4 Uniendo objetos
Ya discutimos cómo, a partir de unos datos, podemos obtener un conjunto de datos con las observaciones de condiciones deseables (ver Capítulo 2) y las variables tal como queramos (ver Capítulo ??). En el flujo de trabajo de un científico de datos, o persona que trabaja con datos, encontraremos la situación en la que tenemos que unir diferentes objetos con datos. En este capítulo nos concentraremos en algunas de las principales situaciones con las cuales nos toparemos al unir objetos con datos.
4.1 Combinar observaciones
En algunas ocasiones nos enfrentaremos al caso en el cual dos objetos con las mismas variables (no necesariamente en el mismo orden) y cada objeto tiene observaciones para diferentes individuos o casos. En este sencillo caso, lo único necesario es colocar las filas de un objeto debajo de las filas del otro. Esto lo podemos realizar con el verbo bind_rows() (unir filas en español). En la Figura 4.1 se presenta esquemáticamente este caso.
Figura 4.1: Representación del proceso de unir filas
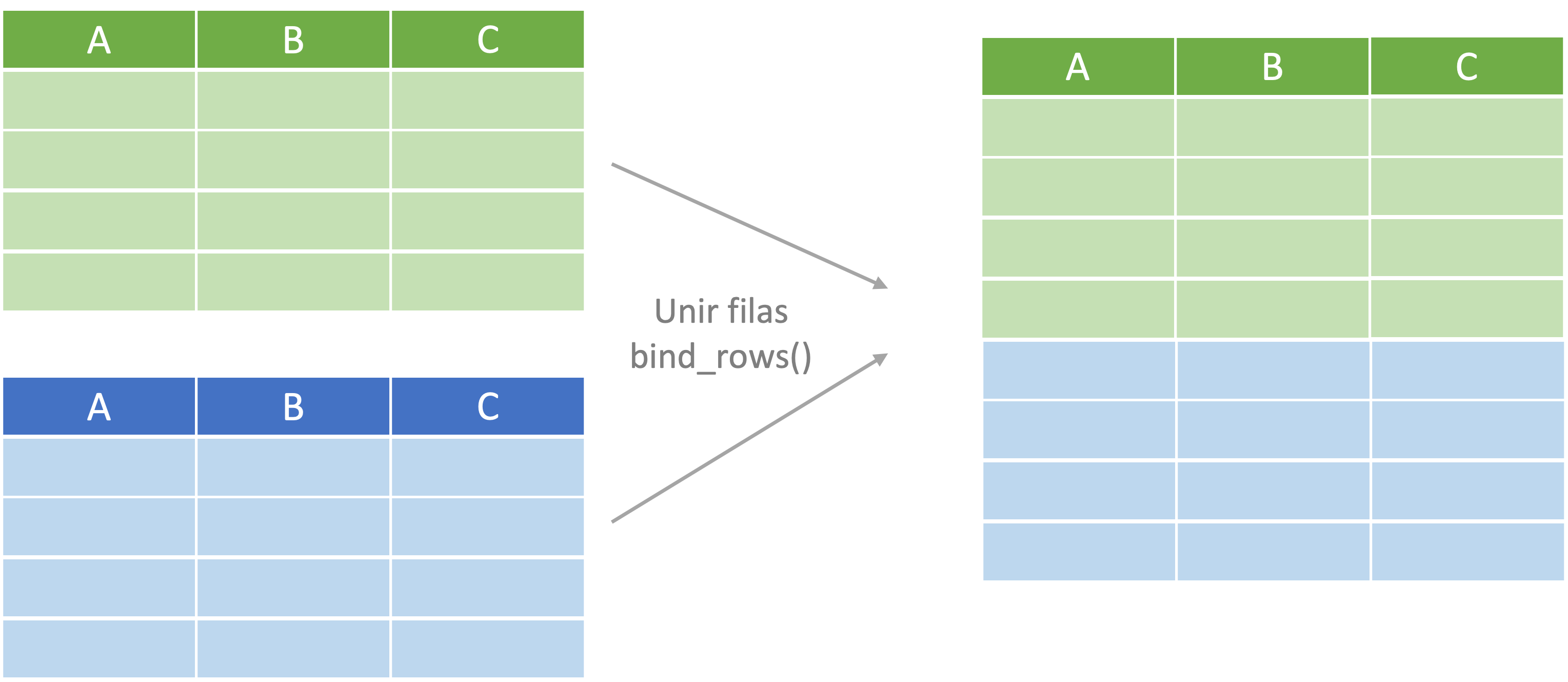
Para este ejemplo emplearemos dos bases de datos que se encuentran en los archivos obj1.csv y obj2.csv18. El archivo obj1.csv contiene datos para 4 individuos y tres variables. La primera variable es un identificador del individuo (ID) y las tres variables restantes tienen los nombres A, B y C (en este ejercicio no será importante el significado de estas variables). El archivo obj1.csv tiene datos para 6 individuos para las mismas variables, pero estas se encuentran en diferente orden.
Carga los dos archivos y mira el contenido de cada uno de los objetos. Nota que los objetos cargados son de clase data.frame.
# Carga de bases de datos
obj1 <- read.csv("obj1.csv", header = TRUE, sep = ",")
obj2 <- read.csv("obj2.csv", header = TRUE, sep = ",")
# Mirando los objetos
obj1## ID A B C
## 1 2290 6 6 6
## 2 2278 5 9 10
## 3 2321 6 1 2
## 4 2308 8 8 1obj2## ID B A C
## 1 2305 7 5 1
## 2 2246 6 10 8
## 3 2262 10 8 7
## 4 2227 5 10 8
## 5 2321 5 9 2
## 6 2237 0 7 5Ahora, para combinar los dos objetos en uno solo, usaremos el verbo bind_rows() empleando los dos objetos como argumentos.
obj3 <- bind_rows(obj1, obj2)
obj3## ID A B C
## 1 2290 6 6 6
## 2 2278 5 9 10
## 3 2321 6 1 2
## 4 2308 8 8 1
## 5 2305 5 7 1
## 6 2246 10 6 8
## 7 2262 8 10 7
## 8 2227 10 5 8
## 9 2321 9 5 2
## 10 2237 7 0 5En la base de R se encuentra la función rbind() que realiza una tarea similar. No obstante, existen diferentes ventajas al emplear este verbo del paquete dplyr, dentro que las que se destacan dos; la función bind_rows() al requerir menos memoria RAM, es mas rápida. Esto permite agilizar el análisis, en especial si tenemos muchos datos o estamos empleando Big Data. Y por otro lado, la función bind_rows() permite combinar dos objetos de clase data.frame que tengan diferente número de columnas. rbind() presentará un error, mientras que bind_rows() asigna “NA” a aquellas filas de las columnas que faltan.
4.2 Combinar variables
En otras ocasiones tendremos datos para los mismos individuos en dos objetos19 y necesitamos fusionarlos en uno solo. Esto puede realizarse con el verbo bind_cols() (unir columnas en español). En la Figura 4.2 se presenta de manera esquemática este caso.Figura 4.2: Representación del proceso de unir columnas
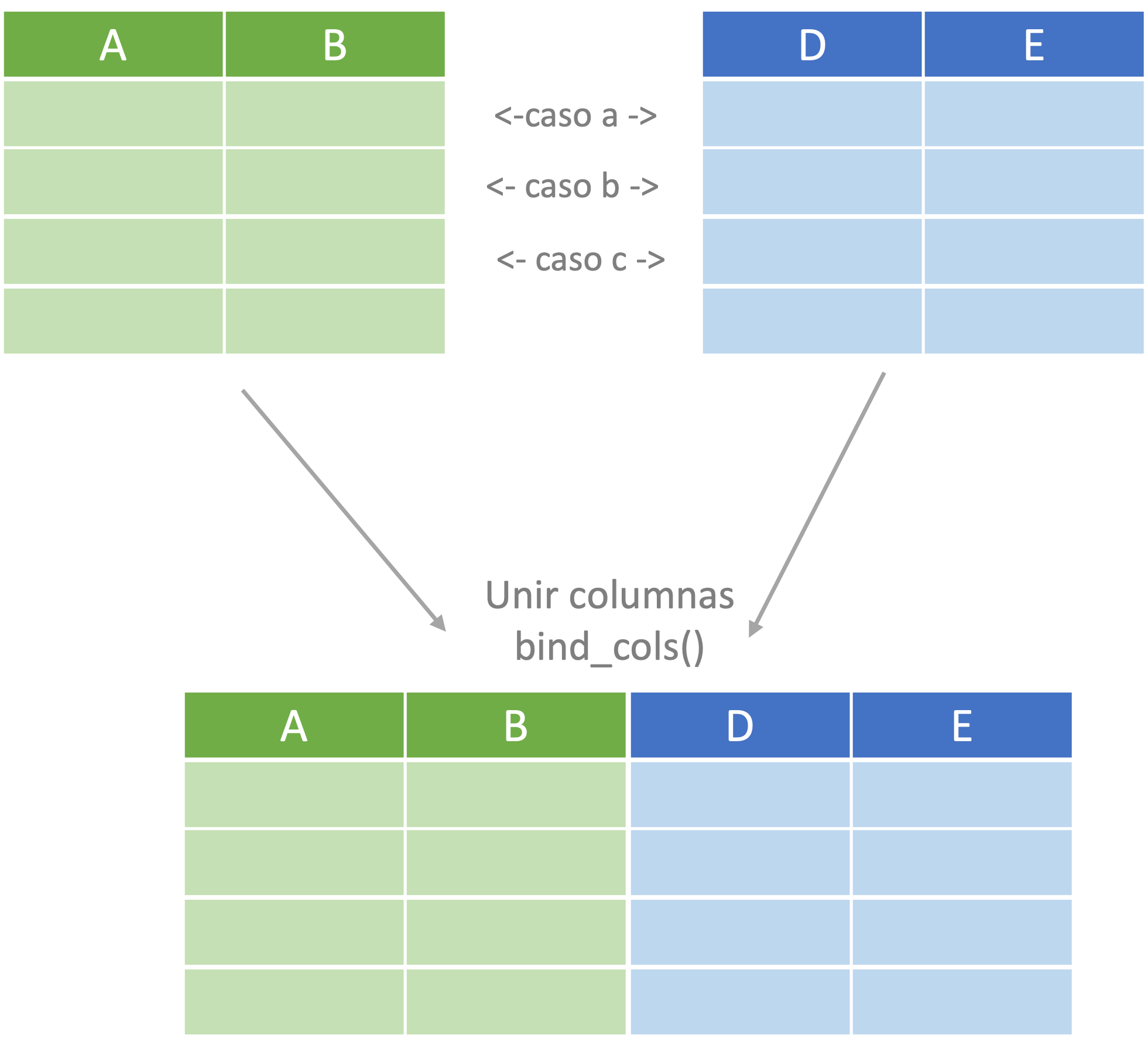
En el archivo obj1b.csv20 tenemos datos para las variables D y E de los mismos individuos que están en el objeto obj1. Carguemos y miremos los datos.
# Carga de bases de datos
obj1b <- read.csv("obj1b.csv", header = TRUE, sep = ",")
# Mirando los objetos
obj1b## ID D E
## 1 2290 10 8
## 2 2278 7 9
## 3 2321 10 8
## 4 2308 2 4obj1## ID A B C
## 1 2290 6 6 6
## 2 2278 5 9 10
## 3 2321 6 1 2
## 4 2308 8 8 1Unamos los dos objetos21 empleando el verbo bind_cols y como argumentos los dos objetos.
obj4 <- bind_cols(obj1, obj1b)## New names:
## * ID -> ID...1
## * ID -> ID...5obj4## ID...1 A B C ID...5 D E
## 1 2290 6 6 6 2290 10 8
## 2 2278 5 9 10 2278 7 9
## 3 2321 6 1 2 2321 10 8
## 4 2308 8 8 1 2308 2 4La variable ID estaba en ambos objetos y por tanto aparece dos veces en el nuevo objeto creado. Para evitar esto podemos usar el verbo select(), estudiado en el Capítulo ??.
obj4 <- obj1b %>%
select(-c(ID)) %>%
bind_cols(obj1)
obj4## D E ID A B C
## 1 10 8 2290 6 6 6
## 2 7 9 2278 5 9 10
## 3 10 8 2321 6 1 2
## 4 2 4 2308 8 8 14.3 Combinar Observaciones y variables
En la sección anterior discutimos cómo unir dos objetos en condiciones ideales. Los casos están en los dos archivos y se encuentran en el mismo orden. Pero, a veces esas condiciones ideales no se presentan. Podemos encontrarnos con situaciones en las que no todos los casos se encuentren en los dos objetos, o estén organizados de forma diferente.
Por ejemplo, veamos el archivo obj5.csv22 que contiene datos para las variables F, G y H. Carguemos los datos y veámoslo.
# Carga de bases de datos
obj5 <- read.csv("obj5.csv", header = TRUE, sep = ",")
# Mirando los objetos
obj5## ID F G H
## 1 2305 6 3 4
## 2 2227 4 3 5
## 3 2230 2 3 7
## 4 2403 3 3 8obj2## ID B A C
## 1 2305 7 5 1
## 2 2246 6 10 8
## 3 2262 10 8 7
## 4 2227 5 10 8
## 5 2321 5 9 2
## 6 2237 0 7 5obj5, dos están en el obj2 (ID 2305 y 2227) y 2 no lo están (ID 2230 y 2403). Si queremos unir los datos de los dos archivos hay varias posibilidades. La primera es que al unir el obj2 con el obj5, creemos un nuevo objeto con solo los casos que se encuentran en los dos objetos. Es decir, con solo los casos para los cuales tenemos datos de todas las variables. Esto corresponde al verbo unir internamente o inner_join() en el lenguaje de dplyr. Este verbo implica retener solo los casos que están en ambos objetos. En la Figura 4.3 se presenta de manera esquemática esta operación.
Figura 4.3: Representación del proceso de unir internamente
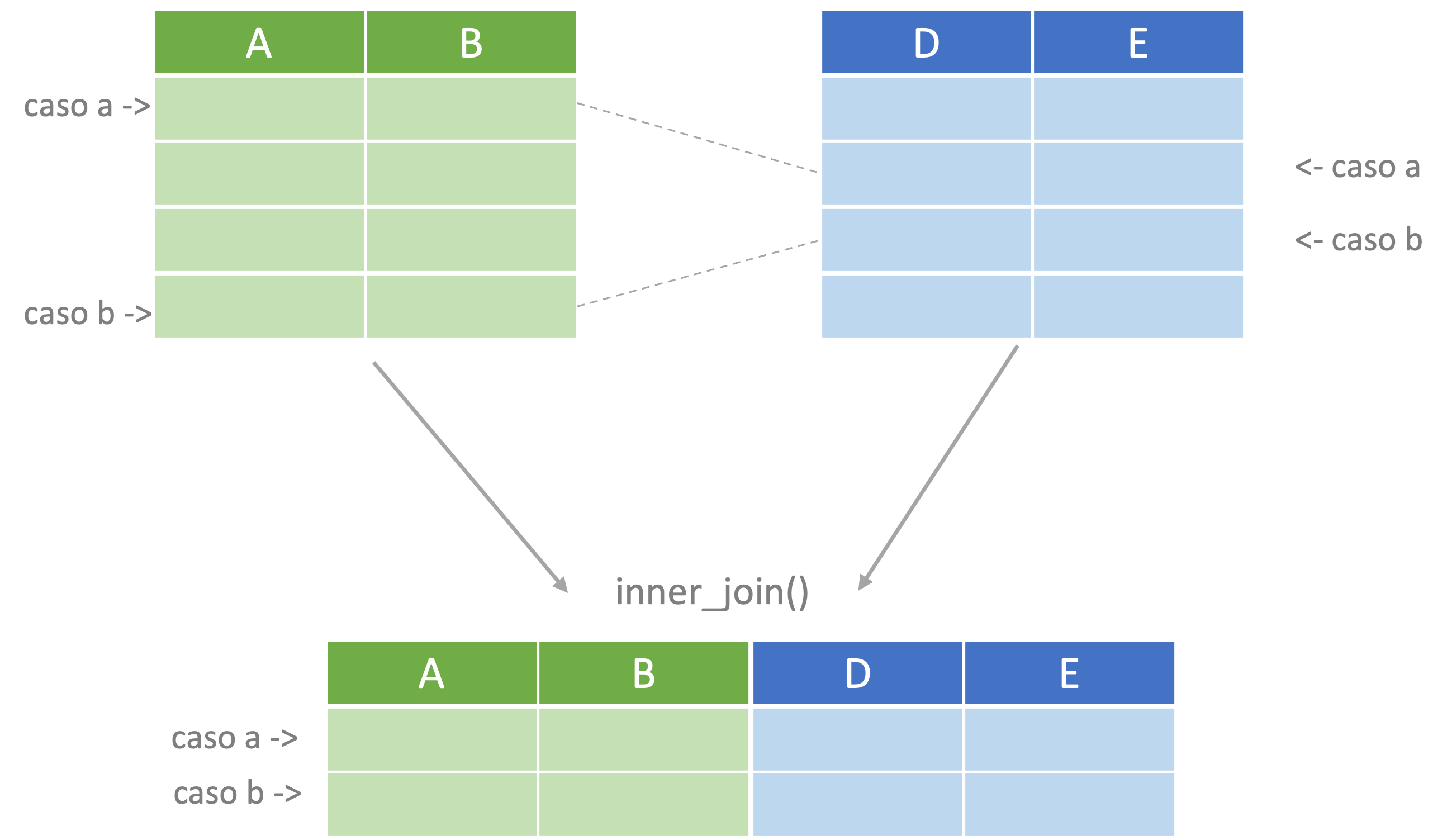
Este verbo tiene como argumentos a los dos objetos y al argumento by que permite especificar qué se empleará para identificar los casos en ambos objetos. Sino se especifica el argumento by, esta función automáticamente encontrará cuál variable se repite en ambos objetos.
# inner join
obj6 <- inner_join(obj5, obj2, by = "ID")
# mirando el objeto
obj6## ID F G H B A C
## 1 2305 6 3 4 7 5 1
## 2 2227 4 3 5 5 10 8NA” (no disponible o valor perdido) para esa variable y caso. Esto se puede realizar con el verbo unir a la izquierda (left_join()) . Este verbo retiene solo los casos que están en el primer objeto ( ver Figura 4.4).
Figura 4.4: Representación del proceso de unir a la izquierda
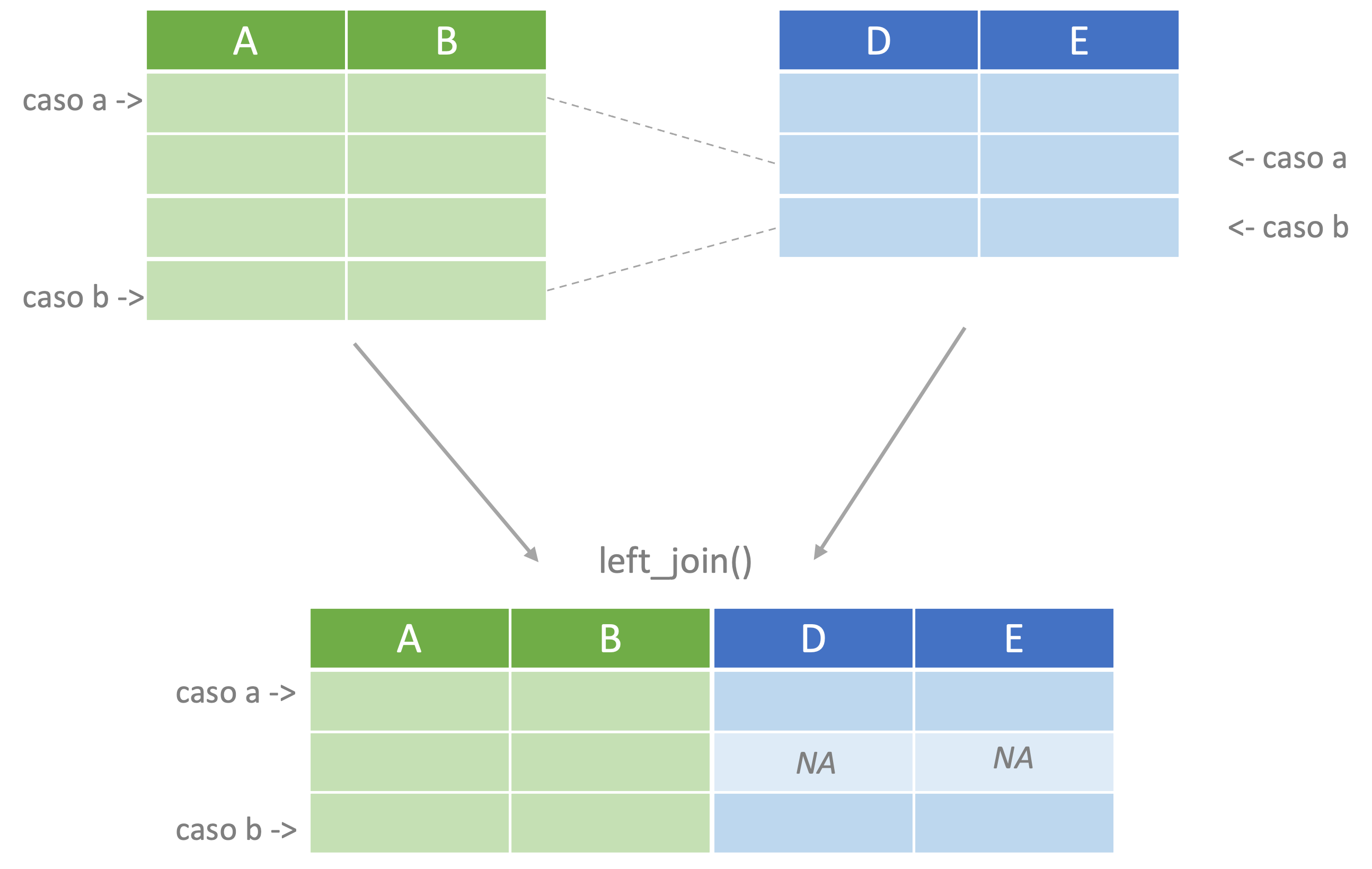
Este verbo funciona de manera similar al inner_join. Continuemos con nuestro ejemplo.
# left join
obj7 <- left_join(obj5, obj2, by = "ID")
# mirando el objeto
obj7## ID F G H B A C
## 1 2305 6 3 4 7 5 1
## 2 2227 4 3 5 5 10 8
## 3 2230 2 3 7 NA NA NA
## 4 2403 3 3 8 NA NA NAFigura 4.5: Representación del proceso de unir a la derecha
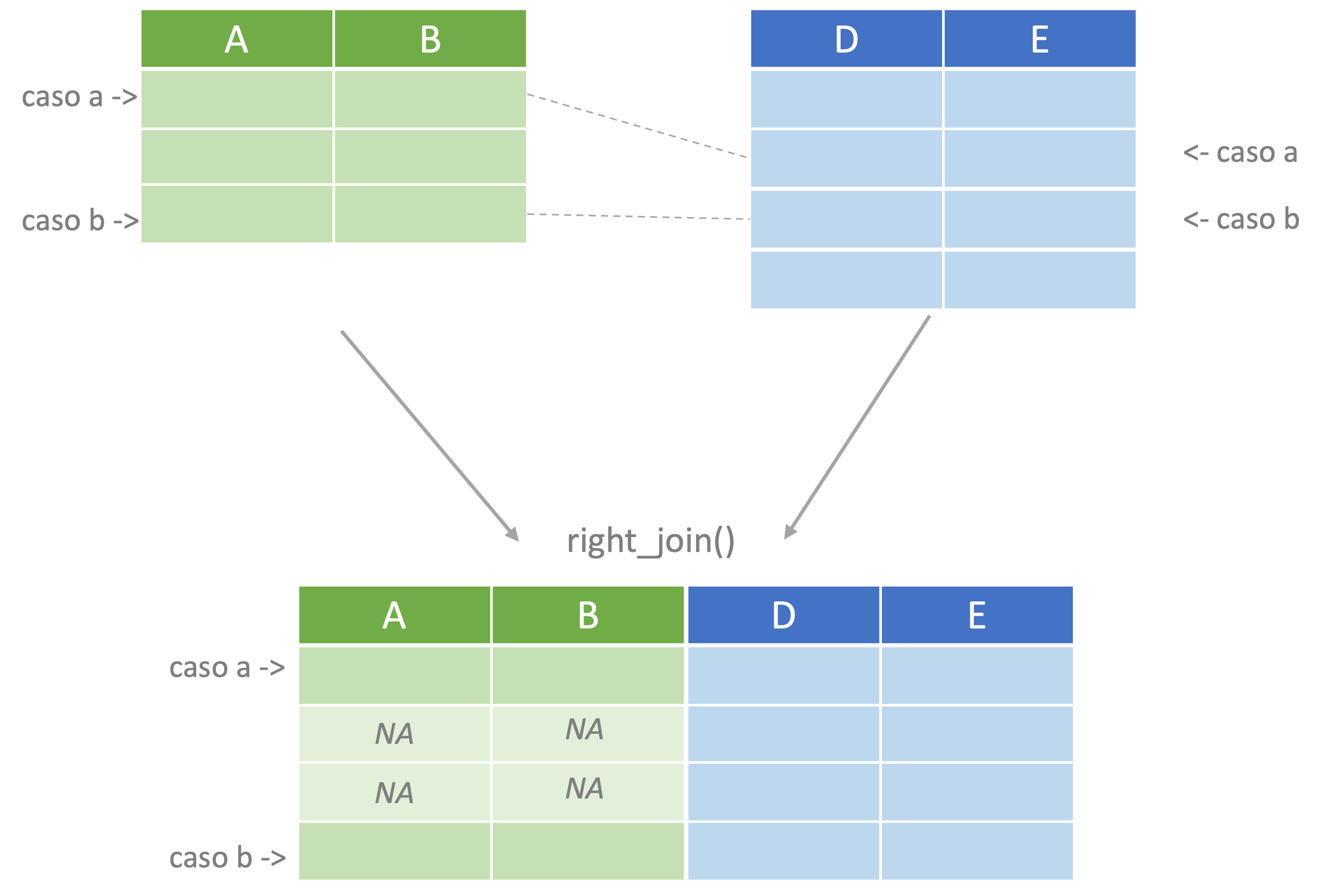
A estas alturas, la gramática de estos verbos debe ser evidente para ti. Sigamos con nuestro ejemplo.
# right join
obj8 <- right_join(obj5, obj2, by = "ID")
# mirando el objeto
obj8## ID F G H B A C
## 1 2305 6 3 4 7 5 1
## 2 2227 4 3 5 5 10 8
## 3 2246 NA NA NA 6 10 8
## 4 2262 NA NA NA 10 8 7
## 5 2321 NA NA NA 5 9 2
## 6 2237 NA NA NA 0 7 5La última posibilidad que consideraremos para unir objetos es cuando necesitamos construir un objeto que tenga todos los casos presentes en los dos objetos. Esto se realiza con el verbo full_join() o unir completamente en español (Ver Figura 4.6).
Figura 4.6: Representación del proceso de unir completamente.
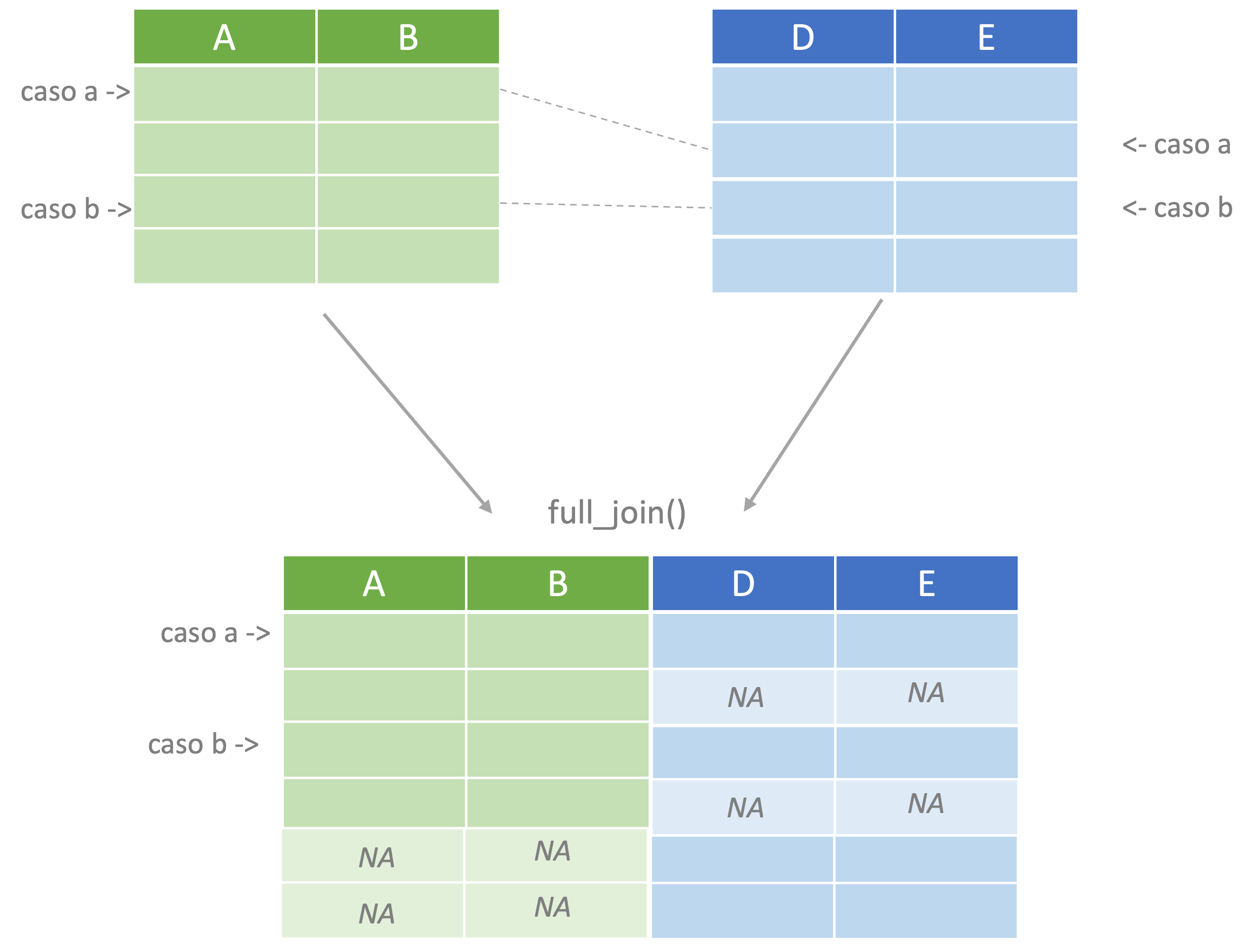
El siguiente código presenta un ejemplo del verbo full_join().
# full join
obj9 <- full_join(obj5, obj2, by = "ID")
# mirando el objeto
obj9## ID F G H B A C
## 1 2305 6 3 4 7 5 1
## 2 2227 4 3 5 5 10 8
## 3 2230 2 3 7 NA NA NA
## 4 2403 3 3 8 NA NA NA
## 5 2246 NA NA NA 6 10 8
## 6 2262 NA NA NA 10 8 7
## 7 2321 NA NA NA 5 9 2
## 8 2237 NA NA NA 0 7 5En la base de R se encuentra la función merge(), esta realiza una tarea similar a los verbos join() y los otros terminados en _join() . No obstante, al igual que con el caso bind_rows() y rbind(), existen diferentes ventajas al emplear los verbos del paquete dplyr. Se destacan dos razones. Las funciones join() de dplyr tienden a ser más rápidas que merge() cuando se emplean objetos de datos grandes. Esto sucede porque el paquete dplyr usa de manera mas eficiente la RAM de los equipos.
Por otro lado, las funciones join() de dplyr conservan el orden original de las filas en los data.frame, mientras que la función merge() ordena automáticamente las filas en orden alfabético según la columna utilizada para realizar la unión.
4.4 Comentarios finales.
En este capítulo revisamos los verbos que nos permiten unir dos objetos con datos. Si los unimos con los que hemos estudiado en los capítulos anteriores, tendremos una caja de herramientas completa para trabajar con datos.
Antes de continuar, es importante mencionar que existen otros verbos para unir objetos que podrían ser útiles en alguna oportunidad. Por ejemplo: intersect(), union(), semi_join() y anti_join(). Ya puedes ver la ayuda de estas funciones y emplearlas sin ningún problema.
Los archivos los puedes descargar de la página web del libro (http://www.icesi.edu.co/editorial/empezando-transformar).↩︎
Es importante que las observaciones se encuentren en el mismo orden en los dos archivos.↩︎
El archivo lo puedes descargar de la página web del libro (http://www.icesi.edu.co/editorial/empezando-transformar).↩︎
Nota que los datos están organizados de la misma manera en ambos objetos. Es decir, la primera fila en ambos objetos corresponde al mismo individuo (
ID) y así para todos los otros casos.↩︎El archivo lo puedes descargar de la página web del libro (http://www.icesi.edu.co/editorial/empezando-transformar).↩︎