3 Geometrías para mostrar distribución
Tal vez la decisión más importante para una buena visualización es la capa de Geometría. Como lo discutimos al final del Capítulo 2, para la selección de la Geometría nos podemos guiar con la pregunta ¿qué queremos mostrar? La Figura 3.1 presenta las posibles visualizaciones para las posibles respuestas a esta pregunta. En este Capítulo nos concentraremos en cómo implementar los gráficos más comunes que permiten mostrar la distribución de una o varias variables (ver área sombreada de la Figura 3.1).
Figura 3.1: Tipos de gráficos más comunes según lo que se desea comunicar y la clase de variable.
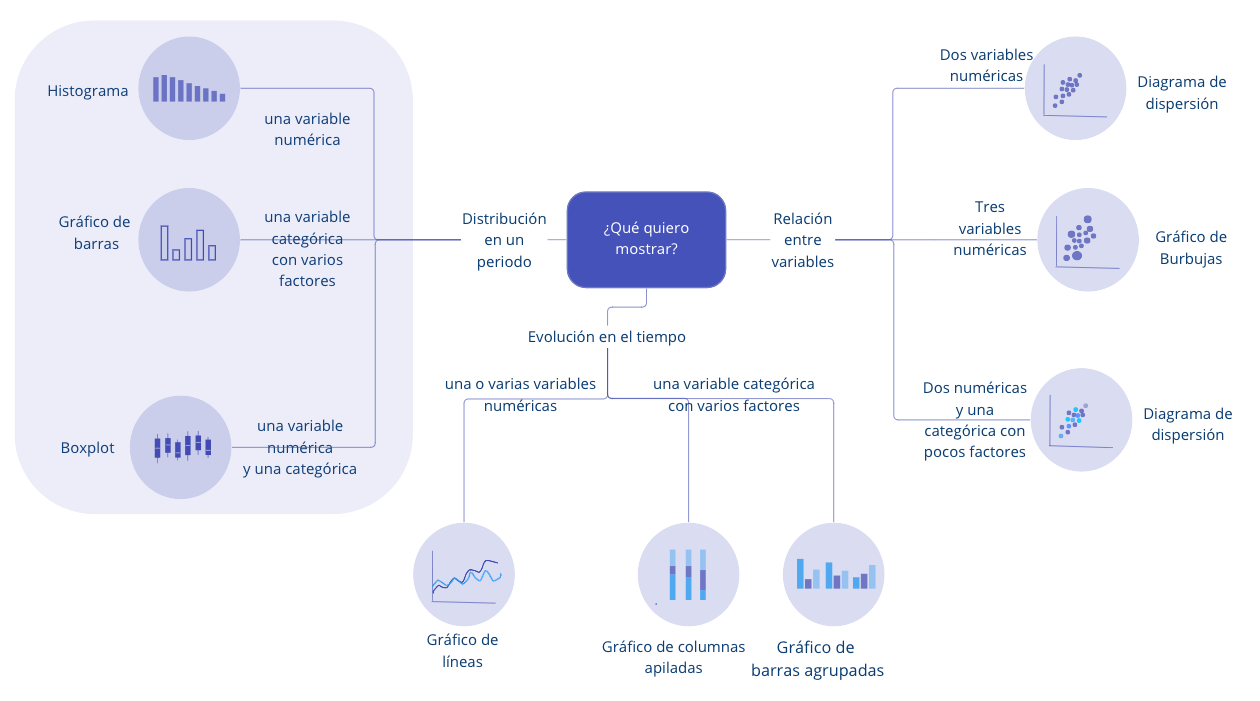
Los gráficos más comunes para mostrar la distribución de una o varias variables son22:
- Histograma
- Gráfico de barras
- Boxplot o Diagrama de cajas23.
Estos gráficos nos permiten representar todas las observaciones de la variable, cuáles son más frecuentes, cuál es la tendencia central de los datos y su dispersión. En otras palabras, estas visualizaciones están diseñadas para mostrar rápidamente cómo se comportan todos los datos. En general estas geometrías hacen más sencillo mostrar grandes cantidades de datos.
3.1 Histograma
Los histogramas están diseñados para mostrar la distribución de una variable de clase numeric (variables cuantitativas contínuas) o de clase integer(variables cuantitativas discretas). Un histograma agrupa los datos en intervalos pequeños que se miden típicamente en el eje horizontal y en el eje vertical se representa la frecuencia de aparición de las observaciones dentro de los límites del intervalo. La función para este tipo de gráficos es geom_histogram().
Veamos un ejemplo con los datos, empleados en el Capítulo 2, del objeto gapminder del paquete del mismo nombre. Representemos la distribución de la expectativa de vida al nacer de todos lo países para el año 2007. Carguemos los paquetes y filtremos los datos para el año 2007. Esta será la primera capa. Ahora, empleemos el paquete ggplot2 para construir el histograma. Necesitamos enviar a la capa de datos el objeto gapminder, en la capa de Aesthetics especificar la variable que mapearemos en el eje x. Después, la capa de Geometría corresponderá a geom_histogram(). El siguiente código genera la Figura 3.2
# cargamos los paquetes
library(ggplot2)
library(dplyr)
library(gapminder)
# se emplea el operador pipe para
# pasar los datos y filtrar los
# datos
gapminder %>%
filter(year == 2007) %>%
ggplot(aes(x=lifeExp)) +
geom_histogram() +
labs( y="Frecuencia",
x="Exp. de vida") +
theme_minimal()
Figura 3.2: Histograma de la esperanza de vida al nacer de todos los países del mundo (2007)
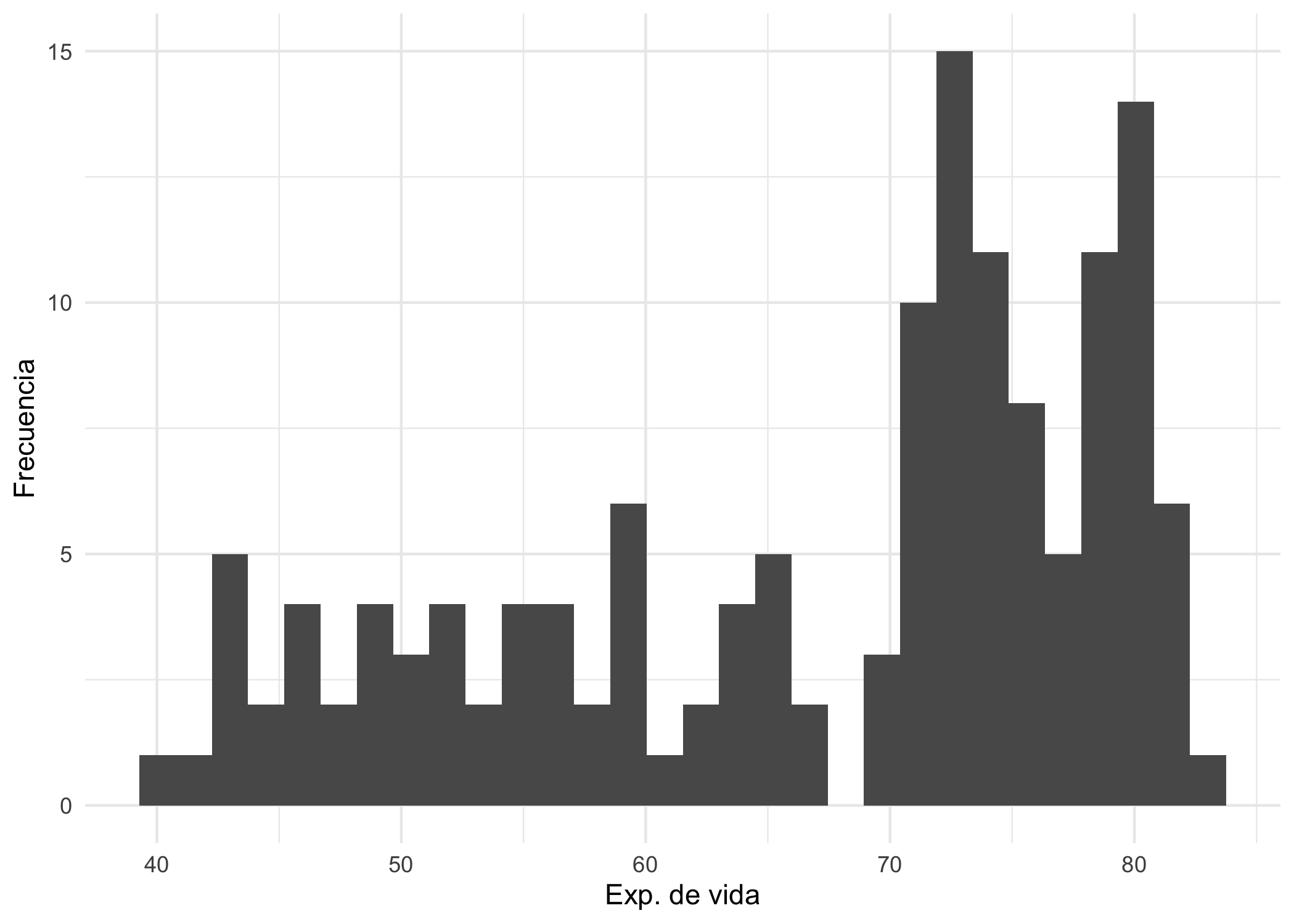
Nota que en el código incluimos en la capa de Escalas la función labs() que corresponde a las etiquetas en inglés. Esta función nos permite ponerle nombres a los ejes, título (argumento title) y subtítulo (argumento subtitle), entre otras etiquetas.
La Figura 3.2 muestra un histograma en color gris; color que es el valor por defecto de esta función. Si quisieras cambiar el color del histograma24, lo podemos hacer con el argumento fill. Por ejemplo, corre estas líneas de código y obtendrás un histograma de color azul claro:
# Histograma de colo azul claro
gapminder %>%
filter(year == 2007) %>%
ggplot(aes(x = lifeExp)) +
geom_histogram(fill = "lightblue") +
labs( y="Frecuencia",
x="Exp. de vida") +
theme_minimal()Si quieres ajustar otros aspectos del histograma, como el número de clases (grupos), puedes emplear los diferentes argumentos de esta función. Recuerda que buscar ayuda sobre una función es muy fácil.
3.2 Gráfico de barras
Los gráficos de barras permiten visualizar la distribución de una variable cualitativa; es decir, variables de clase character o factor. Este gráfico muestra con barras cuál es la frecuencia con que se observa cada uno de los posibles valores de la variable cualitativa. Este tipo de gráficos se puede construir con la función geom_bar().
Por ejemplo, consideremos la variable continent que es un factor con cinco posibles valores. Visualicemos cómo es la distribución de países por continente en los datos de gapminder para el 2007. Es decir, contemos cuántas veces se repite cada continente en los datos de 2007. Esto lo podemos hacer con el siguiente código:
# se emplea el operador pipe para
# pasar los datos y filtrar los
# datos
gapminder %>%
filter(year == 2007) %>%
ggplot(aes(x = continent)) +
geom_bar(fill = "royalblue4") +
labs( y="Frecuencia",
x="Continente") +
theme_minimal()
Figura 3.3: Distribución de los países por continente disponibles en los datos de gapminder para 2007
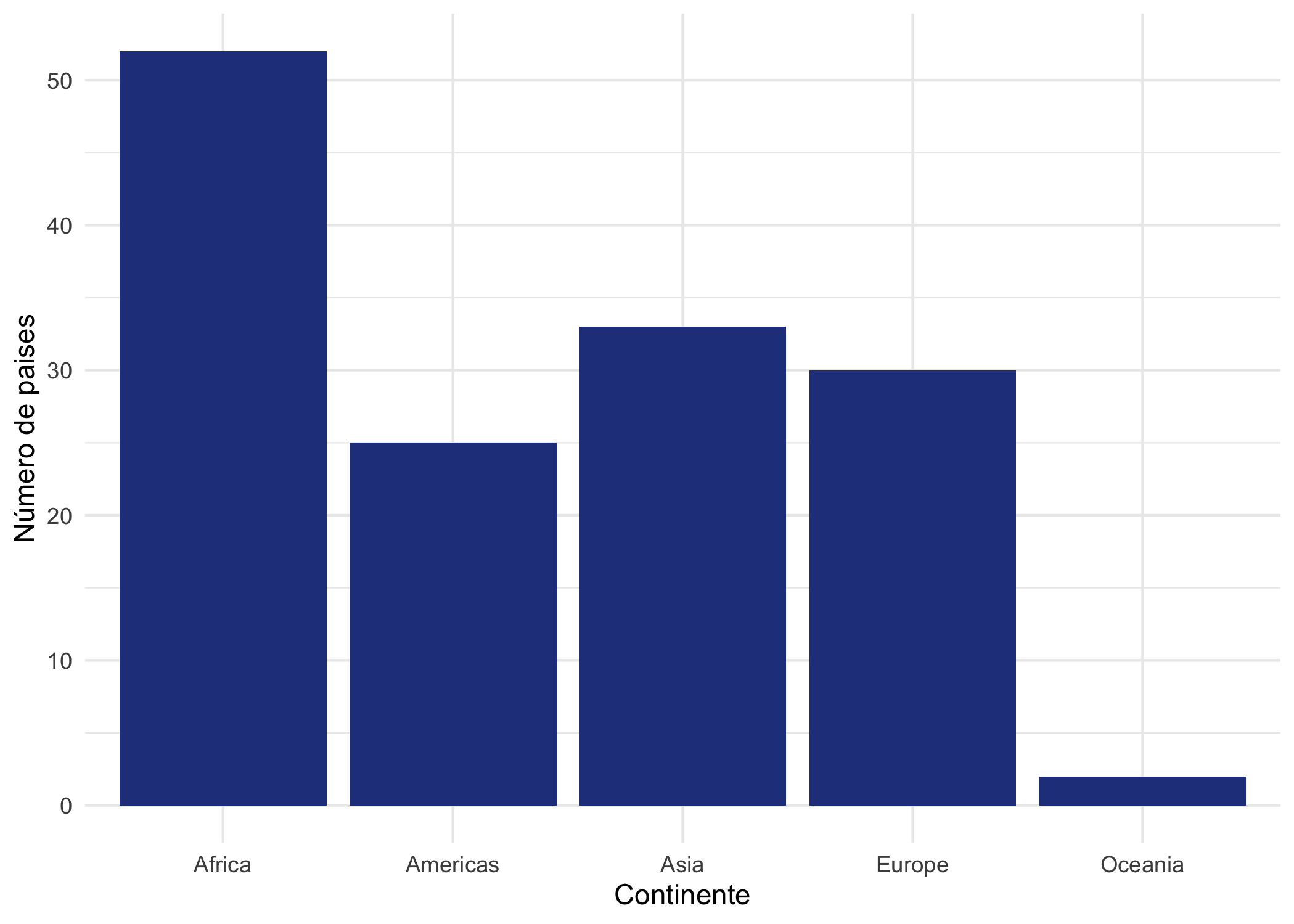
Recuerda que existen muchos más parámetros en estas funciones de la geometría que pueden ayudar a mejorar tu visualización. Es importante que mires en la ayuda todas las opciones que tienes.
La misma información anterior puede mostrarse de manera relativa (como porcentaje de todos los países) y no de manera absoluta (el número de países por continente). Este gráfico se conoce como un gráfico de barras de porcentajes. Esto lo podemos hacer de varias formas. Una forma es crear una base de datos con una columna que tenga el nombre del continente y otra con el porcentaje de países que el respectivo continente representa. Otra forma es modificar el código anterior, para calcular dicho porcentaje directamente en la función.
Por ejemplo, intenta evaluando el siguiente código:
gapminder %>%
filter(year == 2007) %>%
ggplot(aes(x = continent,
y=100 * (..count..)/sum(..count..))) +
geom_bar( fill = "royalblue4") +
labs( y="%",
x="Continente") +
theme_minimal()Mira con cuidado cómo se creó la variable y empleando ..count... Esta función cuenta la variable x para cada uno de los factores de esta.
3.3 Boxplot
Los Boxplot son conocidos como diagrama de cajas y bigotes o diagrama de cajas. Estos gráficos requieren de una audiencia con una formación en estadística para poder transmitir bien los mensajes poderosos que revelan. En tus cursos de estadística con seguridad estudiaste o estudiarás esta visualización. Por ahora recordemos que esta visualización permite observar el primer, segundo y tercer cuartil, la distancia intercuartílica y la existencia o no de datos atípicos. La Figura 3.4 te permitirá recordar la interpretación de este gráfico.
Figura 3.4: Elementos de un Boxplot
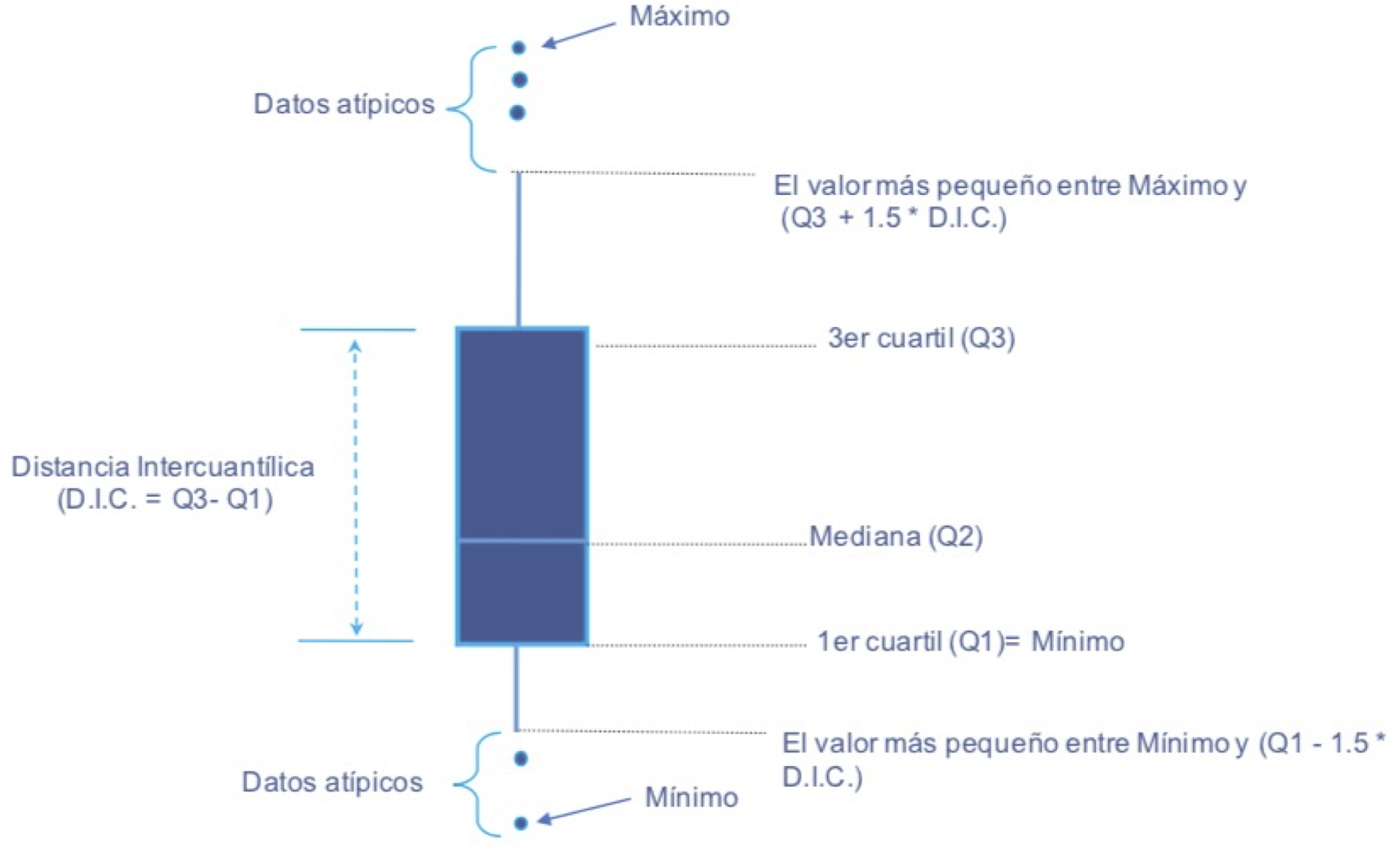
Este gráfico es muy empleado para comparar la distribución de una variable cuantitativa para los diferentes valores posibles de una variable cualitativa. Típicamente, la variable cualitativa se representa en el eje horizontal y en el eje vertical se representa la variable cuantitativa. La función que permite construir este gráfico es geom_boxplot().
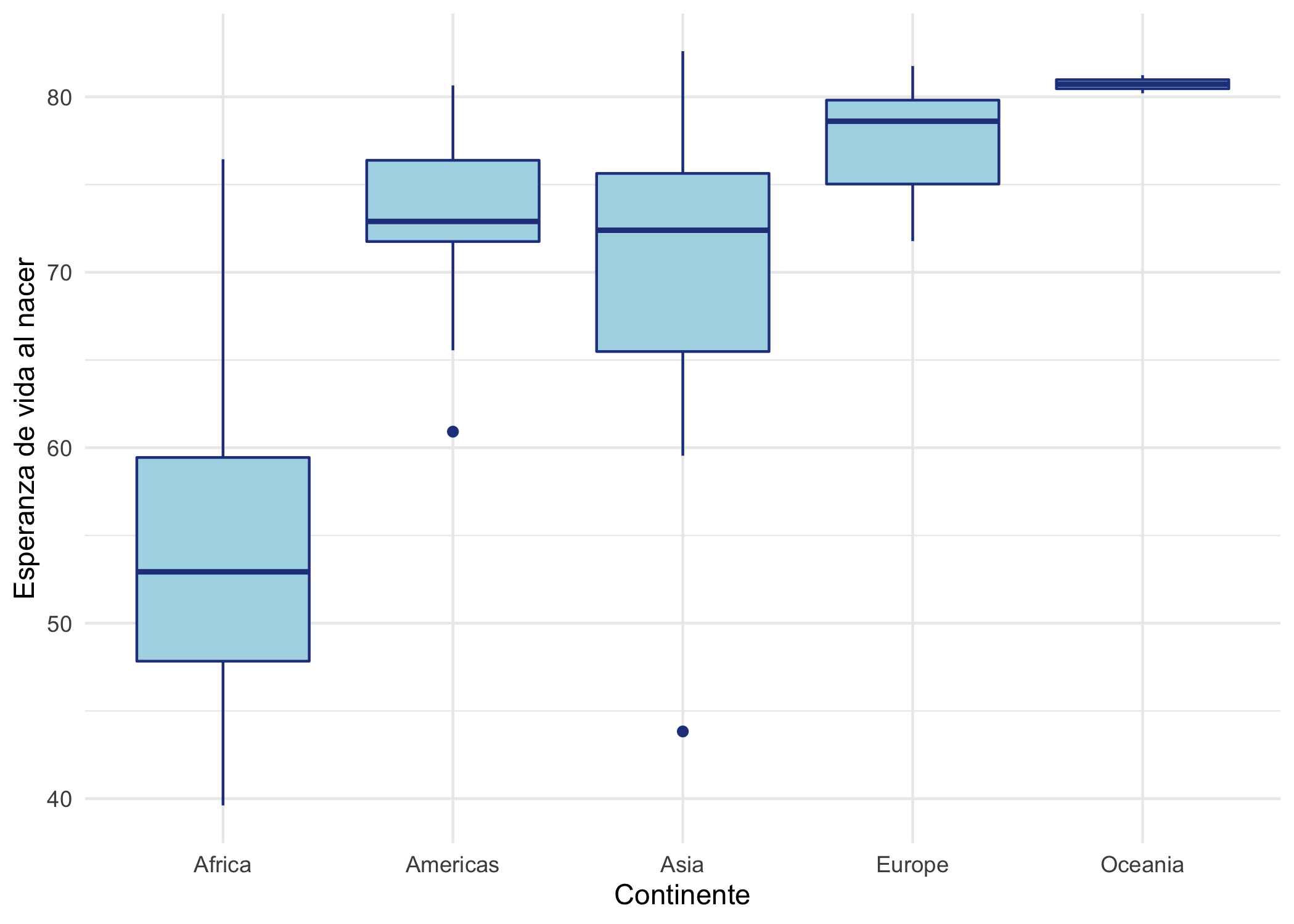
Visualicemos la distribución de la esperanza de vida al nacer por continente para el año 2007. Esto lo podemos hacer de la siguiente manera:
# se emplea el operador pipe para
# pasar los datos y filtrar los
# datos
gapminder %>%
filter(year == 2007) %>%
ggplot(aes(x = continent, y = lifeExp)) +
geom_boxplot(fill = "lightblue",
col = "royalblue4" ) +
labs( y="Esperanza de vida al nacer",
x="Continente") +
theme_minimal()
Figura 3.5: Boxplot de la esperanza de vida al nacer por continente para 2007.
3.4 Comentarios finales
Antes de continuar con las capas de Geometría que permiten mostrar evolución de una o más variables, es importante anotar que existen otras visualizaciones no tan comunes para mostrar distribución. Por ejemplo, está el gráfico de densidad, diagrama de violines25, los gráficos de donas, los gráficos de waffles, los gráficos de bombones, los treemaps (como la Figura 1.4), los mapas de calor, los diagramas de Sankey y las nubes de palabras26. Si te interesa conocer más de estas visualizaciones puedes encontrar una amplia documentación en línea mantenida por la comunidad de usuarios de R y ggplot2. Ya conoces la lógica y la gramática que emplea este paquete, con seguridad será muy sencillo entender y modificar los códigos que encuentres disponibles en línea. Y no olvides compartir los códigos que creas de utilidad para los miembros de la comunidad.
Las gráficas de tortas no son recomendables. Como se discutirá con más detalle en el Capítulo 6, el gráfico de torta no es una buena elección debido a que el ojo humano no es bueno calculando los ángulos. ¡No se recomienda emplear esta visualización! Existen mejores alternativas. ↩︎
También conocido como diagrama de cajas y bigotes. ↩︎
Nota que esto es muy diferente a mapear una variable al color. Aquí solo estamos cambiando el color del histograma.↩︎
Si quieres conocer sobre los diagramas de violines, puedes ver una breve introducción en el siguiente enlace: https://bit.ly/3Jc71YC.↩︎
Si quieres conocer sobre las nubes de palabras, puedes ver una breve introducción en el siguiente enlace: https://bit.ly/3HO46Fa.↩︎