validar constructos mediante ecuaciones estructurales basadas en covarianzas. Por esta razón, se utiliza la PLS, debido a que las estimaciones no se condicionan al tamaño mínimo de muestra, puede ser suficiente con un número reducido de casos (Wold, 1975). Aunque existen discusiones sobre este punto (Rigdon, 2016), se recomienda que por variable observable haya como mínimo 10 casos en el constructo de mayor número de variables (Henseler et al., 2009). En este trabajo, el constructo de EIN tiene 12 variables y los casos son 137, con un promedio de 11 casos por variable; por lo que se cumple la condición de tamaño de muestra mínimo y se justifica el uso de la técnica (Henseler et al., 2009).
Los trabajos del SRI buscan comparar regiones; la virtud de esta técnica es que permite puntuaciones de las variables latentes o construidas que pueden ser utilizadas para otro tipo de mediciones (Tubadji y Pelzel, 2015), como el análisis de clústeres entre otras. Lo que ayudaría a realizar comparaciones y construir índices compuestos; además, al estar soportados por una FPC, se podrá obtener la jerarquía entre regiones y el porqué de esta discriminación.
Justificadas las razones del uso de la técnica, se procedió a estimar la FPC. El proceso se realizó en dos etapas: primero, se calculó el modelo de medida u outer model y se validó la calidad de cada uno de los constructos, dado que se estiman las relaciones entre del constructo y las variables observables, y, segundo, se obtuvo el modelo estructural o inner model, donde se explica únicamente las relaciones entre las variables latentes, es decir, se calculó la estructura de la FPC.
3.3.1. Obtención de los constructos mediante el modelo de medida: indicadores reflectivos
Un aspecto clave de esta investigación es verificar la validez unidimensional de los constructos, es decir, si las variables observables pertenecen y describen el fenómeno que representan. Este proceso se realizó mediante la utilización del modelo de medida o el outer model. Rigdon (2016), Henceler et al. (2009) y Wold (1975) plantean que un constructo está bien formulado cuando supera las pruebas de confiabilidad individual de los ítems, la fiabilidad del constructo o unidimensionalidad, la validez convergente y la validez discriminante. En este sentido, la tabla 2 presenta el resumen del modelo de medida, resultados obtenidos mediante el ajuste del modelo general utilizando el software estadístico R versión 3.1.2 (R Core Development Team, 2014) con la librería PLS-PM (Sanchez, Trinchera y Russolillo, 2013), que tiene implementados los algoritmos de estimación de los parámetros del modelo.
Tabla 2 Resumen modelo medida
| Constructo Indicadores | Pesos | Cargas | Comunalidades | Alpha de Cronbach | Fiabilidad compuesta | Primer valor propio | Varianza extraída media (AVE) |
|---|---|---|---|---|---|---|---|
| GID | 0,854 | 0,932 | 1,746 | 0,872 | |||
| LN.GIDP.ID | 0,4985 | 0,9247 | 0,855 | ||||
| GIDEP.ID | 0,5715 | 0,9432 | 0,8897 | ||||
| HUM | 0,788 | 0,904 | 1,651 | 0,693 | |||
| LN.MATER | -0,0496 | 0,6218 | 0,3866 | ||||
| LN.EMPID | 1,0316 | 0,9993 | 0,9986 | ||||
| SP | 1 | 1 | 4,999 | 1 | |||
| DEREDUSUP | 0,2 | 0,9999 | 0,9999 | ||||
| DERPAT | 0,2001 | 1 | 1 | ||||
| DERGRAPUB | 0,2004 | 0,9999 | 0,9998 | ||||
| DERSER | 0,1998 | 0,9999 | 0,9998 | ||||
| DERPEROCUID | 0,1997 | 1 | 0,9999 | ||||
| EIN | 1 | 1 | 11,975 | 0,998 | |||
| GIDP.S | 0,083 | 0,9996 | 0,9993 | ||||
| VVD.S | 0,0835 | 0,9987 | 0,9974 | ||||
| ESTU.S | 0,0827 | 0,9992 | 0,9985 | ||||
| ESMACO.S | 0,0835 | 0,9997 | 0,9994 | ||||
| PARVE.S | 0,0834 | 0,999 | 0,998 | ||||
| DEPO.S | 0,0845 | 0,994 | 0,9881 | ||||
| INMEXT.S | 0,0824 | 0,9991 | 0,9981 | ||||
| SPATPCT.S | 0,084 | 0,9994 | 0,9989 | ||||
| PUBT.S | 0,0839 | 0,9997 | 0,9994 | ||||
| ABINBA.S | 0,0832 | 0,9994 | 0,9988 | ||||
| ABTECE.S | 0,0831 | 0,9997 | 0,9994 | ||||
| LITE.S | 0,0838 | 0,9998 | 0,9996 | ||||
| PRC | 0,845 | 0,909 | 2,314 | 0,771 | |||
| S.SPATPCT | 0,4523 | 0,9605 | 0,9226 | ||||
| S.PUBT | 0,2698 | 0,6981 | 0,4874 | ||||
| S.SPATPCT_TICS | 0,3972 | 0,9496 | 0,9018 |
Fuente: elaboración propia.
A partir del análisis del modelo de medida, a través de un proceso de prueba y error, se dejaron 24 de 26 variables observables para el ajuste definitivo. Se eliminaron los indicadores GID realizados por el sector de la educación superior del constructo GID, y el total matriculados en el nivel secundario correspondiente al bloque HUM, debido a que presentaron cargas factoriales por debajo de 0,2 y no añaden un valor significativo al modelo. Como se observa en la tabla 2, los indicadores reflectivos sobrepasan los valores mínimos (cargas mayores a 0,7), referidos a las cargas, y por ende a las comunalidades, a excepción de los indicadores logaritmo natural de matriculados en educación terciaria (LN.MATER) y spillovers de las publicaciones (S.PUBT), cuyas cargas factoriales oscilan entre 0,62 y 0,7; estos se conservaron porque se aproximan al valor mínimo tolerable. De aquí que se supera la prueba de la fiabilidad del ítem.
En cuanto a la unidimensionalidad y consistencia del constructo, como se muestra en la tabla 2, todos los bloques sobrepasan los valores mínimos. Esto se evidencia en la fiabilidad del constructo referido a los índices alfa de Cronbach y fiabilidad compuesta; presenta valores por encima de 0,7 respectivamente y mayor que 1, correspondiente al primer valor propio de la matriz de correlaciones de las variables latentes, lo que indica la validación de la consistencia interna y la unidimensionalidad de cada concepto teórico. En consecuencia, los distintos indicadores están relacionados significativamente con una y solo una dimensión o variable latente. Como se observa en la tabla 2, se aprueba la validez convergente, dado que los valores de varianza media extraída (AVE) de cada constructo son mayores a 0,6. Lo que significa que más del 60% de la varianza de cada constructo se debe a sus indicadores.
El último paso para validar los constructos propuestos es constatar la validez discriminante, para ello se ilustran los datos en la tabla 3. Con este criterio se buscó comprobar en qué medida un constructo es diferente de otros. En la tabla 3 se muestra que en efecto la varianza que cada constructo comparte con sus indicadores (AVE) es mayor que la que comparte con otros constructos incluidos en el modelo. Por tanto, se prueba que los constructos tienen validez discriminante, dado que la AVE de cada constructo es mayor que las variaciones comunes, es decir, la correlación al cuadrado entre el constructo y las demás variables latentes del modelo.
Tabla 3 Correlaciones de variables latentes.
| GID | HUM | SP | EIN | PRC | |
|---|---|---|---|---|---|
| GID | 0,934 | ||||
| HUM | 0,528 | 0,832 | |||
| SP | 0,403 | 0,507 | 1 | ||
| EIN | 0,442 | 0,336 | 0,506 | 1 | |
| PRC | 0,579 | 0,517 | 0,566 | 0,659 | 0,878 |
Fuente: elaboración propia.
En la tabla 3 se observa que los coeficientes de correlación de Pearson entre cada variable latente y el resto son menores a la raíz cuadrada de la AVE de cada constructo (valores incluidos en la diagonal de la matriz), cumpliéndose así la validez discriminante. Otra forma de evaluar la validez discriminante es mediante las cargas cruzadas. Es decir, las correlaciones entre las puntuaciones de un constructo y el resto de indicadores. En efecto, las correlaciones entre las puntuaciones de una variable latente y sus propios ítems son las cargas factoriales, mientras que las correlaciones entre las puntuaciones de un constructo y los indicadores que pertenecen a otros constructos corresponden a las cargas cruzadas (Revuelta, Mulero y García, 2009). Bajo estas implicaciones, la tabla 4 muestra que los indicadores cargan más en sus respectivos constructos que en otros a los que no pertenecen y mediante este resultado se confirma la validez discriminante.
Como se puede observar en la tabla 4, los conceptos teóricos están medidos correctamente y, por ende, se tienen medidas válidas y fiables. Cada variable latente mide lo que pretende medir y las variables manifiestas son las que se corresponden en cada constructo.
Tabla 4 Cargas cruzadas
| GID | HUM | SP | EIN | PRC | ||
|---|---|---|---|---|---|---|
| GID | ||||||
| 1 | LN.GIDP.ID2010 | 0,925 | 0,412 | 0,409 | 0,454 | 0,502 |
| 1 | GIDEP.ID2010 | 0,943 | 0,564 | 0,348 | 0,377 | 0,575 |
| HUM | ||||||
| 2 | LN.MATER2010 | 0,167 | 0,622 | 0,017 | -0,132 | -0,024 |
| 2 | LN.EMPID2010 | 0,519 | 0,999 | 0,493 | 0,319 | 0,501 |
| SP | ||||||
| 3 | DEREDUSUPPIBP2010 | 0,405 | 0,511 | 1 | 0,505 | 0,566 |
| 3 | DERPATPIBP2010 | 0,403 | 0,506 | 1 | 0,506 | 0,566 |
| 3 | DERGRAPUBPIBP2010 | 0,402 | 0,508 | 1 | 0,505 | 0,567 |
| 3 | DERSERPIBP2010 | 0,402 | 0,504 | 1 | 0,507 | 0,565 |
| 3 | DERPEROCUIDPIBP2010 | 0,403 | 0,508 | 1 | 0,505 | 0,565 |
| EIN | ||||||
| 4 | GIDP.S.PINST2010 | 0,441 | 0,336 | 0,503 | 1 | 0,655 |
| 4 | VVD.S.PINST2010 | 0,436 | 0,333 | 0,513 | 0,999 | 0,659 |
| 4 | ESTU.S.PINST2010 | 0,445 | 0,336 | 0,498 | 0,999 | 0,653 |
| 4 | ESMACO.S.PINST2010 | 0,447 | 0,337 | 0,502 | 1 | 0,659 |
| 4 | PARVE.S.PINST2010 | 0,444 | 0,336 | 0,511 | 0,999 | 0,658 |
| 4 | DEPO.PINST2010 | 0,426 | 0,331 | 0,516 | 0,994 | 0,666 |
| 4 | INMEXT.S.PINST2010 | 0,44 | 0,331 | 0,496 | 0,999 | 0,65 |
| 4 | SPATPCT.S.PINST2010 | 0,446 | 0,337 | 0,503 | 0,999 | 0,663 |
| 4 | PUBT.S.PINST2010 | 0,441 | 0,336 | 0,512 | 1 | 0,662 |
| 4 | ABINBA.S.PINST2010 | 0,446 | 0,336 | 0,5 | 0,999 | 0,656 |
| 4 | ABTECE.S.PINST2010 | 0,445 | 0,336 | 0,501 | 1 | 0,655 |
| 4 | LITE.S.PINST2010 | 0,439 | 0,338 | 0,508 | 1 | 0,661 |
| PRC | ||||||
| 5 | S.SPATPCT2012 | 0,632 | 0,56 | 0,551 | 0,67 | 0,961 |
| 5 | S.PUBT2012 | 0,286 | 0,205 | 0,483 | 0,465 | 0,698 |
| 5 | S.SPATPCT_TICS2012 | 0,543 | 0,526 | 0,469 | 0,58 | 0,95 |
Fuente: elaboración propia.
3.3.2. Evaluación del modelo estructural
Una vez comprobado que los conceptos teóricos están medidos correctamente y, por tanto, se tienen medidas válidas y fiables, se procede a la evaluación del modelo estructural, con el fin de extraer conclusiones referentes a las relaciones entre los constructos.
La evaluación de la calidad del inner model, similar que en un modelo de regresión múltiple, se llevó a cabo mediante el examen de dos índices fundamentales (Götz, Liehr-Gobbers y Krafft, 2010): el coeficiente de determinación R2 de la variable latente endógena, que indica la cantidad de varianza del constructo explicada por el modelo, y los coeficientes Path (β), que miden el peso y dirección de cada camino o relación entre variables latentes.
Mediante la evaluación del modelo estructural se aportó evidencia sobre cómo los componentes del sistema resultan más decisivos como impulsores de la innovación. En la figura 3 se expone el gráfico de rutas con las correspondientes estimaciones de los coeficientes Path o pesos de regresión. Estos trayectos se identifican por medio de las flechas que vinculan a los constructos en el modelo interno. En este sentido, se obtiene un solo coeficiente de determinación aproximado de 0,6, correspondiente a la variable latente endógena PRC, que bajo las normas PLS-PM (Rigdon, 2016) indica una alta cantidad de varianza del constructo explicada por el modelo.
No obstante, los datos de los regresores tienen que cumplir los supuestos de las regresiones lineales. Previo a la interpretación exhaustiva de las salidas correspondientes al modelo estructural, se hizo necesario probar los supuestos asociados a la regresión múltiple con el fin de lograr estimaciones óptimas de los coeficientes Path. Para tal efecto, se utilizaron las puntuaciones de cada constructo obtenidas mediante PLS, y así ejecutar el modelo de regresión por mínimos cuadrados ordinarios.
De este modo, se obtuvo de nuevo el ajuste del inner model por separado, además de los residuales, insumos necesarios para realizar las pruebas estadísticas. De acuerdo con esto, se presentan de manera resumida los resultados correspondientes a las pruebas estadísticas llevadas a cabo en el software R versión 3.1.2 (R Core Development Team, 2014).
Con el objeto de detectar posible multicolinealidad, se presenta en la tabla 5 los factores de inflación de la varianza (VIF, por sus siglas en inglés). De acuerdo con los VIF obtenidos por cada variable latente exógena, no existen problemas de colinealidad y las estimaciones son válidas.
Tabla 5 Factores de inflación de la varianza
| GID | HUM | SP | EIN |
|---|---|---|---|
| 1,560922 | 1,619019 | 1,628982 | 1,478427 |
Fuente: elaboración propia.
Mediante las demás pruebas llevadas a cabo, se validaron los supuestos de homogeneidad de varianza y distribución normal de los residuos, a través de las pruebas Breusch Pagan y Lilliefors (Kolmogorov-Smirnov), respectivamente, a un nivel de significancia del 1%. Mientras que el supuesto de incorrelación de los errores no se cumplió, posiblemente por la recolección de los datos en el tiempo. El incumplimiento de la no correlación de los errores, conservándose todos los demás supuestos, aunque origina estimaciones lineales insesgadas, no garantiza eficiencia, es decir, mínima varianza. No obstante, es de notar, en la tabla 6, los bajos errores estándar que resultan de las estimaciones de cada coeficiente Path, compensando un poco este hecho. Una vez probados los supuestos inherentes en la regresión lineal, se vuelve la mirada a los resultados obtenidos en el modelo estructural, presentados en la figura 2 y en la tabla 6.
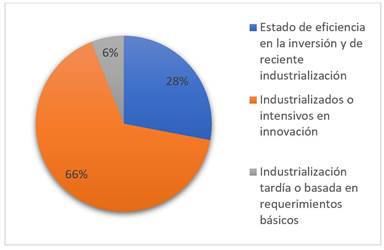
Tabla 6 Resultados inner model
| Estimadores | Error estándar | t valor | Pr(>|t|) | |
|---|---|---|---|---|
| GID → PRC | 0,241 | 0,0693 | 3,47 | 0,0007 |
| HUM → PRC | 0,162 | 0,0706 | 2,3 | 0,0232 |
| SP → PRC | 0,181 | 0,0708 | 2,56 | 0,0116 |
| EIN → PRC | 0,406 | 0,0675 | 6,02 | 1,5900E-08 |
| R2 | 0,594 | Redundancia promedio | 0,457 |
Fuente: elaboración propia.
Al comparar estas evidencias, se destaca que todos los factores tienen un efecto positivo estadísticamente significativo sobre la PRC, puesto que los valores p son menores a un nivel de significancia del 5%. Sin embargo, es de resaltar que tanto el EIN como el GID presentan mayores influencias sobre la innovación regional en contraste con los demás determinantes.
Por otra parte, respecto a la redundancia promedio correspondiente a la PRC esta indica que los constructos exógenos predicen o explican el 45,7% de la variabilidad de los indicadores de la producción científica y tecnológica. Además, se obtiene un valor del índice Götz de 0,7445, lo que indica un buen ajuste del modelo global y por ende una buena capacidad de predicción.
Para finalizar la evaluación del modelo de ecuaciones estructurales, se procede a examinar los resultados correspondientes al proceso de remuestreo (bootstrap), con el fin de estudiar la estabilidad y precisión de los parámetros. En la tabla 7 se presenta una matriz con cinco columnas: 1) el valor original de cada parámetro; 2) el valor promedio del remuestreo; 3) el error estándar; 4) el percentil inferior y 5) el percentil superior del intervalo de 95% de confianza. Es de notar que los valores originales de los parámetros, cargas, coeficientes Path y el coeficiente de determinación se encuentran dentro del intervalo de confianza, lo que indica estabilidad y precisión de cada parámetro en el modelo ajustado.
Tabla 7 Resultados bootstrap
| Cargas (λ) | Original | Medida de arranque | Error estándar | Percentil 25% | Percentil 97,5 |
|---|---|---|---|---|---|
| LN.GIDP.ID | 0,925 | 0,926 | 0,0152 | 0,894 | 0,952 |
| GIDEP.ID | 0,943 | 0,944 | 0,0103 | 0,922 | 0,96 |
| LN.MATER | 0,622 | 0,556 | 0,202 | 0,108 | 0,817 |
| LN.EMPID | 0,999 | 0,958 | 0,192 | 0,855 | 1 |
| DEREDUSUPPIBP | 1 | 1 | 0,0000371 | 1 | 1 |
| DERPATPIBP | 1 | 1 | 0,00000516 | 1 | 1 |
| DERGRAPUBPIBP | 1 | 1 | 0,0000684 | 1 | 1 |
| DERSERPIBP | 1 | 1 | 0,0000269 | 1 | 1 |
| DERPEROCUIDPIBP | 1 | 1 | 0,0000332 | 1 | 1 |
| GIDP.S.PINST | 1 | 0,000122 | 0,999 | 1 | |
| VVD.S.PINST | 0,999 | 0,999 | 0,00114 | 0,996 | 1 |
| ESTU.S.PINST | 0,999 | 0,999 | 0,000269 | 0,999 | 1 |
| ESMACO.S.PINST | 1 | 1 | 0,0000807 | 1 | 1 |
| PARVE.S.PINST | 0,999 | 0,999 | 0,00052 | 0,998 | 1 |
| DEPO.PINST | 0,994 | 0,994 | 0,00167 | 0,991 | 0,997 |
| INMEXT.S.PINST | 0,999 | 0,999 | 0,000263 | 0,999 | 1 |
| SPATPCT.S.PINST | 0,999 | 0,999 | 0,000237 | 0,999 | 1 |
| PUBT.S.PINST | 1 | 1 | 0,000116 | 0,999 | 1 |
| ABINBA.S.PINST | 0,999 | 0,999 | 0,000199 | 0,999 | 1 |
| ABTECE.S.PINST | 1 | 1 | 0,00011 | 0,999 | 1 |
| LITE.S.PINST | 1 | 1 | 0,0000798 | 1 | 1 |
| S.SPATPCT | 0,961 | 0,961 | 0,00498 | 0,951 | 0,97 |
| S.PUBT | 0,698 | 0,713 | 0,0711 | 0,561 | 0,819 |
| S.SPATPCT_TICS | 0,95 | 0,951 | 0,00731 | 0,937 | 0,965 |
| Coeficientes (β) | |||||
| GID → PRC | 0,241 | 0,22 | 0,0674 | 0,0838 | 0,352 |
| HUM → PRC | 0,162 | 0,166 | 0,0841 | 0,0167 | 0,297 |
| SP → PRC | 0,181 | 0,18 | 0,0967 | -0,0126 | 0,39 |
| EIN → PRC | 0,406 | 0,416 | 0,0575 | 0,3038 | 0,52 |
| R2 | |||||
| PRC | 0,594 | 0,607 | 0,04 | 0,533 | 0,678 |
Fuente: elaboración propia.
4. Análisis y evaluación de la FPC
Una vez aplicada la metodología, se está en condiciones de evaluar los constructos que componen la FPC. Pero antes conviene identificar las regiones más competitivas en la economía del conocimiento. La figura 2 describe las regiones según su localización y país de origen.
Las 137 regiones están localizadas en 37 países. El 54% son industrializados o intensivos en innovación. En este grupo se localiza el 66,4% de las regiones, mientras que el 32,4% de los países son de estadio de eficiencia en la inversión y de reciente industrialización, y albergan el 27,9% de las regiones. Finalmente, el 13,5% de los países son de industrialización tardía o basada en requerimientos básicos, y contienen apenas el 5,9% de las regiones competitivas en la economía del conocimiento.
De acuerdo con los resultados obtenidos al estimar la FPC de las regiones competitivas en la economía del conocimiento, se confirman las dos hipótesis planteadas: se probó que los cinco constructos son unidimensionales, es decir, las variables que los conforman pertenecen a la variable latente. Por otra parte, se verificó que existe relación directa y significativa entre la PRC con todos y cada uno de los demás constructos que integran la función. Esto se corrobora debido a que el modelo presenta una elevada bondad de ajuste, y los valores de los parámetros estimados se encuentran en los márgenes y criterios esperados.
4.1. Unidimensionalidad de los constructos
Como se mostró en la tabla 2, los constructos propuestos superaron las pruebas requeridas para garantizar unidimensionalidad y consistencia. A partir de los resultados del outer model, se resalta que los indicadores reflejan en buena medida cada constructo, en este sentido, se aportó evidencias sobre la unidimensionalidad de cada concepto teórico, mostrando que los cinco componentes propuestos miden las propiedades del conocimiento y su relación con el espacio en las regiones más competitivas en la economía del conocimiento. A continuación, se describe el contenido de cada uno de los constructos.
1. GID: respecto a este constructo, se puede afirmar que es unidimensional y, tal y como lo proponían Griliches (1979), Romer (1990) y la OCDE (2018), describe los esfuerzos financieros para producir conocimiento, financiando las modalidades de la investigación. Como constructo, el GID también representa los esfuerzos de una región para incrementar la capacidad de adsorción (Cohen y Levinthal, 1990).
Los resultados de la tabla 2 arrojan que el GID realizado por el sector de educación superior no presentó correlación con el GID del sector empresarial y público. Este resultado concuerda con los hallazgos de Caicedo-Asprilla (2018), quien ha establecido las dificultades de las regiones latinoamericanas para articular la triple hélice.
Dentro del constructo de GID, se destaca el esfuerzo innovador que realiza el sector empresarial y privado; dado que tiene la mayor carga factorial, levemente por encima del esfuerzo realizado por el sector público. Este resultado es consistente con los hallazgos de la OCDE (2018), pues muestra que, en las regiones más desarrolladas, el GID de las empresas es mayor que el de los otros agentes del sistema. Por lo que las patentes de las empresas han ido creciendo en los últimos años.
En cuanto a la cadena de valor de la investigación, según los resultados, predomina la financiación en la investigación aplicada por sobre las demás modalidades de investigación. Existe más relación entre la financiación del Estado y las empresas que entre estas con las universidades; la intensiva inversión en conocimiento de las empresas es lo que explica el aumento de nuevos productos y servicios en clústeres (Audretsch et al., 2019).
2. Recursos humanos (HUM): como se propuso, este constructo representa el saber de los individuos en una región. Los resultados confirman esta idea y colocan de manifiesto que existe correlación entre el saber qué de la educación media, el saber cómo y el porqué de la superior, y el saber con quién o el conocimiento propio del personal dedicado a la investigación.
Es de resaltar que, según los datos de la tabla 2, el indicador total de empleados en I+D es el elemento más importante para contribuir a un buen capital humano en la generación de nuevo conocimiento. Este hallazgo deja ver que actualmente tiene mucha relevancia que las empresas están emprendiendo, junto con las universidades, la ejecución de proyectos en el nuevo modo tres de la investigación (Carayannis, Grigoroudis, Campbell, Meissner y Stamati, 2018). Este hecho se acentúa con la formación de redes científicas. Hallazgos semejantes pueden encontrarse en los trabajos de Scuotto et al. (2017) y Carayannis et al. (2018).
Aunque no menos importante, seguido con una carga más baja, se presentan los matriculados en la educación superior, este juega un papel relevante en el constructo; en tanto que evidencian como fundamentales el saber cómo, el porqué y quién sabe qué. En cierta manera, se rescata la importancia del conocimiento tácito como clave para la producción de más conocimiento. Este hecho ya había sido sugerido y demostrado por Johnson et al. (2002) y Cowan et al. (2000).
Es de resaltar que en el constructo de HUM no son relevantes los matriculados en la educación media, pues no se conservó la variable educación secundaria en el constructo de HUM. Este resultado concuerda con la presunción de autores como Meusburger (2013), que discuten ampliamente que el saber qué, en cuanto es apenas el acercamiento a los datos o información, no es suficiente para tomar decisiones, y mucho menos para producir nuevo conocimiento.
3. SP: este constructo representa los flujos de conocimiento que circulan en la región. Además, da cuenta de la cantidad de conocimiento público o no rival con que las empresas cuentan para producir nuevos conocimientos, que luego serán productos y servicios (Audretsch et al., 2019).
Según los resultados de la tabla 2, todos los indicadores de los SP tienen significancia estadística e integran bien el constructo. Se destaca el hecho de que para las regiones son muy relevantes los SP asociados a los servicios, debido a la importancia que tienen en la actual economía basada en servicios intensivos en conocimiento (Audretsch et al., 2019; Capello y Lenzi, 2013). Por su parte, las patentes siguen siendo clave en los desbordamientos espaciales, hecho que ya hace más de veinticinco años había mostrado Jaffe et al. (1993). El papel de los matriculados en nivel superior y del personal dedicado a la investigación es fundamental en el actual crecimiento endógeno (Romer, 1990; OCDE, 2018; Audretsch et al., 2019).
Se debe resaltar que el constructo de SP tiene una gran consistencia y unidimensionalidad, esto se debe tal vez a que todos los flujos de conocimiento tienden a ser importantes, tanto si se evalúan juntos como por separado; es lo que Capello y Lenzi (2013) denominan enfoque cognitivo, que se refiere a la suma de todos los efectos secundarios derivados del conocimiento.
4. EIN: al igual que los anteriores constructos, también superó las pruebas estadísticas a las que fue sometido, por lo que es fiable. Así las cosas, se puede afirmar que, en las regiones, el EIN, tal y como se ha definido y calculado aquí, recoge la importancia que tiene para la producción de nuevo conocimiento la proximidad (Balland et al., 2014), el contacto cara a cara (Storper y Venables, 2004), los canales de circulación (Maskell et al., 2006), la formación de los clústeres (Audretsch et al., 2019) y el conocimiento colectivo (Antonelli y Colombelli, 2015). La sumatoria y combinatoria de todos los elementos configuran un ambiente particular y propicio para la creación de nuevo conocimiento (Capello y Lenzi, 2013).
Los datos de la tabla 2 muestran que este constructo tiene una gran homogeneidad, hecho que se refleja en que los 12 indicadores que lo componen tienen carga cercana a 1. Esto significa que todos los indicadores son necesarios e importantes; que, en términos de entorno, estos se complementan conformando un todo homogéneo en una región, o lo que, en términos de Aydalot (1986), Bramanti (1999), Capello y Lenzi (2013) y Kasmi (2018), implica un enfoque relacional y cognitivo al espacio geográfico.
5. PRC: este constructo también está bien conformado, según la tabla 8. De aquí que la producción de patentes, publicaciones y patentes en TIC recogen bien la actividad de creación de nuevo conocimiento en una región.
En cuanto a la producción científica y tecnológica, se corrobora la importancia de las solicitudes de patentes como output de la actividad innovadora, así como del número de patentes en TIC, debido a sus similares y grandes cargas. Con menor cuantía se evidenció la relevancia de las publicaciones científicas como resultado de producción de nuevo conocimiento.
4.2. Análisis de la función de producción de conocimiento
Una vez confirmada la validez de los constructos propuestos, se está en condiciones de analizar la FPC que de ellos se deriva. La estructura de esta función se muestra en la figura 3; el avance aquí es la evidencia de los coeficientes de determinación o, lo que es lo mismo, la contribución o impacto que tiene cada variable explicativa sobre la explicada.
Fuente: elaboración propia.
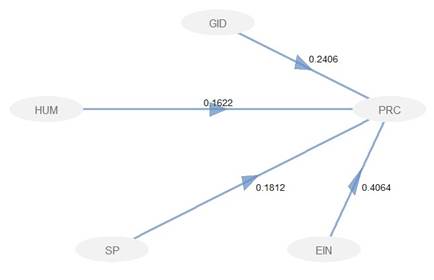
Figura 3 Gráfico inner model
La figura 3 refleja la estructura de la FPC mediante lo que en PLS se denomina el modelo estructura. Aquí se muestra que los coeficientes Path de los cuatro factores son positivos y significativos. Que la bondad de ajuste o R2 tiene un valor de 0,6, que indica que por lo menos en un 60% se ajusta el modelo a los datos. Por otro lado, el índice Götz también presenta un ajuste de calidad del 70% (Götz, et al., 2010). Hecho que muestra que el modelo está bien especificado (Rigdon, 2016).
Ahora bien, el análisis de los coeficientes arroja que el factor más importante de la FPC es el EIN, con un coeficiente Path de 0,4; es decir, el EIN contribuye con cerca del 40% de la PRC en una región competitiva. Esto indica que el ambiente en que se crea conocimiento es fundamental para su producción (Aydalot, 1986; Bramanti, 1999; Capello y Lenzi, 2013).
El coeficiente Path de 0,4 indica que en la PRC son de suma importancia las redes, el aprendizaje, la gobernanza y la innovación, como motores de la creación de nuevo conocimiento. La importancia de estos elementos radica en que son los que garantizan la competitividad en el largo plazo. De aquí se deduce entonces que entre más se potencie el EIN, más conocimiento se generará en la región.
En la figura 3 se evidencia que el GID contribuye con cerca del 24% en la PRC de una región. A la vez que indica que es el segundo constructo en nivel de importancia, con un coeficiente Path de 0,24, en la creación y explotación de nuevo conocimiento. Resultados similares se han encontradodesde la década del ochenta del siglo pasado (Griliches, 1979).
Dado que el constructo de GID está compuesto por los gastos de la empresa, el Gobierno y las universidades, se infiere de los resultados que es fundamental la financiación de la investigación de la empresa y del Gobierno para la PRC, en tanto que entre más se invierta en investigación y desarrollo más conocimiento se experimenta en la región. Hoy en día, las empresas son conscientes de la importancia del papel que juega el GID; al parecer, asumen los riesgos que entraña invertir en un bien público en el largo plazo. Sin embargo, para disminuir este riesgo, el Gobierno también es importante, dado que para este no es prioridad la ganancia.
Por su parte, el constructo de SP aporta aproximadamente el 18% a la PRC. Esto indica que las externalidades técnicas son una especie de piscina u osmosis tecnológica donde todos los agentes que tengan las capacidades de adsorción, es decir, que gasten en aprendizaje, aprovechan para producir conocimiento (Audretsch et al., 2019).
El constructo de SP, como efecto secundario, se desborda de las universidades, empresas, centros de investigación, etc., y su productividad aumenta con más SP, configurando una cadena que se retroalimenta positivamente y, como asegura Romer (1990), son la fuente de rendimientos crecientes. De aquí se desprende que mayores esfuerzos en generación de SP redundan en más y mejor conocimiento.
Por último, el constructo de HUM aporta el 16% a la PRC. Si bien el HUM es el de menor aporte de todos los constructos, no implica que sea el de menor importancia. Lo que está indicando es que los HUM por sí solos no garantizan el crecimiento ni la producción de nuevo conocimiento. Se requiere que a los científicos e investigadores se les den las condiciones necesarias para crear y producir. Hipótesis y reflexiones semejantes se hallan en los trabajos de Meusburger (2013), Antonelli y Colombelli (2015).
Como se puede observar, la sumatoria de los cuatro constructos es equivalente al 100% de la PRC. Lo cual puede estar indicando que la FPC aquí propuesta es útil y pertinente para entender la PRC y su relación con el espacio. Puede indicar que entre los constructos existe una complementariedad, por lo que la PRC está más cerca de experimentar rendimientos crecientes. Esta clase de FPC es propia de situaciones en donde las economías son más evolutivas y atrapadas en caminos de dependencia.
5. Conclusiones
En este trabajo se logró plantear una propuesta de FPC basada en constructos. Lo relevante de esta FPC es que fue sometida a las pruebas de fiabilidad y logró superarlas. De aquí que el objetivo de esta investigación se alcanzó, porque, en primer lugar, se plantearon constructos y se validaron estadísticamente; gracias a esto, se dispone de una interpretación de cómo se produce el conocimiento, rescatando sus propiedades, no solo como bien económico, sino como elemento central de la toma de decisiones y la acción social.
El otro logro de esta investigación fue poder validar la FPC como una estructura compuesta por constructos. Esto es relevante porque ha permitido el acercamiento a una mejor interpretación de la forma en que los distintos componentes de una región, EIN, SP, GID y HUM, se integran en el territorio para facilitar y crear las condiciones para producir conocimiento. Aquí se ha pretendido rescatar que la PRC es un fenómeno de suyo complejo, en donde juegan un rol muchos valores e instituciones.
En cuanto a implicaciones para futuras investigaciones, aquí se ha puesto de manifiesto el efecto positivo y significa-tivo de todos los constructos, pero con distintos niveles de impactos en la PRC. Mientras el EIN se presenta como el constructo de mayor relevancia, el de HUM experimenta los efectos más bajos. De igual forma se rescata el impacto casi semejante que tienen los GID y los SP.
Conviene seguir investigando las cuestiones políticas preliminares, con el fin de confirmar estos primeros resultados. En ese sentido, debe investigarse i) el impacto de los gastos de los gobiernos locales hacia la generación de más SP; ii) la contribución de los subsidios a aquellas investigaciones que tengan un fin más básico que aplicado; iii) la importancia de los estímulos a las empresas para que inviertan más en nuevos productos y servicios intensivos en conocimiento, para que se jalone más la calidad de los insumos y de todo el tejido empresarial; iv) evaluar el impacto de elevar la educación por encima de la media, dado que esta por sí sola no contribuye a la competitividad.
Este estudio aporta a la construcción de herramientas avanzadas para realizar la estimación de los determinantes de la PRC. Aquí se ha mostrado la potencialidad de la aplicación de PLS-PM, como una técnica relevante para casos de modelación flexible. Dado que puede ser aplicada a los SRI, que suelen presentar problemas de condiciones teóricas poco desarrolladas y tamaños de muestra pequeños.
No obstante, se han identificado algunas limitaciones que conviene mencionar. En primer lugar, la disponibilidad de datos que permitan la valoración exhaustiva de distintos aspectos concernientes a los sistemas de I+D es limitada y obliga a la imputación de datos y a considerar algunos elementos como representativos de su evolución. En este sentido, queda como recomendación llevar a cabo estudios similares para corroborar los hallazgos obtenidos.
Una segunda limitación del estudio guarda relación con el espacio temporal evaluado a corte trasversal. La realización del análisis a nivel longitudinal puede contribuir en el hallazgo de la evolución de los factores determinantes de la innovación, pero se requieren estudios longitudinales para evaluar el comportamiento de estos constructos en el tiempo.
Aunque se consideraron las regiones más competitivas en la economía del conocimiento, queda como recomendación considerar regiones disímiles, no solo en desarrollo, sino en tipo y producción de innovación; para contar con grupos de regiones más heterogéneos, con el objetivo de obtener resultados más explicativos en el campo de la PRC científico y tecnológico.