10 Primer caso de negocio (actualizado)
Objetivos del capítulo
El lector, al finalizar este capítulo, estará en capacidad de:
- Emplear las herramientas estudiadas en los capítulos anteriores para responder una pregunta de negocio que implique analítica diagnóstica.
- Presentar los resultados de una regresión de manera gráfica empleando R con solución H.C..
- Determinar cuál variable tiene más efecto sobre la variable explicativa empleando R en presencia de heteroscedasticidad.
10.1 Introducción
En el Capítulo 7 trabajamos en responder una pregunta de negocio del portal de noticias en Internet Mashable (https://mashable.com). La pregunta de negocio del editor era: ¿De qué depende el número de shares de un artículo? A esta pregunta venía anexa otra: ¿Existe alguna variable accionable que pueda ser modificada para generar una recomendación a los escritores?
Responder esta pregunta de negocio implicaba realizar analítica diagnóstica y realizamos una búsqueda automática para encontrar modelos candidatos a ser el mejor modelo. Posteriormente los comparamos empleando pruebas de modelos no anidados para encontrar el mejor modelo. Este análisis lo hicimos sin tener en cuenta que podíamos estar violando supuestos del Teorema de Gauss-Markov. En este capítulo realizaremos las modificaciones necesarias a nuestro análisis para brindar una respuesta estadísticamente correcta a la pregunta de negocio.
Recordemos que para realizar nuestro análisis contamos con una base de datos que contenía los artículos publicados en un periodo de dos años suministrada por Fernandes et al. (2015). La base de datos se encuentra en el archivo DatosCaso1.csv103. La base de datos contiene 39644 observaciones y 61 variables que se describen en la sección 7.2.
De esta manera, la base de datos con que trabajaremos corresponde a datos de corte transversal. De inmediato debemos sospechar de un posible problema de heteroscedasticidad. A continuación recrearemos nuevamente todos los pasos seguidos en el Capítulo 7 y se aclararán cuáles pasos deben ser modificados en presencia de multicolinealidad y heteroscedasticidad (¡si es que encontramos que existe alguno o ambos problemas!).
10.2 El plan
Recordemos que nuestra primera tarea fue trazar una ruta analítica para responder la pregunta de negocio.
Ahora, con esta aproximación completa debemos ajustar nuestro plan (en negrilla se resaltan los nuevos pasos) que serán los siguientes:
- Encontrar diferentes modelos candidatos a ser el mejor modelo.
- Determinar si existe un problema de heteroscedasticidad en los modelos candidatos.
- Limpiar los modelos candidatos de variables no significativas.
- Comparar los modelos candidatos para seleccionar un único modelo.
- Determinar si existe un problema de multicolinealidad.
- Identificar la variable más importante para explicar la variable dependiente.
- Generar las recomendaciones .
- Generar visualizaciones de los resultados.
Empecemos a ejecutar esa ruta analítica para resolver la pregunta de negocio.
10.3 Detección de posibles modelos
Recuerden que la primera variable en la base de datos no es relevante (url), ésta corresponde al enlace del artículo, y por tanto la debemos eliminar. Lo cual implica que tendremos 5.7646075^{17} posibles modelos.
Lean los datos empleando la función read.csv(), guárdenlos en el objeto datos.caso1 y elimina la primera variable que no es relevante.
El siguiente paso es encontrar los mejores modelos empleando las estrategias de regresión paso a paso forward, backward y combinada con el AIC, con el valor p y el \(R^2\) ajustado. No obstante, en este caso que es posible que exista heteroscedasticidad (más adelante lo demostraremos) es mejor no emplear el criterio del valor p, pues sabemos que este criterio depende del estadístico t, el cual a su vez depende del estimador del error estándar. Y sabemos que en presencia de heteroscedasticidad, estos errores estándar no son los mínimos posibles. Es decir, si existe heteroscedasticidad, los errores estándar no son los más pequeños posibles, y por tanto los t calculados estarán errados y por tanto los valores p.
Por otro lado, el problema de multicolinealidad puede hacer que el \(R^2\) esté inflado y, por tanto, el \(R^2\) ajustado puede también estar inflado. Pero por ahora no tenemos por qué intuir este problema. Trabajaremos con esta métrica, pero teniendo en mente que nuestro resultado podría estar afectado por un problema de multicolinealidad cuando empleemos el \(R^2\) ajustado para seleccionar un candidato a mejor modelo.
Esto nos deja con 6 opciones de algoritmos y criterios de selección que se presentan en el Cuadro 10.1. Mantendremos los mismos nombres de modelos que se emplearon en el Capítulo 7 para evitar confusiones. Los modelos que obtenemos los guardaremos con los nombres que se presentan el Cuadro 7.1.
| Nombre del objeto | Algoritmo | Criterio |
|---|---|---|
| modelo1 | Forward | \(R^2\) ajustado |
| modelo3 | Forward | AIC |
| modelo4 | Backward | \(R^2\) ajustado |
| modelo6 | Backward | AIC |
| modelo7 | Both | \(R^2\) ajustado |
| modelo9 | Both | AIC |
| Fuente: elaboración propia. |
Partamos de estimar los modelos lineales con todas las variables potenciales (max.model).
Ahora procedamos a encontrar modelos candidatos para ser los mejores modelos. Empecemos con la estrategia stepwise Forward.
10.3.1 Stepwise forward
Empecemos por el modelo 1: algoritmo Forward y criterio de \(R^2\) ajustado.
# cargando la librería
#library(leaps)
modelo1 <- regsubsets(x = datos.caso1[,1:59], y = datos.caso1[,60],
nvmax=60, method = "forward")## Reordering variables and trying again:m1 <- summary(modelo1)
index <- 1:length(modelo1$xnames)
n.index <- index[m1$which[which.max(m1$adjr2),]==1]
vars.modelo1 <- modelo1$xnames[index[m1$which[which.max(m1$adjr2),]==1]]
vars.modelo1 <- vars.modelo1[-1]
# vars.modelo1 <- vars.modelo1[-30]
formula.modelo1 <- as.formula(paste("shares ~ ", paste (vars.modelo1, collapse=" + "), sep=""))
modelo1 <- lm(formula.modelo1, data = datos.caso1)Ahora tenemos que constatar si el modelo 1 tiene o no heteroscedasticidad.
Para realizar la prueba de Breusch-Pagan, debemos constatar si el supuesto de normalidad se cumple. Para esto extraigamos los residuales con la función residuals() y efectuemos las pruebas de normalidad. En esta ocasión contamos con una muestra muy grande y la función ols_test_normality() del paquete olsrr no trabaja con muestras mayores a 5mil observaciones. Tenemos otras opciones como la función ks.test() del paquete base que permite también realizar la pruebas de Kolmogorov-Smirnov (Kolmogorov, 1933). Otra prueba de normalidad que se puede emplear es la de Jarque & Bera (1987). La función jarque.bera.test() del paquete tseries (Trapletti & Hornik, 2019).
# se extraen los residuales
res.modelo1 <- residuals(modelo1)
# pruebas de normalidad Kolmogorov-Smirnov
ks.test(res.modelo1, y= pnorm)##
## Asymptotic one-sample Kolmogorov-Smirnov test
##
## data: res.modelo1
## D = 0.76388, p-value < 2.2e-16
## alternative hypothesis: two-sided##
## Jarque Bera Test
##
## data: res.modelo1
## X-squared = 5856816137, df = 2, p-value < 2.2e-16Los residuales de este modelo no siguen una distribución normal. Por eso no son confiables los resultados de la prueba de Breusch-Pagan tradicional. Deberíamos entonces emplear la versión studentizada de la prueba propuesta por Koenker (1981).
# se carga la librería
library(lmtest)
# prueba de Breusch-Pagan studentizada
bptest(modelo1, studentize = TRUE)##
## studentized Breusch-Pagan test
##
## data: modelo1
## BP = 77.435, df = 29, p-value = 2.732e-06Con un 99% de confianza podemos rechazar la hipótesis de homoscedasticidad. Y para la prueba de White obtendremos el mismo resultado (¡Inténtenlo!).
Esto implica que no es posible hacer inferencia sobre el modelo obtenido anteriormente empleando los estimadores MCO y, por tanto, eliminar las variables no significativas como lo hicimos en el Capítulo 7. Corrijamos el problema empleando los estimadores HC3 (la propuesta por Davidson, Russell and MacKinnon (1993) y sugerida por Cribari-Neto (2004)).
# se carga la librería
library(sandwich)
# HC3 Davidson y MacKinnon (1993)
coeftest(modelo1, vcov = (vcovHC(modelo1))) ##
## t test of coefficients:
##
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.8442e+03 6.6768e+02 -4.2598 2.051e-05 ***
## timedelta 1.9130e+00 3.9576e-01 4.8336 1.346e-06 ***
## n_tokens_title 1.0971e+02 2.8458e+01 3.8552 0.0001158 ***
## n_tokens_content 2.7887e-01 2.8309e-01 0.9851 0.3245831
## num_hrefs 2.8515e+01 7.2929e+00 3.9100 9.245e-05 ***
## num_self_hrefs -5.5282e+01 1.7472e+01 -3.1639 0.0015576 **
## num_imgs 1.3052e+01 1.0088e+01 1.2938 0.1957366
## average_token_length -4.7317e+02 1.1117e+02 -4.2563 2.083e-05 ***
## num_keywords 5.3590e+01 3.3308e+01 1.6089 0.1076416
## data_channel_is_lifestyle -5.1992e+02 2.1633e+02 -2.4034 0.0162500 *
## data_channel_is_entertainment -6.4242e+02 1.5457e+02 -4.1560 3.245e-05 ***
## kw_min_min 2.1718e+00 1.1601e+00 1.8721 0.0612035 .
## kw_max_min 1.3041e-01 7.4355e-02 1.7539 0.0794588 .
## kw_avg_min -6.5956e-01 5.7532e-01 -1.1464 0.2516317
## kw_min_max -2.4948e-03 6.8268e-04 -3.6544 0.0002581 ***
## kw_min_avg -4.2826e-01 7.1964e-02 -5.9510 2.687e-09 ***
## kw_max_avg -2.4017e-01 2.3727e-02 -10.1224 < 2.2e-16 ***
## kw_avg_avg 1.9436e+00 1.3416e-01 14.4874 < 2.2e-16 ***
## self_reference_min_shares 2.2734e-02 1.3488e-02 1.6855 0.0918905 .
## self_reference_max_shares 3.4783e-03 1.9401e-03 1.7929 0.0729986 .
## weekday_is_monday 5.0072e+02 1.9006e+02 2.6345 0.0084305 **
## weekday_is_saturday 5.9181e+02 2.9903e+02 1.9791 0.0478112 *
## LDA_01 -2.0695e+02 2.5221e+02 -0.8205 0.4119116
## LDA_04 7.1847e+00 1.9218e+02 0.0374 0.9701780
## global_subjectivity 2.5751e+03 6.5230e+02 3.9477 7.903e-05 ***
## global_rate_positive_words -8.3508e+03 4.0782e+03 -2.0477 0.0405991 *
## rate_positive_words 3.8323e+02 4.1661e+02 0.9199 0.3576339
## avg_negative_polarity -1.5753e+03 7.8174e+02 -2.0151 0.0438985 *
## max_negative_polarity -4.1634e+02 8.1373e+02 -0.5117 0.6088976
## weekday_is_sunday 2.3910e+02 1.4072e+02 1.6992 0.0892925 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Noten que con la corrección, los resultados de la inferencia cambian si empleamos un nivel de confianza superior al 95%. En este caso no podemos emplear la función remueve.no.sinifica() que habíamos empleado en el Capítulo 7. Podemos modificar esta función para que tenga en cuenta la corrección HC3. . Creemos la función remueve.no.sinifica.HC3().
remueve.no.sinifica.HC3 <- function(modelo, p){
# extrae el dataframe
data <- modelo$model
# extraer el nombre de todas las variables X
all_vars <- all.vars(formula(modelo))[-1]
# extraer el nombre de la variables y
dep_var <- all.vars(formula(modelo))[1]
# Extraer las variables no significativas
# resumen del modelo
summ <- coeftest(modelo, vcov = (vcovHC(modelo)))
# extrae los valores p
pvals <- summ[, 4]
# creando objeto para guardar las variables no significativas
not_signif <- character()
not_signif<- names(which(pvals > p))
# Si hay alguna variable no-significativa
while(length(not_signif) > 0){
all_vars <- all_vars[!all_vars %in% not_signif[1]]
# nueva formula
myForm <- as.formula(paste(paste(dep_var, "~ "),
paste (all_vars, collapse=" + "), sep=""))
# re-escribe la formula
modelo <- lm(myForm, data= data)
# Extrae variables no significativas.
summ <- coeftest(modelo, vcov = (vcovHC(modelo)))
pvals <- summ[, 4]
not_signif <- character()
not_signif <- names(which(pvals > p))
not_signif <- not_signif[!not_signif %in% "(Intercept)"]
}
modelo.limpio <- modelo
return(modelo.limpio)
}El modelo 1 después de la eliminación de las variables explicativas no significativas (con la corrección HC3) se reporta en el Cuadro 10.2.
| MCO | HC3 | |
|---|---|---|
| (Intercept) | -2299.81*** | -2299.81*** |
| (542.51) | (627.58) | |
| timedelta | 2.01*** | 2.01*** |
| (0.29) | (0.31) | |
| n_tokens_title | 113.10*** | 113.10*** |
| (28.52) | (28.42) | |
| num_hrefs | 31.98*** | 31.98*** |
| (6.01) | (7.46) | |
| num_self_hrefs | -62.93*** | -62.93*** |
| (16.79) | (16.99) | |
| num_imgs | 19.29* | 19.29* |
| (7.59) | (7.86) | |
| average_token_length | -461.22*** | -461.22*** |
| (91.19) | (93.98) | |
| data_channel_is_lifestyle | -439.37 | -439.37* |
| (262.57) | (209.85) | |
| data_channel_is_entertainment | -775.43*** | -775.43*** |
| (156.01) | (130.64) | |
| kw_min_max | -0.00* | -0.00*** |
| (0.00) | (0.00) | |
| kw_min_avg | -0.42*** | -0.42*** |
| (0.07) | (0.07) | |
| kw_max_avg | -0.21*** | -0.21*** |
| (0.02) | (0.02) | |
| kw_avg_avg | 1.84*** | 1.84*** |
| (0.11) | (0.13) | |
| self_reference_max_shares | 0.01*** | 0.01** |
| (0.00) | (0.00) | |
| weekday_is_monday | 504.49** | 504.49** |
| (157.13) | (191.28) | |
| global_subjectivity | 2420.73*** | 2420.73*** |
| (675.57) | (608.44) | |
| avg_negative_polarity | -1777.66*** | -1777.66* |
| (514.28) | (693.15) | |
| is_weekend | 415.82* | 415.82* |
| (174.89) | (166.01) | |
| R2 | 0.02 | 0.02 |
| Adj. R2 | 0.02 | 0.02 |
| Num. obs. | 39644 | 39644 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
Ahora sigamos con el modelo 3: algoritmo Forward y criterio AIC. En este caso tenemos:
model3 <- ols_step_forward_aic(max.model)
# se extraen las variables del mejor modelo según el algoritmo
vars.modelo3 <- model3$predictors
# se construye la fórmula
formula.modelo3 <- as.formula(
paste("shares ~ ", paste (vars.modelo3, collapse=" + "),
sep=""))
# se estima el modelo con la fórmula construida
modelo3 <- lm( formula.modelo3 , data = datos.caso1)Ahora procedamos de nuevo a realizar las pruebas de heteroscedasticidad.
# se extraen los residuales
res.modelo3 <- residuals(modelo3)
# pruebas de normalidad Kolmogorov-Smirnov
ks.test(res.modelo3, y= pnorm)##
## Asymptotic one-sample Kolmogorov-Smirnov test
##
## data: res.modelo3
## D = 0.76089, p-value < 2.2e-16
## alternative hypothesis: two-sided##
## Jarque Bera Test
##
## data: res.modelo3
## X-squared = 5853868793, df = 2, p-value < 2.2e-16##
## studentized Breusch-Pagan test
##
## data: modelo3
## BP = 79.676, df = 28, p-value = 7.458e-07La versión studentizada de la prueba de Breusch-Pagan permite concluir con un 99% de confianza que hay heteroscedasticidad. Ahora realicemos la corrección HC3 y eliminemos las variables no significativas. El resultado se reporta en el Cuadro 10.3. Si comparamos estos resultados con los obtenidos en el Capítulo 7 (Cuadro 7.2) podemos ver diferencias entre las conclusiones para cada modelo. En este caso los modelos 1 y 3 no se encuentran anidados.
| Modelo 1(HC3) (\(R^2\) aj) | Modelo 3 (HC3) (AIC) | |
|---|---|---|
| (Intercept) | -2299.81*** | -2758.19*** |
| (627.58) | (657.64) | |
| timedelta | 2.01*** | 1.80*** |
| (0.31) | (0.38) | |
| n_tokens_title | 113.10*** | 114.35*** |
| (28.42) | (28.54) | |
| num_hrefs | 31.98*** | 27.54*** |
| (7.46) | (7.10) | |
| num_self_hrefs | -62.93*** | -54.99*** |
| (16.99) | (16.65) | |
| num_imgs | 19.29* | |
| (7.86) | ||
| average_token_length | -461.22*** | -306.46** |
| (93.98) | (106.18) | |
| data_channel_is_lifestyle | -439.37* | -541.12* |
| (209.85) | (217.86) | |
| data_channel_is_entertainment | -775.43*** | -869.03*** |
| (130.64) | (153.86) | |
| kw_min_max | -0.00*** | -0.00*** |
| (0.00) | (0.00) | |
| kw_min_avg | -0.42*** | -0.37*** |
| (0.07) | (0.08) | |
| kw_max_avg | -0.21*** | -0.21*** |
| (0.02) | (0.02) | |
| kw_avg_avg | 1.84*** | 1.75*** |
| (0.13) | (0.15) | |
| self_reference_max_shares | 0.01** | 0.00 |
| (0.00) | (0.00) | |
| weekday_is_monday | 504.49** | 471.28* |
| (191.28) | (188.72) | |
| global_subjectivity | 2420.73*** | 2394.78*** |
| (608.44) | (632.71) | |
| avg_negative_polarity | -1777.66* | -1498.51* |
| (693.15) | (705.53) | |
| is_weekend | 415.82* | |
| (166.01) | ||
| self_reference_min_shares | 0.02 | |
| (0.01) | ||
| LDA_03 | 538.36 | |
| (319.06) | ||
| weekday_is_saturday | 587.48* | |
| (297.81) | ||
| n_tokens_content | 0.31 | |
| (0.24) | ||
| LDA_02 | -703.49*** | |
| (199.44) | ||
| global_rate_positive_words | -10386.42** | |
| (3649.61) | ||
| min_positive_polarity | -1932.63** | |
| (738.72) | ||
| num_keywords | 58.90 | |
| (32.31) | ||
| kw_max_min | 0.12 | |
| (0.07) | ||
| abs_title_sentiment_polarity | 605.35* | |
| (261.64) | ||
| abs_title_subjectivity | 621.80 | |
| (330.31) | ||
| kw_avg_min | -0.56 | |
| (0.56) | ||
| kw_min_min | 1.72 | |
| (1.15) | ||
| R2 | 0.02 | 0.02 |
| Adj. R2 | 0.02 | 0.02 |
| Num. obs. | 39644 | 39644 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
10.3.2 Stepwise backward
De manera similar en el Cuadro 10.4 se presentan los resultados de emplear el algoritmo stepwise backward y tras limpiar las variables no significativas con la corrección HC3 (con un 95% de confianza)104. Previamente puedes mostrar que estos dos modelos tienen un problema de heteroscedasticidad. Estos resultados implican que el modelo 6 está anidado en el 4 (pero no en el 1 o 3).
| Modelo 4 (HC3) (\(R^2\) aj) | Modelo 6 (HC3) (AIC) | |
|---|---|---|
| (Intercept) | -2237.44*** | 626.97** |
| (545.05) | (235.66) | |
| timedelta | 2.01*** | |
| (0.29) | ||
| n_tokens_title | 111.21*** | |
| (28.53) | ||
| num_hrefs | 30.46*** | |
| (6.01) | ||
| num_self_hrefs | -56.06*** | |
| (16.79) | ||
| num_imgs | 17.01* | |
| (7.64) | ||
| average_token_length | -252.40** | |
| (77.56) | ||
| data_channel_is_entertainment | -826.41*** | |
| (158.87) | ||
| kw_min_max | -0.00** | |
| (0.00) | ||
| kw_min_avg | -0.39*** | |
| (0.07) | ||
| kw_max_avg | -0.20*** | |
| (0.02) | ||
| kw_avg_avg | 1.75*** | |
| (0.12) | ||
| self_reference_max_shares | 0.01*** | |
| (0.00) | ||
| weekday_is_monday | 500.66** | |
| (157.14) | ||
| LDA_03 | 693.45** | 3962.65*** |
| (247.65) | (257.26) | |
| avg_negative_polarity | -2196.25*** | |
| (492.63) | ||
| is_weekend | 408.83* | |
| (174.79) | ||
| weekday_is_saturday | 717.79** | |
| (241.93) | ||
| weekday_is_sunday | 320.35 | |
| (230.01) | ||
| LDA_04 | 1580.75*** | |
| (261.74) | ||
| LDA_01 | 1037.61*** | |
| (304.61) | ||
| data_channel_is_bus | -703.50** | |
| (256.18) | ||
| kw_avg_max | 0.00*** | |
| (0.00) | ||
| LDA_00 | 2321.69*** | |
| (384.26) | ||
| min_negative_polarity | -741.71*** | |
| (202.21) | ||
| self_reference_avg_sharess | 0.02*** | |
| (0.00) | ||
| R2 | 0.02 | 0.01 |
| Adj. R2 | 0.02 | 0.01 |
| Num. obs. | 39644 | 39644 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
10.3.3 Combinando forward y backward
Y finalmente, el Cuadro 10.5 se presentan los resultados de emplear el algoritmo combinado y tras limpiar las variables no significativas y la corrección HC3 (con un 95% de confianza). (Recuerda hacer las pruebas de heteroscedasticidad para cada modelo). Los modelos 7 y 9 no están anidados.
| Modelo 7 (HC3) (\(R^2\) aj) | Modelo 9 (HC3) (AIC) | |
|---|---|---|
| (Intercept) | -2409.25*** | -2710.78*** |
| (482.26) | (637.40) | |
| timedelta | 1.86*** | 1.95*** |
| (0.30) | (0.30) | |
| n_tokens_title | 111.49*** | 118.10*** |
| (28.55) | (28.84) | |
| num_hrefs | 30.03*** | 33.16*** |
| (5.76) | (5.95) | |
| num_self_hrefs | -55.72*** | -62.43*** |
| (16.80) | (16.88) | |
| data_channel_is_entertainment | -899.25*** | -818.21*** |
| (161.83) | (160.28) | |
| kw_min_max | -0.00** | -0.00* |
| (0.00) | (0.00) | |
| kw_min_avg | -0.38*** | -0.36*** |
| (0.07) | (0.07) | |
| kw_max_avg | -0.19*** | -0.20*** |
| (0.02) | (0.02) | |
| kw_avg_avg | 1.70*** | 1.77*** |
| (0.12) | (0.11) | |
| self_reference_max_shares | 0.01*** | 0.01*** |
| (0.00) | (0.00) | |
| weekday_is_monday | 490.85** | 434.38** |
| (157.17) | (154.81) | |
| LDA_02 | -826.89*** | -787.20** |
| (242.04) | (245.91) | |
| LDA_03 | 749.93** | |
| (247.89) | ||
| global_rate_positive_words | -8507.20* | -10992.61** |
| (3590.83) | (4141.14) | |
| min_positive_polarity | -2189.55** | -2150.64* |
| (830.97) | (898.59) | |
| avg_negative_polarity | -1870.00*** | -1675.73** |
| (470.20) | (519.66) | |
| abs_title_sentiment_polarity | 491.22 | 661.54* |
| (260.18) | (283.58) | |
| is_weekend | 427.80* | |
| (174.86) | ||
| average_token_length | -336.56*** | |
| (95.05) | ||
| global_subjectivity | 2709.75*** | |
| (752.14) | ||
| data_channel_is_lifestyle | -556.75* | |
| (265.95) | ||
| num_keywords | 66.53* | |
| (33.46) | ||
| abs_title_subjectivity | 658.22 | |
| (341.63) | ||
| R2 | 0.02 | 0.02 |
| Adj. R2 | 0.02 | 0.02 |
| Num. obs. | 39644 | 39644 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
10.4 Comparación de modelos
En resumen, contamos con 6 modelos con las variables explicativas que se representan con una X en el Cuadro 10.6. El modelo 6 está anidado en el modelo 4 y en el 7. Puedes probar rápidamente que el modelo 4 es mejor que el 6 y el 7 es mejor que el 4. Por otro lado, el modelo 9 y el 3 son los mismos. Así, descartaremos el modelo 6 y el 9 del análisis. Los otros modelos no se encuentran anidados.
| Variable | modelo 1 | modelo 3 | modelo 4 | modelo 6 | modelo 7 | modelo 9 |
|---|---|---|---|---|---|---|
| timedelta |
|
X | X |
|
X | X |
| n_tokens_title | X | X | X |
|
X | X |
| n_tokens_content |
|
|
|
|
|
X |
| num_hrefs | X | X | X |
|
X | X |
| num_self_hrefs | X | X | X |
|
X | X |
| num_keywords |
|
X |
|
|
|
X |
| average_token_length | X | X | X |
|
|
X |
| num_imgs | X |
|
X |
|
|
|
| data_channel_is_lifestyle |
|
|
|
|
|
X |
| data_channel_is_entertainment | X | X | X |
|
X | X |
| kw_min_max | X | X | X |
|
X | X |
| kw_min_avg | X | X | X |
|
X | X |
| kw_max_avg | X | X | X |
|
X | X |
| kw_avg_avg | X | X | X |
|
X | X |
| self_reference_max_shares | X | X | X |
|
X | X |
| data_channel_is_lifestyle | X | X |
|
|
|
|
| weekday_is_monday | X | X | X |
|
X | X |
| is_weekend |
|
|
X |
|
X |
|
| LDA_02 |
|
X |
|
|
X | X |
| LDA_03 |
|
|
X | X | X |
|
| LDA_04 |
|
|
|
|
|
|
| global_rate_positive_words |
|
X |
|
|
X | X |
| global_subjectivity | X | X |
|
|
|
X |
| min_positive_polarity |
|
X |
|
|
X | X |
| avg_negative_polarity | X | X | X |
|
X | X |
| abs_title_sentiment_polarity |
|
X |
|
|
X | X |
| abs_title_subjectivity |
|
X |
|
|
|
X |
| Fuente: elaboración propia. |
De esta manera, tendremos que comparar estos modelos con pruebas de modelos no anidados empleando la prueba J con corrección HC3. La prueba de Cox no es posible implementarla con H.C.. A continuación, se presenta el código ajustado de la Prueba J para la corrección H.C. empleando la función jtest() del AER (Kleiber & Zeileis, 2008).
library(AER)
# comparación de modelos no anidados
J.res1.3 <- jtest(modelo1, modelo3, vcov. = vcovHC)Empecemos comparando todos los modelos con la prueba J. En el Cuadro 10.7 se reportan los valores p de las pruebas J que permiten probar la hipótesis nula de que el modelo de la fila es mejor que el de la columna.
| Modelo 1 | Modelo 3 | Modelo 4 | Modelo 7 | |
|---|---|---|---|---|
| Modelo 1 | NA | 0.001 | 0.072 | 0.000 |
| Modelo 3 | 0.124 | NA | 0.115 | 0.089 |
| Modelo 4 | 0.000 | 0.001 | NA | 0.000 |
| Modelo 7 | 0.000 | 0.003 | 0.004 | NA |
| Fuente: elaboración propia. |
Si miramos la primera fila, con un 99% de confianza, podemos concluir que el modelo 1 no es mejor que los modelos 3 y 7105. La hipótesis de que el modelo 1 es mejor que el 4 no se puede rechazar. Si miramos la primera columna, podemos ver como la nula de que los otros modelos son mejores que el 1 se pueden rechazar con un 99% de confianza. Es decir, para las comparaciones de los modelos 3 y 7 con el modelo 1 (y viceversa) la prueba no es concluyente. Un resultado similarmente contradictorio lo encontramos para las parejas de modelos 3 y 4106 y la pareja de modelos 4 y 7. Para la comparación del modelo 4 con el 1, la prueba J concluye que el modelo 1 es mejor que el 4. La prueba J también concluye en favor que el modelo 3 frente al 7.
Ahora empleemos las métricas AIC y BIC. Estas medidas no se ven afectadas por la presencia de heteroscedasticidad ni la multicolinealidad. No obstante, el \(R^2\) ajustado al depender del \(R^2\) podría verse afectado en presencia de una multicolinealidad fuerte. Los resultados se reportan en el Cuadro 10.8.
| AIC | BIC | |
|---|---|---|
| Modelo 1 | 853920.0 | 854083.2 |
| Modelo 3 | 853858.5 | 854116.1 |
| Modelo 4 | 853925.2 | 854079.7 |
| Modelo 7 | 853921.9 | 854093.6 |
| Fuente: elaboración propia. |
El AIC sugiere que el mejor modelo es el 3, mientras que el BIC selecciona el 4. Poniendo todo junto, el mejor modelo será el modelo 3 (que es igual al 9) el cuál se reporta en el Cuadro 10.9. Noten que estadísticamente el modelo 3 es mejor que el 7 y el modelo 4 no es mejor que el 1; pero al comparar directamente los modelos 3 y 4, la prueba J no es concluyente. Esto hace que la decisión por el modelo 3 no sea una tarea fácil y otro científico de datos podría seleccionar el modelo 4 en vez del 3. ¡Esta no es una decisión sencilla!
| HC3 | |
|---|---|
| (Intercept) | -2758.19*** |
| (657.64) | |
| kw_avg_avg | 1.75*** |
| (0.15) | |
| self_reference_min_shares | 0.02 |
| (0.01) | |
| kw_max_avg | -0.21*** |
| (0.02) | |
| kw_min_avg | -0.37*** |
| (0.08) | |
| timedelta | 1.80*** |
| (0.38) | |
| num_hrefs | 27.54*** |
| (7.10) | |
| n_tokens_title | 114.35*** |
| (28.54) | |
| data_channel_is_entertainment | -869.03*** |
| (153.86) | |
| LDA_03 | 538.36 |
| (319.06) | |
| avg_negative_polarity | -1498.51* |
| (705.53) | |
| average_token_length | -306.46** |
| (106.18) | |
| global_subjectivity | 2394.78*** |
| (632.71) | |
| weekday_is_monday | 471.28* |
| (188.72) | |
| kw_min_max | -0.00*** |
| (0.00) | |
| weekday_is_saturday | 587.48* |
| (297.81) | |
| num_self_hrefs | -54.99*** |
| (16.65) | |
| n_tokens_content | 0.31 |
| (0.24) | |
| LDA_02 | -703.49*** |
| (199.44) | |
| global_rate_positive_words | -10386.42** |
| (3649.61) | |
| min_positive_polarity | -1932.63** |
| (738.72) | |
| self_reference_max_shares | 0.00 |
| (0.00) | |
| data_channel_is_lifestyle | -541.12* |
| (217.86) | |
| num_keywords | 58.90 |
| (32.31) | |
| kw_max_min | 0.12 |
| (0.07) | |
| abs_title_sentiment_polarity | 605.35* |
| (261.64) | |
| abs_title_subjectivity | 621.80 |
| (330.31) | |
| kw_avg_min | -0.56 |
| (0.56) | |
| kw_min_min | 1.72 |
| (1.15) | |
| R2 | 0.02 |
| Adj. R2 | 0.02 |
| Num. obs. | 39644 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
Antes de pasar a sacar conclusiones, procedamos a determinar si el mejor modelo tiene o no multicolinealidad. Noten que el \(VIF\) depende de la matriz de varianzas y covarianzas de los estimadores MCO y en presencia de heteroscedasticidad, éstos no son confiables. Así no podemos emplearlos en esta situación. Así que nos concentraremos en la prueba de Belsley et al. (1980) también conocida como la prueba Kappa.
El siguiente código permite hacer la prueba.
XTX <- model.matrix(modelo3)
e <- eigen(t(XTX) %*% XTX)
lambda.1 <- max(e$val)
lambda.k <- min(e$val)
kappa <- sqrt(lambda.1/lambda.k)
kappa## [1] 4323614Este estadístico es muy grande (\(\kappa\) = 4.323614^{6}). Esta prueba sugiere la existencia de un problema serio de multicolinealidad. Nota que los síntomas del problema de multicolinealidad no estaban presentes. No obstante la prueba si detecta un problema serio. Solucionar este problema no será fácil, pues no podemos emplear el \(VIF\) para eliminar variables. Así que la interpretación que realicemos de los coeficientes puede tener problemas.
Así continuaremos con este problema, teniendo precaución con las conclusiones que saquemos.
10.5 Identificación de la variable más importante
Como lo discutimos, una pregunta habitual cuando estamos haciendo analítica diagnóstica es ¿cuál variable es la más importante para explicar la variable dependiente? en el Capítulo 7 discutimos dos formas de hacer esto empleando el aumento en el \(R^2\) que se obtiene al adicionar el respectivo regresor dado que ya están en el modelo las otras \(k-2\) variables explicativas y con los coeficientes estandarizados. En este caso no es posible emplear el \(R^2\), pues el problema de multicolinealidad podría afectar esta métrica. Así que es mejor descartar esta aproximación.
Por otro lado, también hay que reconocer que en presencia de heteroscedasticidad los coeficientes estandarizados, como los discutimos en el Capítulo 7, se ven afectados. Es decir, al tener un error heteroscedástico, tendremos que la variable dependiente también tiene una varianza no constante. Y por tanto, emplear \(s_{y}\) no sería adecuado. Pero podemos emplear el estimador H.C. para tener un estimador de la desviación estándar de la variable dependiente que no sea constante para toda la muestra. Esto no lo podemos hacer con el paquete relaimpo (Grömping, 2006), pero sí lo podemos hacer con el el paquete jtools (J. A. Long, 2020) como lo veremos a continuación.
10.6 Generación de visualizaciones de los resultados
Ahora veamos cómo se pueden presentar los resultados de una manera más amigable y en presencia de heteroscedasticidad. Las visualizaciones que generamos en el Capítulo 7 emplean las estimaciones del modelo por MCO, pero podemos modificarlas rápidamente para incluir la corrección H.C..
Seguiremos empleando el paquete jtools (J. A. Long, 2020) para visualizar los resultados del objeto de clase lm pero con la corrección de heteroscedasticidad. La función plot_summs() tiene el argumento robust que permite incluir la corrección H.C. o H.A.C.. En este caso el siguiente código genera la Figura 10.1.
Figura 10.1: Visualización de los coeficientes del mejor modelo sus intervalos de confianza empleando la corrección HC3
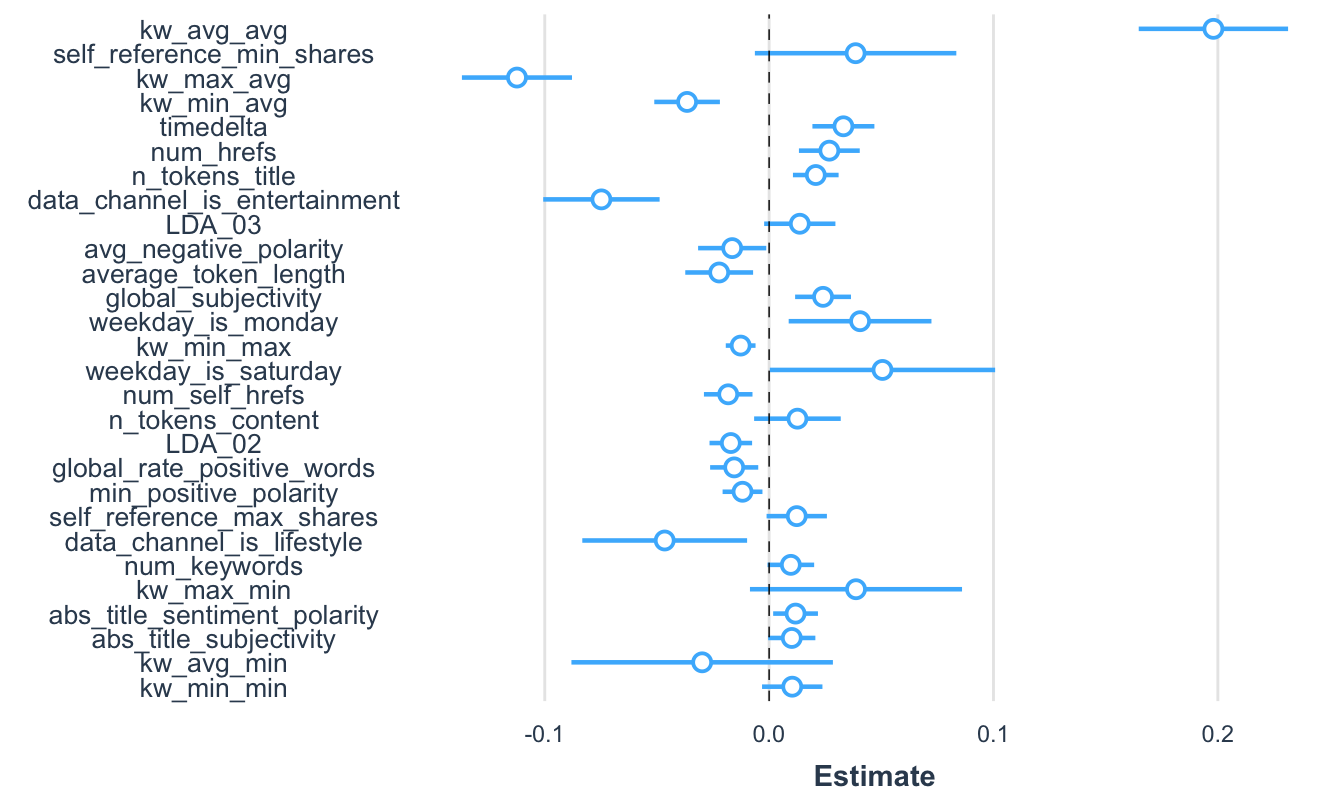
Este gráfico permite ver los coeficientes y sus respectivos intervalos de confianza con la corrección HC3. También podemos graficar los coeficientes estandarizados teniendo en cuenta la corrección HC3, de la siguiente manera:
Figura 10.2: Visualización de los coeficientes estandarizados del mejor modelo sus intervalos de confianza empleando la corrección HC3
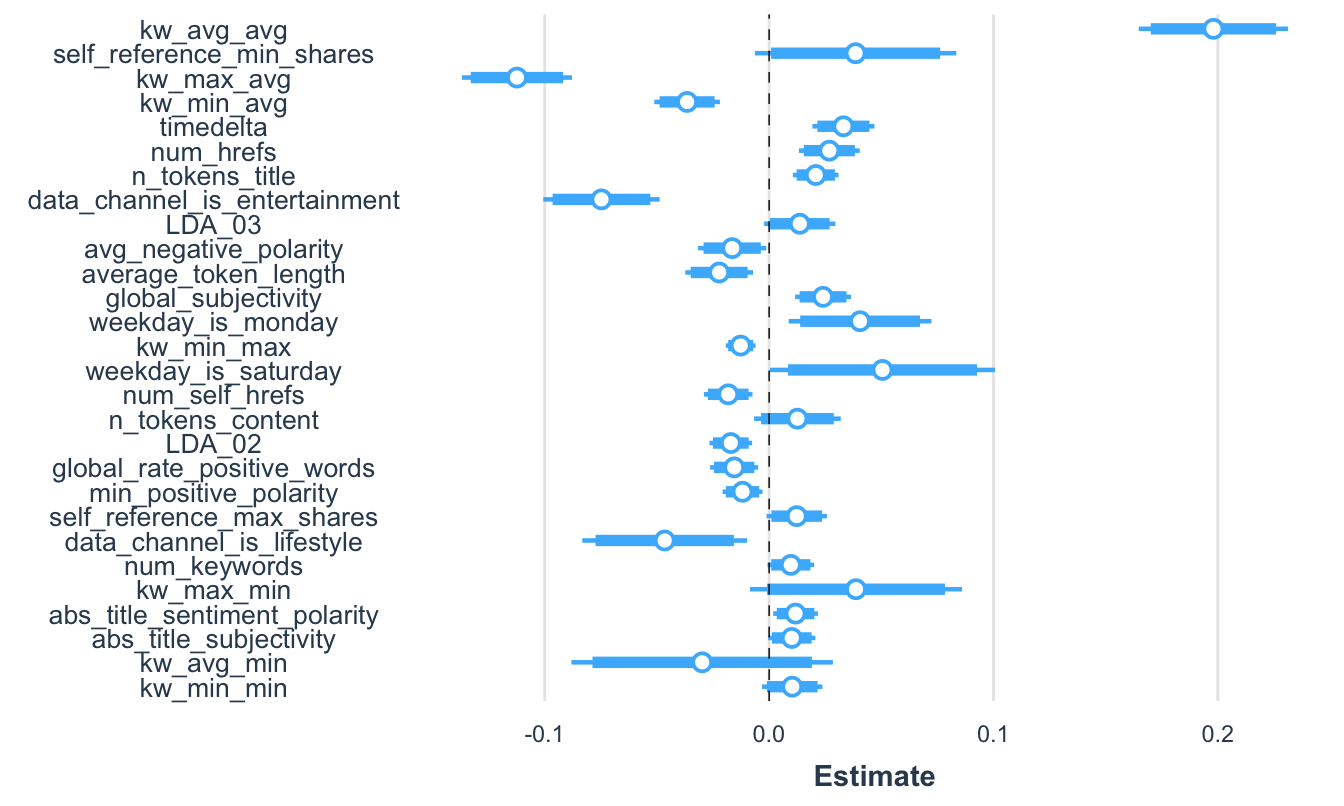
La Figura 10.2 presenta estos resultados. Ahora ya estás listo para proceder a generar las recomendaciones al editor. ¿Qué recomiendan?
10.6.1 Comentarios Finales
En este capítulo hemos seguido el proceso paso a paso para responder una pregunta de negocio empleando un modelo de regresión para hacer analítica diagnóstica . A diferencia de lo realizado en el Capítulo 7, esta vez realizamos el chequeo del cumplimiento de los supuestos del Teorema de Gauss-Markov y ahora sí podemos estar seguros de sacar conclusiones con nuestro modelo.
Referencias
Los datos se pueden descargar de la página web del libro: https://www.icesi.edu.co/editorial/modelo-clasico/.↩︎
Pista: Al estimar el modelo 6 (
modelo6) empleando el códigomodelo6 <- ols_step_backward_aic(max.model)es posible que se obtenga un mensaje de error. Para solucionar el problema pueden reestimar elmax.modeleliminando las variables"weekday_is_sundayyis_weekend. Esto solucionará el problema de multicolinealidad perfecta que se estaba generando. ¡Inténtalo!↩︎Noten que las hipótesis nula asociadas a los valores p reportados en la primera fila del Cuadro 10.7 corresponde a que el modelo 1 es mejor al modelo de la respectiva columna. Y esa hipótesis nula se puede rechazar en todos los casos.↩︎
Al comparar el modelo 3 con el 4, se encuentra que se puede rechazar la nula de que el modelo 3 es mejor que el 4 con un 99% de confianza. Al mismo tiempo, se puede rechazar la nula de que el modelo 4 es mejor que el 3. Es decir, la prueba no es concluyente.↩︎