8 Cargar Bases de Datos en R
Ya tenemos una “caja de herramientas” que permite empezar a usar R con su interfaz RStudio. Ya dominas las clases más comunes de objetos en R y sabes cómo instalar paquetes. Antes de terminar este libro es importante explicar cómo crear objetos de clase data.frame a partir de archivos externos o extraer los datos incluidos en diferentes paquetes.
8.1 Importando Base de Datos de Archivos
Las bases de datos las podemos encontrar en diferentes formatos, pero tal vez los tres formatos más comunes son:
- Archivo de texto con extensión
.txt, - Archivo de texto de valores separados por comas (CSV por su sigla del inglés comma-separated values) con extensión
.csv18 y - Archivo de Excel con extensión
.xlso.xlsx.
A continuación discutiremos cómo cargar cada uno de estos tres formatos de datos.
8.1.1 Leyendo Archivos .txt
Los archivos de texto son conocidos como archivos “planos”, pues no incluyen ninguna información de formato, solo datos “puros”. Es decir, en un archivo de Excel podemos contar con formato para los bordes o para los mismos números. En los archivos planos no hay formato, por lo tanto, estos archivos son más pequeños. Otra ventaja es que este formato de datos no tiene limitaciones de filas o columnas. Excel (la versión Microsoft 365) tiene una limitación de 1,048,576 filas y 16,384 columnas. Esto usualmente no es un problema, pero si podría ser una limitación en el mundo del Big Data.
Los archivos con extensión .txt pueden ser leídos empleando la función read.table() . Los principales argumentos de esta función son la ruta y el nombre del archivo (entre comillas), un argumento que le dice a R si los datos tiene un encabezado header = TRUE o no header = FALSE y el delimitador de los datos (argumento sep).
Para nuestro ejemplo, emplearemos el archivo Employee.txt19, el cual tiene datos recopilados por el área de gestión humana de una de las principales empresas que venden automóviles en todo el mundo. El archivo cuenta con información del número de vendedores y las unidades fabricadas (en miles). Los datos son mensuales para los últimos 5 años.
El archivo lo podemos leer con el siguiente código:
# leyendo el archivo .txt
employee <- read.table("employee.txt", header = TRUE, sep = ",")
# verificando la clase del objeto
class(employee)## [1] "data.frame"Siempre que leamos datos de un archivo es importante estar seguros que los datos quedaron bien cargados; por ejemplo, veamos los primeros 5 datos del objeto employee con la función head():
# inspeccionando los primeros 5 datos
head(employee, 5)## mes vendedores unidades
## 1 1 322 44.2
## 2 2 317 44.3
## 3 3 319 44.4
## 4 4 323 43.4
## 5 5 327 42.8Todo parece bien. Veamos los últimos 3 datos con la función: tail().
# inspeccionando los últimos 3 datos
tail(employee, 2)## mes vendedores unidades
## 59 59 392 49.2
## 60 60 396 48.1Ahora verifiquemos la clase de las variables que componen este data.frame con la función str():
# inspeccionando la clase de cada variable
str(employee)## 'data.frame': 60 obs. of 3 variables:
## $ mes : int 1 2 3 4 5 6 7 8 9 10 ...
## $ vendedores: int 322 317 319 323 327 328 325 326 330 334
## ...
## $ unidades : num 44.2 44.3 44.4 43.4 42.8 44.3 44.4 44.8
## 44.4 43.1 ...Todo parece estar en orden. Los datos han sido leídos correctamente.
RStudio también permite importar datos empleando el menú de “File”. Haciendo clic en File | Import Dataset | From Text (base).... Observarás primero una ventana en la que debes seleccionar el archivo a ser leído. Haz clic en el archivo y verás una ventana como la de la Figura 8.1. Esa ventana es el área de vista previa de datos. Es decir, cómo está R interpretando los datos. Si observas que está leyendo bien los datos haz clic en import, de lo contrario puedes usar las opciones a mano izquierda hasta encontrar las opciones que se ajusten a tu archivo plano de datos. Nota que el código que permitió hacer dicha importación de los datos aparecerá en la consola. Puedes copiar ese código en tu script para no hacer todo este procedimiento la próxima vez que quieras leer esos datos. Recuerda que en esta comunidad siempre será más elegante emplear código para hacer cualquier tarea.
Figura 8.1: Ventana emergente al cargar un archivo .txt
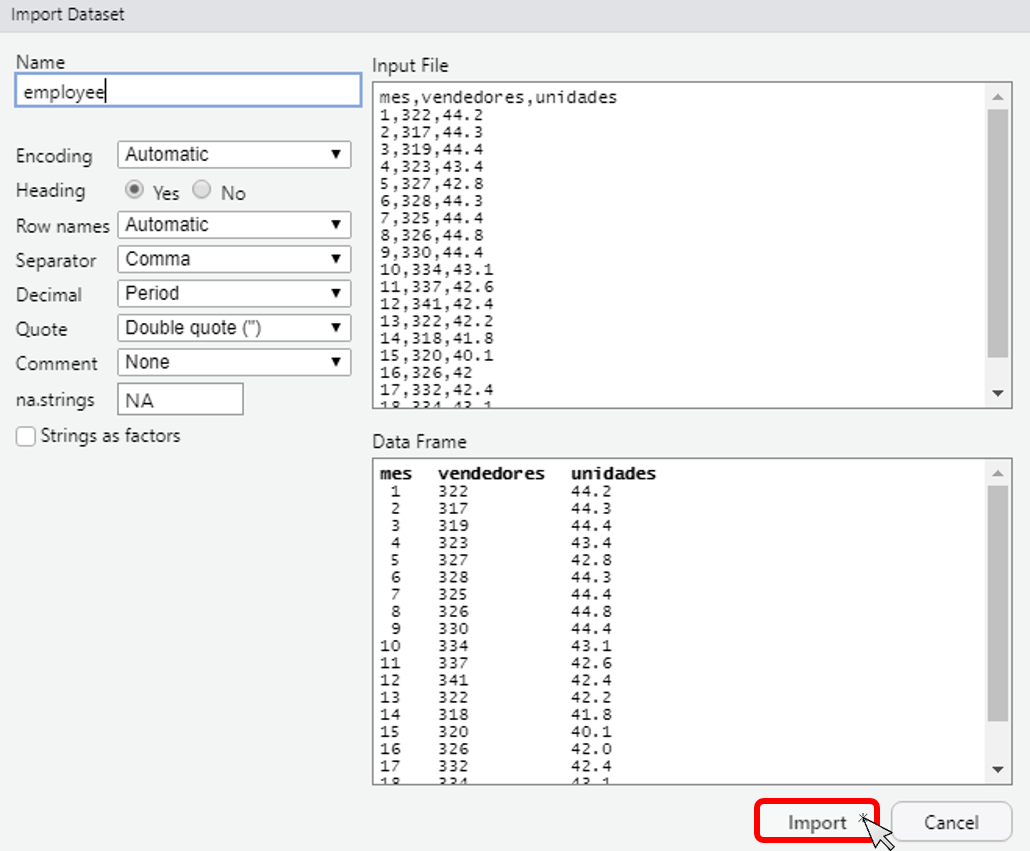
Puedes llegar a las mismas ventanas desde la pestaña Environment en el panel superior derecho donde hay un menú desplegable llamado Import Dataset. El menú desplegable ofrece diferentes opciones del tipo de datos que deseamos importar, ya sea un archivo de texto, un archivo de Excel o un archivo csv.
8.1.2 Leyendo Archivos .csv
Los archivos .csv tienen las mismas ventajas que los archivos .txt sobre los archivos de Excel. Este tipo de archivos se pueden leer con la función read.csv() . Empleemos el archivo Employee.csv20 que tiene la misma estructura del archivo Employee.txt que ya cargamos. En este caso el código será el siguiente:
# leyendo el archivo .txt
employee2 <- read.csv("employee.csv", header = TRUE, sep = ";")
# verificando la clase del objeto
class(employee2)## [1] "data.frame"# inspeccionando los primeros 5 datos
head(employee2, 5)## mes vendedores unidades
## 1 1 322 44.2
## 2 2 317 44.3
## 3 3 319 44.4
## 4 4 323 43.4
## 5 5 327 42.8# inspeccionando los últimos 3 datos
tail(employee2, 2)## mes vendedores unidades
## 59 59 392 49.2
## 60 60 396 48.1# inspeccionando la clase de cada variable
str(employee2)## 'data.frame': 60 obs. of 3 variables:
## $ mes : int 1 2 3 4 5 6 7 8 9 10 ...
## $ vendedores: int 322 317 319 323 327 328 325 326 330 334
## ...
## $ unidades : num 44.2 44.3 44.4 43.4 42.8 44.3 44.4 44.8
## 44.4 43.1 ...Leímos este segundo archivo correctamente, de hecho este último objeto leído es igual al primero. Podemos emplear una prueba lógica utilizando un operador de relación como lo vimos en la sección 4.2.2 de la siguiente manera:
# comparando los elementos de los
# dos objetos leídos
employee == employee2Podemos emplear los mismo procedimientos por menús que vimos anteriormente para leer estos archivos en formato .csv.
8.1.3 Leyendo archivos de Excel
Para cargar datos de un archivos de Excel podemos emplear diferentes paquetes. Tal vez el más sencillo es el paquete readxl (Wickham & Bryan, 2019) De ese paquete usaremos la función read_excel(), la cual permite cargar de manera similar a los archivos planos archivos .xls y .xlsx. Una de las diferencias de esta función es que permite especificar de que hoja en específico queremos leer los datos.
Leamos el archivo Employee.xlsx21 que tiene la misma estructura de los dos archivos anteriores. La única diferencia es que los datos están en la Hoja2, empieazan en la celda C2 y terminan en la celda E62 (abre el archivo de Excel para verificar esto). En este caso podemos especificar la hoja en la que están los datos que queremos leer (argumento sheet) y el rango de celdas que queremos leer (argumento range que se expresa entre comillas).
#instalar el paquete si no lo tienes aún instalado
#install.packages("readxl")
# cargando el paquete
library(readxl)
# leyendo datos del archivo .xlsx que está en hoja2
employee3 <- read_excel("employee.xlsx", sheet = 2,
range = "C2:E62")
# verificando la clase del objeto
class(employee3)## [1] "tbl_df" "tbl" "data.frame"# inspeccionando los primeros 5 datos
head(employee3, 5)## # A tibble: 5 × 3
## mes vendedores unidades
## <dbl> <dbl> <dbl>
## 1 1 322 44.2
## 2 2 317 44.3
## 3 3 319 44.4
## 4 4 323 43.4
## 5 5 327 42.8# inspeccionando los últimos 3 datos
tail(employee3, 2)## # A tibble: 2 × 3
## mes vendedores unidades
## <dbl> <dbl> <dbl>
## 1 59 392 49.2
## 2 60 396 48.1# inspeccionando la clase de cada variable
str(employee3)## tibble [60 × 3] (S3: tbl_df/tbl/data.frame)
## $ mes : num [1:60] 1 2 3 4 5 6 7 8 9 10 ...
## $ vendedores: num [1:60] 322 317 319 323 327 328 325 326
## 330 334 ...
## $ unidades : num [1:60] 44.2 44.3 44.4 43.4 42.8 44.3 44.4
## 44.8 44.4 43.1 ...Así como en el caso de los archivos planos, los archivos de Excel pueden ser cargados empleados los menús de RStudio. El procedimiento es muy similar.
8.2 Extraer Datos de Paquetes
Como se discutió en el Capítulo 7, los paquetes de R contiene datasets (base de datos) que se emplean normalmente para mostrar como funciona el paquete. Otros paquetes son bases de datos, como por ejemplo, el paquete gapminder (Bryan, 2017). El paquete gapminder tiene datos para todos los países de población, pobreza y esperanza de vida entre otras variables. Un listado exhaustivo de paquetes que son exclusivamente bases de datos se puede encontrar en el siguiente enlace: https://stat.ethz.ch/R-manual/R-devel/library/datasets/html/00Index.html
Otros paquetes nos brindan una interfaz para descargar datos de entidades como el Banco Mundial (paquete WDI (Arel-Bundock, 2021) ) o el Fondo Monetario Internacional22 (paquete imfr (Gandrud, 2020)).
Veamos rápidamente cómo traer al workspace objetos de clase data.frame que vienen integrados en los paquetes. El primer paso es cargar el paquete del que se quieren extraer los datos. Sino sabemos con exactitud cuáles son los datos disponibles, o el nombre de los objetos con las bases de datos, podemos emplear la función data() sin ningún argumento. Esto desplegará una ventana con el listado de todas las bases de datos disponibles en los paquetes cargados y el Core de R.
#instalar el paquete si no lo tienes aún instalado
#install.packages("gapminder")
# cargando el paquete gapminder
library(gapminder)
# listando las bases de datos disponibles
data()O podemos ver los datos que hay en un solo paquete; por ejemplo, el paquete gapminder:
#
# listando las bases de datos disponibles
# en un paquete específico
data(package = 'gapminder')En el Cuadro 8.1 se presenten las bases de datos presentes en el paquete gapminder.
Nombre | Descripción |
continent_colors | Gapminder color schemes. |
country_codes | Country codes |
country_colors | Gapminder color schemes. |
gapminder | Gapminder data. |
gapminder_unfiltered | Gapminder data, unfiltered. |
Una vez identifiquemos el objeto que tiene la base de datos que queremos, la podemos cargar al workspace empleando la misma función data(), empleando como argumento el nombre de la base. Si necesitamos ayuda para conocer a detalle de la base de datos, podemos emplear la función help() empleando como argumento el nombre de la base. Por ejemplo, supongamos que queremos cargar la base de datos que está en el objeto gapminder del paquete del mismo nombre pero no sabemos qué contiene. Por eso es importante consultar la ayuda de la siguiente manera:
# mirando la descripción de los datos en el objeto
help(gapminder)Una vez constatamos que esta base tiene la información que deseamos, podemos cargarla de la siguiente manera:
# cargando la base de datos al ws
data("gapminder")
# clase del objeto cargado
class(gapminder)## [1] "tbl_df" "tbl" "data.frame"8.3 Comentarios Finales
En este capítulo estudiamos cómo cargar bases de datos desde archivos y desde paquetes. Ahora estás listo para procesar tus datos y analizarlos. En el último capítulo discutiremos rápidamente cuáles pueden ser tus siguientes pasos en este universo de R.
Referencias
De hecho en algunas ocasiones los archivos con extensión
.csvpueden estar delimitados por “;”. En español es común que en los archivos csv los datos se separen por puntos y comas para evitar la confusión que puede generar el delimitador de decimales que es una coma.↩︎El archivo se puede encontrar en la página web del libro: http://www.icesi.edu.co/editorial/empezando-usar↩︎
El archivo se puede encontrar en la página web del libro: http://www.icesi.edu.co/editorial/empezando-usar↩︎
El archivo se puede encontrar en la página web del libro: http://www.icesi.edu.co/editorial/empezando-usar↩︎
No discutiremos este tipo de paquetes pero puedes mirar su ayuda. Encontrarás que es relativamente fácil emplearlos y bajar datos de esos repositorios.↩︎