6 Selección automática de modelos
Objetivos del capítulo
Al finalizar este capítulo, el lector estará en capacidad de:
- Explicar en sus propias palabras las opciones que existen para seleccionar automáticamente el mejor modelo
- Seleccionar el mejor modelo de regresión dada una cantidad grande de regresores empleando R.
6.1 Introducción
En los capítulos anteriores hemos discutido cómo seleccionar el mejor modelo. Para ejemplificar la selección de modelos hemos empleado casos en los que se cuenta con un número relativamente reducido de posibles variables explicativas. Pero en la práctica es común que esto no ocurra, el científico de datos típicamente se encuentra con problemas en los que se conoce claramente la variable que se quiere explicar58 o predecir59 (variable dependiente) y un conjunto grande de posibles variables explicativas. Pero no sabemos cuáles variables si son importantes y cuáles no al momento de explicar nuestra variable de interés.
En general, si hay \(k-1\) variables independientes potenciales (además del intercepto) que pueden explicar o predecir a la variable dependiente, entonces hay \(2^{\left( {k - 1} \right)}\) subconjuntos de variables explicativas posibles para explicar60 los cambios en la variable dependiente. Es decir, existen \(2^{\left( {k - 1} \right)}\) modelos que pueden ser candidatos a ser el mejor modelo para explicar la variable dependiente. En la práctica desconocemos cuál de esos modelos es el correcto. Y por tanto, tendríamos que probar todos los posibles modelos para encontrar el correcto61. Por ejemplo, si tenemos 10 posibles variables explicativas (\(\left(k-1\right) = 10\)) entonces los posibles modelos serán \({2^{\left( {k - 1} \right)}} = {2^{\left( 10 \right)}} =\) \(1024\). Si se tienen 20 variables candidatas, el número de posibles subconjuntos es de \(1.048576\times 10^{6}\) (más de un millón de posibles modelos). Si son 25 posibles variables, entonces son \(3.3554432\times 10^{7}\). Es decir, aproximadamente 33 millones y medio de posibles modelos.
Así, si se cuenta con muchas variables candidatos a ser explicativas no es viable calcular todos los posibles modelos y compararlos. No obstante, si las variables son relativamente pocas podría ser viable estimar todos los posibles modelos y compararlos. Recordemos que en el capítulo anterior estudiamos cómo comparar modelos para seleccionar al mejor empleando métricas como el \(R^2\) ajustado, los criterios de información \(AIC\) o \(BIC\) (Ver Sección 4.2 y pruebas estadísticas de modelos anidados (Ver Sección 4.3.1) y no anidados (Ver Sección 4.2).
En este capítulo discutiremos diferentes algoritmos para encontrar el mejor modelo (o por lo menos el modelo para ser un buen candidato a mejor modelo) de regresión múltiple que se ajuste a unos datos determinados cuando se cuenta con un conjunto relativamente grande de posibles variables explicativas. Estos algoritmos emplean como base los conceptos que ya hemos estudiado en los capítulos anteriores. Así, entraremos directamente a una aplicación para mostrar estas aproximaciones al problema de seleccionar el mejor modelo.
Emplearemos unos datos simulados para una variable dependiente (\(y_i\)) y 25 posibles variables explicativas \(xj_{i}\) donde \(j=1,2,...,25\). Para cada variable se simulan 150 observaciones \(i=1,2,...,150\). El modelo del que se simulan los datos incluye las variables \(x1\) a \(x25\) únicamente y los coeficientes son iguales a 1 para todos los casos (nota que en la vida real no conocemos esta información). La información se encuentra disponible en el archivo DATOSautoSel.txt62.
Carguemos los datos en un objeto que llamaremos datos y verifiquemos la clase del objeto leído y de cada una de las variables en el objeto.
# Leer de datos
datos <- read.table("./Data/DATOSautoSel.txt", header = TRUE)
# Mirar clase de las columnas
str(datos)## 'data.frame': 150 obs. of 26 variables:
## $ x1 : num 5.92 4.57 5.44 4.91 5.7 ...
## $ x2 : num 6.51 3.64 5.5 5.85 6.33 ...
## $ x3 : num 6.88 4.38 6.6 6.54 5.28 ...
## $ x4 : num 5.16 5.06 4.48 5.71 5.02 ...
## $ x5 : num 6.42 3.17 4.99 4.67 4.23 ...
## $ x6 : num 5.83 4.6 5.52 5.26 5.77 ...
## $ x7 : num 5.36 4.58 6.24 5.79 4.47 ...
## $ x8 : num 6.63 4.17 5.4 5.07 4.77 ...
## $ x9 : num 5.73 4.26 5.46 5.5 6.06 ...
## $ x10: num 6.11 4.44 5.57 4.64 5.5 ...
## $ x11: num 4.82 5.58 5.04 6.33 3.37 ...
## $ x12: num 6.11 5.71 5.87 4.85 5.45 ...
## $ x13: num 6.61 5.07 5.02 6.13 6.35 ...
## $ x14: num 4.82 4.25 4.91 6.41 5.38 ...
## $ x15: num 6.3 4.55 4.83 4.22 5.75 ...
## $ x16: num 5.45 4.12 5.23 5.33 4.84 ...
## $ x17: num 6.42 4.2 4.85 6.06 5.41 ...
## $ x18: num 6.71 4.8 5.31 5.68 4.56 ...
## $ x19: num 5.56 4.16 5.03 5.29 5.54 ...
## $ x20: num 7.15 5.64 5.15 5.29 6.38 ...
## $ x21: num 6.47 3.93 4.93 5.04 5.45 ...
## $ x22: num 6.31 4.61 5.33 4.55 5.44 ...
## $ x23: num 5.41 4.1 4.58 5.4 4.65 ...
## $ x24: num 5.92 5.64 4.97 6.02 5.5 ...
## $ x25: num 5.12 5.62 5.3 5.87 5.12 ...
## $ y : num 42.8 30.4 36.3 36.6 38.3 ...## x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11 x12 x13
## 1 5.925 6.512 6.883 5.157 6.420 5.833 5.356 6.626 5.730 6.108 4.817 6.106 6.613
## 2 4.565 3.638 4.378 5.056 3.165 4.598 4.576 4.171 4.259 4.443 5.582 5.713 5.069
## x14 x15 x16 x17 x18 x19 x20 x21 x22 x23 x24 x25
## 1 4.821 6.296 5.449 6.425 6.705 5.564 7.154 6.466 6.309 5.407 5.915 5.119
## 2 4.247 4.548 4.125 4.196 4.800 4.163 5.636 3.931 4.612 4.097 5.638 5.616
## y
## 1 42.799
## 2 30.372## [1] "data.frame"En este caso, tenemos 25 posibles variables, entonces son \(2^{25}\) (aproximadamente 33.6 millones) posibles modelos.
Este capítulo está compuesto de dos partes. La primera, emplea un número reducido de variables (\(\left( {k - 1} \right) = 10\)) para mostrar una aproximación que emplea “fuerza bruta”. Es decir, se evalúan todos los posibles modelos y se comparan. En la segunda parte veremos diferentes algoritmos para encontrar el un modelo para ser candidato a mejor modelo cuando se tienen muchas posibles variables explicativas, y para esta sección sí emplearemos las 25 variables.
6.2 Empleando “fuerza bruta”
La primera aproximación que estudiaremos es viable cuando se cuenta con pocas potenciales variables para explicar la variable dependiente (\(y\)). En este caso, se puede emplear la “fuerza bruta” de los computadores para encontrar el mejor modelo. Es decir, se puede emplear la capacidad de cómputo para calcular todos los posibles modelos y compararlos.
Supongamos que contamos con las 10 primeras variables (\(\left( {k - 1} \right) = 10\)) de nuestros datos simulados para explicar a \(y\). Así, en este caso se compararán \(1024\) modelos. No empleamos todas las variables explicativas para ahorrar tiempo en la estimación de todos los modelos y para hacer viable este ejercicio. Creemos un objeto de nombre datos2 de clase data.frame con solo las variables que son de nuestro interés.
## x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 y
## 1 5.925 6.512 6.883 5.157 6.420 5.833 5.356 6.626 5.730 6.108 42.799
## 2 4.565 3.638 4.378 5.056 3.165 4.598 4.576 4.171 4.259 4.443 30.372Empecemos por estimar un modelo lineal con todas las variables potenciales. Como sabemos esto se puede hacer con la función lm() del paquete básico de R. Recuerda que esta función incluirá siempre un intercepto a menos que se le indique lo contrario, empleando en la especificación del modelo un -1.
Estimemos un modelo con todas las posibles variables contenidas en el objeto datos2 y guardemos los resultados de la estimación en un objeto llamado modelo.
##
## Call:
## lm(formula = y ~ ., data = datos2)
##
## Residuals:
## Min 1Q Median 3Q Max
## -7.4754 -1.5134 0.0137 1.4273 8.0533
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 11.21741 1.40780 7.968 5.24e-13 ***
## x1 0.65111 0.26894 2.421 0.016768 *
## x2 1.72908 0.28714 6.022 1.46e-08 ***
## x3 0.94195 0.27727 3.397 0.000888 ***
## x4 0.92954 0.26551 3.501 0.000623 ***
## x5 0.94561 0.25956 3.643 0.000379 ***
## x6 0.07626 0.26472 0.288 0.773712
## x7 0.01759 0.28152 0.062 0.950278
## x8 -0.24513 0.27869 -0.880 0.380598
## x9 -0.54115 0.27812 -1.946 0.053705 .
## x10 0.22042 0.28886 0.763 0.446720
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.496 on 139 degrees of freedom
## Multiple R-squared: 0.7168, Adjusted R-squared: 0.6964
## F-statistic: 35.18 on 10 and 139 DF, p-value: < 2.2e-16Noten que de acuerdo a los resultados, las variables de \(x1\) a \(x5\) son estadísticamente significativas (nivel de confianza del 95%)63. Las otras variables no son significativas.
Ahora podemos investigar todos los \(1024\) posibles modelos. Esto lo podemos hacer con la función ols_step_all_possible() del paquete olsrr (Hebbali, 2020). Esta función requiere típicamente de un solo argumento que corresponde a un objeto de clase lm que contenga el modelo más grande posible. Guardemos los resultados de ejecutar esta función en el objeto mod64.
# Instalar paquete si no se tiene install.packages('olsrr') cargar librería
library(olsrr)
# se estiman todos los posibles modelos
mod <- ols_step_all_possible(modelo)
# attributos del nuevo objeto
str(mod)## Classes 'ols_step_all_possible' and 'data.frame': 1023 obs. of 14 variables:
## $ mindex : int 1 2 3 4 5 6 7 8 9 10 ...
## $ n : int 1 1 1 1 1 1 1 1 1 1 ...
## $ predictors: chr "x2" "x5" "x4" "x3" ...
## $ rsquare : num 0.55 0.403 0.382 0.367 0.305 ...
## $ adjr : num 0.546 0.399 0.378 0.363 0.3 ...
## $ predrsq : num 0.537 0.384 0.364 0.351 0.283 ...
## $ cp : num 75.1 147.2 157.3 164.5 195 ...
## $ aic : num 764 807 812 815 829 ...
## $ sbic : num 337 378 383 387 401 ...
## $ sbc : num 773 816 821 824 838 ...
## $ msep : num 1396 1851 1914 1960 2153 ...
## $ fpe : num 9.43 12.5 12.93 13.24 14.54 ...
## $ apc : num 0.463 0.614 0.635 0.65 0.714 ...
## $ hsp : num 0.0633 0.0839 0.0868 0.0889 0.0976 ...En el objeto mod se encuentran varios estadísticos que permiten resumir las características estadísticas de todos los modelos estimados. Con un gráfico podemos resumir esta información.
Figura 6.1: Métricas de bondad de ajuste para los diferentes modelos estimados
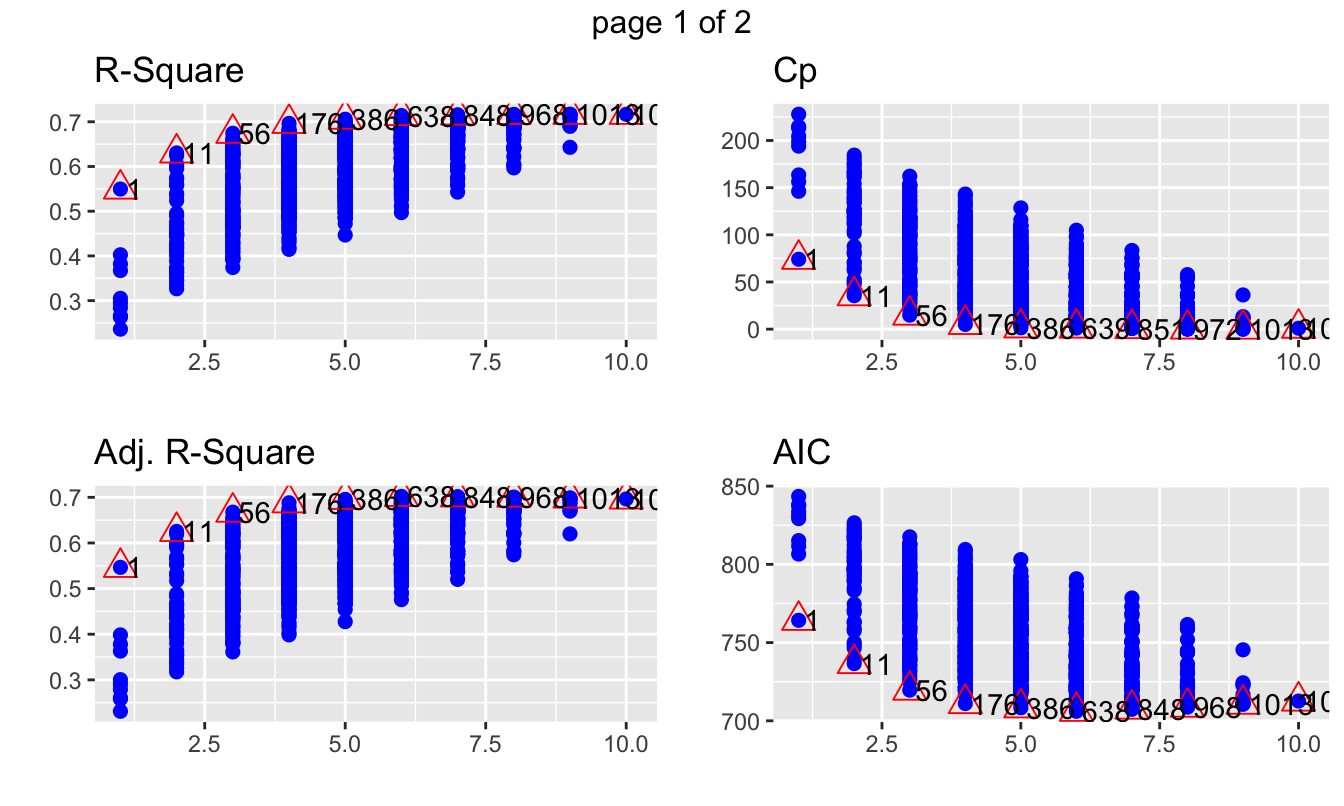
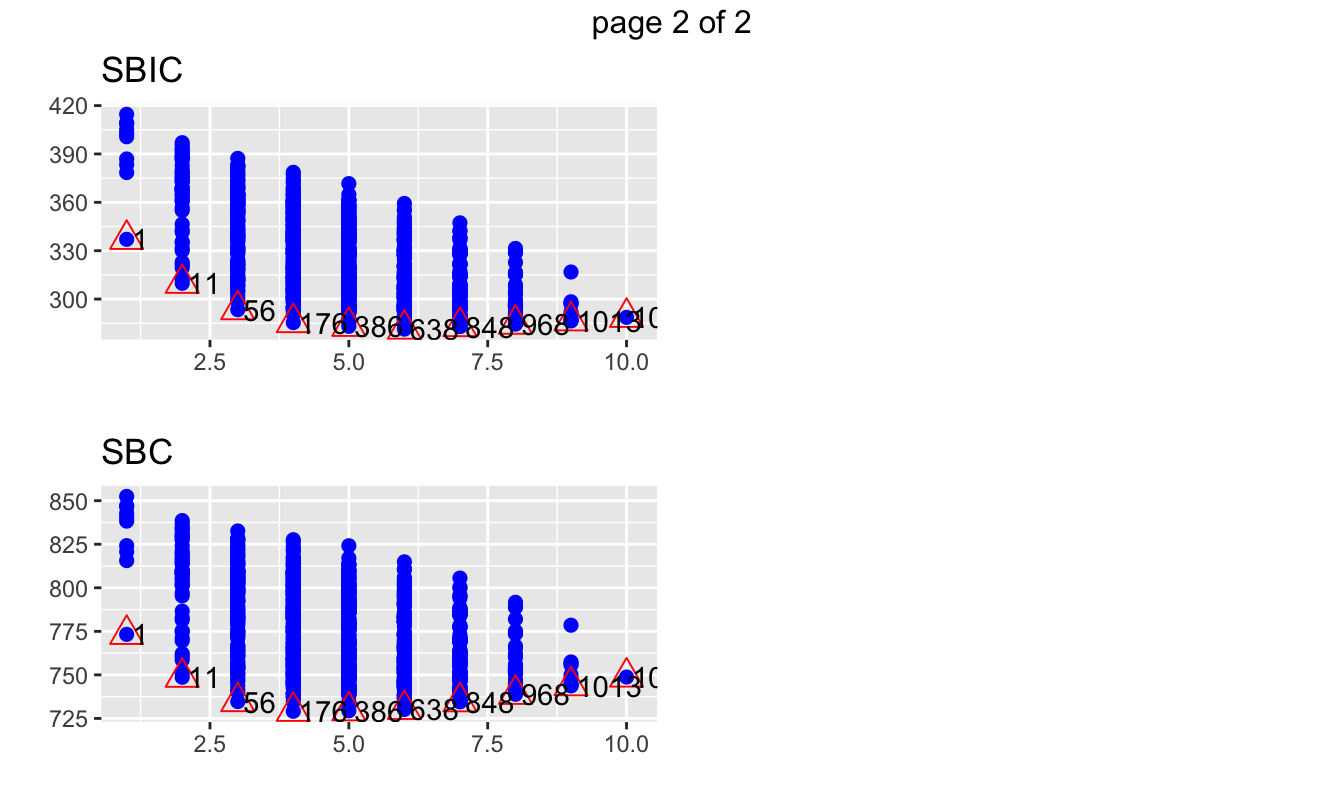
En el eje horizontal podemos ver el números de variables empleadas en cada modelo, mientras que en el eje vertical encontramos el valor de la métrica. El triángulo muestra el modelo que maximiza o minimiza el valor de la métrica para cada uno de los posibles número de variables. Concentrémonos en el \(R^2\) ajustado (se desea maximizar) y los criterios de información (se desean minimizar): AIC, SBC (o o también conocido como BIC). Recuerda que estas tres métricas penalizan la inclusión de más variables en el modelo.
Empleando el criterio del \(R^2\) ajustado podemos llegar a la conclusión que el mejor modelo es uno que emplea 6 variables (x1 x2 x3 x4 x5 x9). De hecho, ese modelo corresponde al modelo número 638 de todos los estimados. Esta información se puede obtener de la siguiente manera:
## [1] 638## [1] 6## [1] "x1 x2 x3 x4 x5 x9"Empleando el criterio de información de AIC encontramos que el mejor modelo es el mismo.
## [1] 638## [1] 6## [1] "x1 x2 x3 x4 x5 x9"Para el caso del BIC el modelo seleccionado es diferente. Este modelo emplea 4 variables (x2 x3 x4 x5) y ese modelo corresponde al modelo número 176 de los 1023 estimados.
## [1] 176## [1] 4## [1] "x2 x3 x4 x5"Finalmente, tenemos todos los modelos candidatos a ser el mejor modelo. Estimemos los dos modelos y guardemos los resultados en los objetos modelo1 y modelo2. Los resultados se reportan en el Cuadro 6.1.
# estimación del primer modelo candidato
modelo1 <- lm( y ~ x1 + x2 + x3 + x4 + x5 + x9, data = datos2)
# estimación del segundo modelo candidato
modelo2 <- lm( y ~ x2 + x3 + x4 + x5, data = datos2)| Modelo 1 | Modelo 2 | |
|---|---|---|
| (Intercept) | 11.27*** | 11.92*** |
| (1.35) | (1.31) | |
| x1 | 0.67* | |
| (0.26) | ||
| x2 | 1.69*** | 1.70*** |
| (0.27) | (0.27) | |
| x3 | 0.96*** | 0.86** |
| (0.26) | (0.26) | |
| x4 | 0.98*** | 1.03*** |
| (0.25) | (0.24) | |
| x5 | 0.95*** | 1.00*** |
| (0.25) | (0.25) | |
| x9 | -0.54* | |
| (0.27) | ||
| R2 | 0.71 | 0.70 |
| Adj. R2 | 0.70 | 0.69 |
| Num. obs. | 150 | 150 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
Noten que en este caso los modelos están anidados y, por tanto, se pueden comparar fácilmente empleando una prueba \(F\) que compare un modelo restringido con uno sin restringir (Ver 4.3.1 para una discusión del tema). Hagamos dicha comparación.
## Analysis of Variance Table
##
## Model 1: y ~ x2 + x3 + x4 + x5
## Model 2: y ~ x1 + x2 + x3 + x4 + x5 + x9
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 145 927.97
## 2 143 874.26 2 53.712 4.3928 0.01408 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Según los resultados, no se puede rechazar la nula de que el modelo con restricciones (el pequeño) es mejor que el sin restringir con un 99% de confianza. Así (con un nivel de confianza del 99%), podemos concluir que el mejor modelo es el que incluye las variables (x2 x3 x4 x5). En este caso sabemos que el modelo real que generó los datos incluye las variables \(x1\) a \(x5\). Así, nuestra aproximación no encontró el modelo real, pero uno relativamente cercano. Con un 95% de confianza se puede rechazar la nula en favor del modelo sin restringir. En este caso el modelo incluiría todas las variables de \(x1\) a \(x5\) pero también incluiría \(x9\); tampoco es el modelo exacto, pero es lo suficientemente cercano.
6.3 Empleando estrategias inteligentes de detección de un mejor modelo
En algunas ocasiones es imposible encontrar el mejor modelo estimando todas las combinaciones (como el caso en el que se tienen 25 variables pues existen \(2^{25}\) posibles modelos). A continuación, discutimos varios algoritmos que facilitan la tarea.
6.3.1 Regresión paso a paso (stepwise)
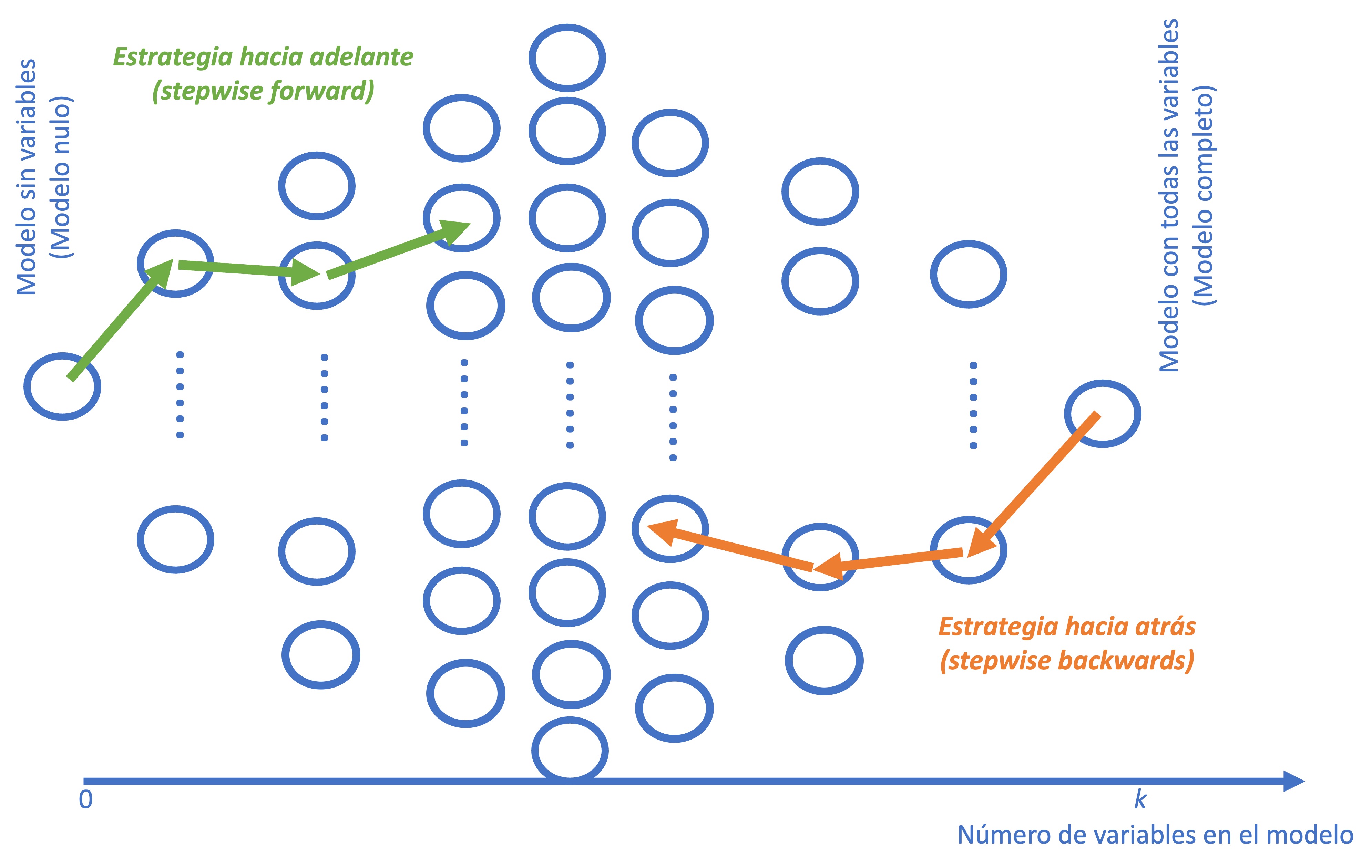
La idea de la construcción de modelos por pasos es arribar a un modelo de regresión a partir de un conjunto de posibles variables explicativas basados en un criterio que permita adicionar variables (stepwise forward regression) o quitar variables (stepwise backwards regression).
Por ejemplo, supongamos que empleamos un criterio como el valor p de la prueba de significancia individual de cada variable en el modelo. En el primer caso (stepwise forward regression) se parte de un modelo sin variables. Se empieza adicionando al modelo la variable que tenga el menor valor p. De forma gradual se incluye la siguiente variable que tenga el valor p más pequeño, se sigue de esta manera hasta que ya no quede ninguna variable para ingresar que sea significativa65.
En el segundo caso (stepwise backward regression), se parte del modelo con todas las variables y se empieza a eliminar variables que tenga el valor p más alto. El proceso se repite hasta que no se puedan eliminar variables66. Es fácil imaginarse cómo funcionarán ambos métodos si se emplean criterios como el \(R^2\) ajustado o criterios de información. La figura 6.2 muestra de manera esquemática estas dos aproximaciones.
Figura 6.2: Representación de las estrategias stepwise forward y stepwise backward
A continuación, veremos un ejemplo empleando la base de datos original con 25 variables explicativas.
6.3.1.1 Stepwise forward regression
La función regsubsets() del paquete leaps (Lumley, 2020) permite encontrar los mejores subconjuntos de variables explicativas utilizando el \(R^2\) ajustado partiendo de un modelo con todos los regresores (lo llamaremos el modelo máximo). Esta función no está diseñada para funcionar con el valor p. La función regsubsets() calcula los mejores modelos para todos los posibles número de variables explicativas sin calcularlos de manera exhaustiva67.
Los argumentos más importantes de esta función son
regsubsets(x, y, method=method=c(“backward”, “forward”, “seqrep”), nvmax, force.in)
donde:
- x: la matriz que contiene todas las posibles variables explicativas
- y: el vector de la variable dependiente (\(y\))
- method: el método que se desea emplear: (method =“backward”) para el método backward, (method =“forward”) para el método forward y (method = “seqrep”) para el método combinado.
- nvmax: el número máximo de variables a incluir en un modelo a ser examinado. Por ejemplo, si nvmax = 15 entonces solo se evaluarán hasta modelos con 15 variables explicativas.
- force.in: el número de la columna de la variable explicativa que se desee incluir siempre en el modelo. Por defecto es igual a NULL pero en algunas ocasiones es útil especificar una o unas variables que independientemente del resultado del algoritmo deberían estar siempre presentes como variables explicativas en todos los modelos considerados.
Empleemos esta función para nuestro caso y evaluando modelos con todas las variables.
# Cargar el paquete
library(leaps)
fwd.model <- regsubsets(x = datos[,1:25], y = datos[,26],
nvmax=250, method = "forward")En el objeto fwd.model se encuentran diferentes resultados. Veamos esto en detalle y generemos un gráfico que trae por defecto este paquete.
## $names
## [1] "np" "nrbar" "d" "rbar" "thetab" "first"
## [7] "last" "vorder" "tol" "rss" "bound" "nvmax"
## [13] "ress" "ir" "nbest" "lopt" "il" "ier"
## [19] "xnames" "method" "force.in" "force.out" "sserr" "intercept"
## [25] "lindep" "nullrss" "nn"
##
## $class
## [1] "regsubsets"Figura 6.3: R cuadrado ajustado y variables incluidas por modelo
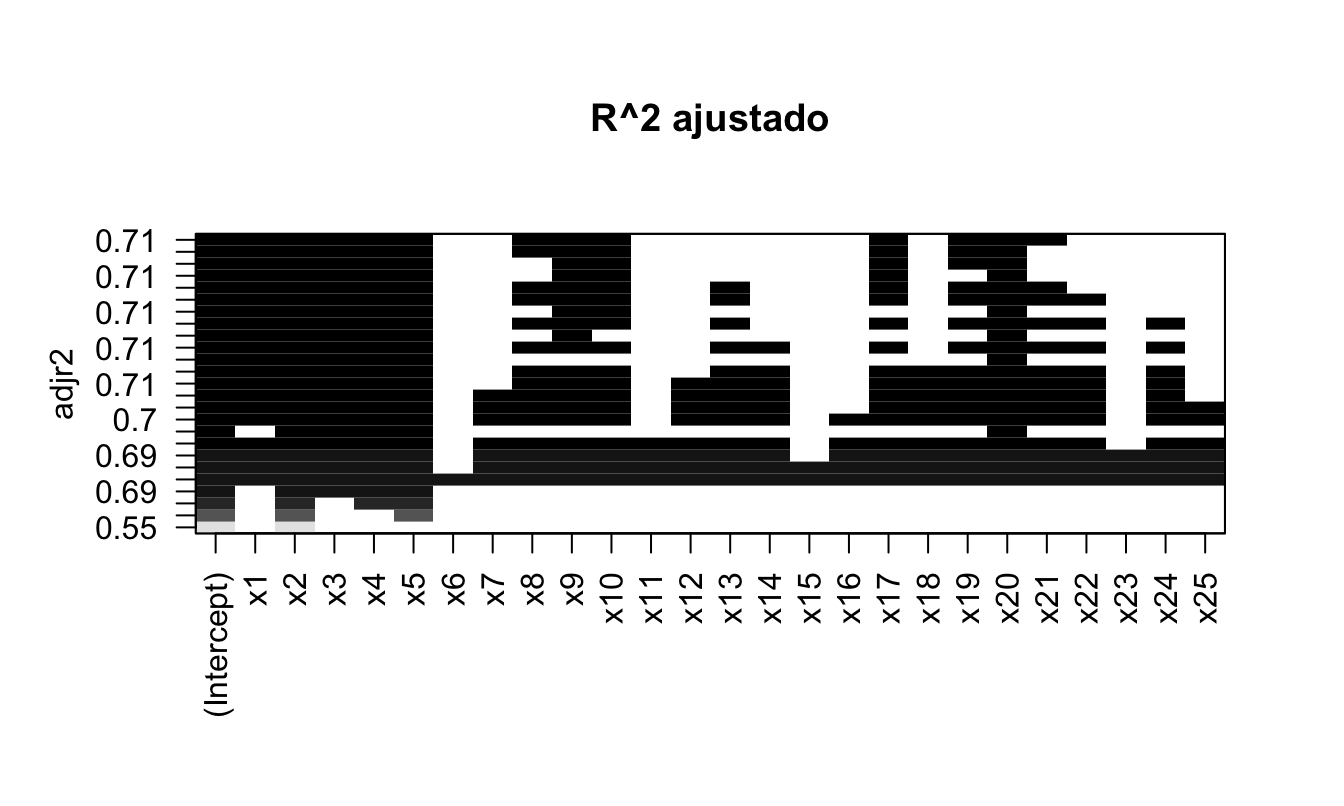
Esta visualización (ver Figura 6.3) presenta el \(R^2\) ajustado en el eje vertical y todas las potenciales variables evaluadas. El gráfico solo presenta los mejores modelos, en términos del \(R^2\) ajustado, entre todos los mejores modelos evaluados. Una fila corresponde a un modelo y un cuadrado negro implica que la correspondiente variable es incluida en el modelo que produce ese correspondiente \(R^2\) ajustado. Así, entre más “arriba” en el gráfico se muestre un modelo (una fila), mejor será éste de acuerdo a esta métrica. El mejor modelo es el último que se presenta (fila superior)68. En este caso el modelo tiene intercepto y las variables x1 a x5, x8 a x10, x17 y de x19 a x21. Estimemos ese modelo y guardémoslo en un objeto que llamaremos modelo3.
#estimación del modelo 3
modelo3 <- lm( y ~ x1 + x2 + x3 + x4 + x5 +
x8 + x9 +x10 + x17 + x19 +
x20 + x21, data = datos)
summary(modelo3)##
## Call:
## lm(formula = y ~ x1 + x2 + x3 + x4 + x5 + x8 + x9 + x10 + x17 +
## x19 + x20 + x21, data = datos)
##
## Residuals:
## Min 1Q Median 3Q Max
## -5.3123 -1.5515 -0.0106 1.5859 6.5427
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 11.0686 1.3692 8.084 2.94e-13 ***
## x1 0.5791 0.2706 2.140 0.034097 *
## x2 1.6885 0.2803 6.024 1.48e-08 ***
## x3 0.8892 0.2746 3.238 0.001511 **
## x4 0.9751 0.2605 3.743 0.000267 ***
## x5 0.8822 0.2719 3.244 0.001480 **
## x8 -0.3131 0.2705 -1.158 0.249075
## x9 -0.5104 0.2787 -1.832 0.069184 .
## x10 0.4187 0.2833 1.478 0.141721
## x17 0.3070 0.2586 1.187 0.237254
## x19 0.3087 0.2894 1.067 0.287945
## x20 -0.7848 0.2850 -2.754 0.006696 **
## x21 0.3129 0.2926 1.069 0.286774
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 2.419 on 137 degrees of freedom
## Multiple R-squared: 0.7378, Adjusted R-squared: 0.7148
## F-statistic: 32.12 on 12 and 137 DF, p-value: < 2.2e-16Este modelo tiene variables no significativas individualmente que pueden ser removidas automáticamente como se discute más adelante en la sección 6.4.1 de este capítulo.
También podemos realizar una versión de regresión por pasos hacia adelante utilizando la función ols_step_forward_p() del paquete olsrr (Hebbali, 2020). Esta función nos permite usar el criterio del valor p de las pruebas de significancia individuales y criterios de información. El único argumento de esta función es un objeto de la clase lm. Ese modelo debe incluir todas las variables explicativas que se desean explorar; es decir el modelo máximo. En este caso esta función puede ser empleada de la siguiente manera:
Los resultados los podemos explorar de muchas maneras, pero la más sencilla es llamando al objeto. Esto nos mostrará cuáles son las variables que se incluyen en el mejor modelo.
##
## Selection Summary
## -------------------------------------------------------------------------
## Variable Adj.
## Step Entered R-Square R-Square C(p) AIC RMSE
## -------------------------------------------------------------------------
## 1 x2 0.5495 0.5465 69.8613 764.2277 3.0502
## 2 x5 0.6303 0.6253 33.1629 736.5927 2.7727
## 3 x4 0.6742 0.6675 14.1062 719.6128 2.6116
## 4 x3 0.6964 0.6880 5.4785 711.0365 2.5298
## 5 x20 0.7069 0.6967 2.4563 707.7667 2.4943
## 6 x1 0.7200 0.7082 -1.8043 702.9271 2.4466
## 7 x9 0.7241 0.7105 -1.7852 702.6965 2.4370
## 8 x10 0.7281 0.7127 -1.7173 702.4882 2.4277
## 9 x17 0.7315 0.7142 -1.3183 702.6336 2.4214
## -------------------------------------------------------------------------El modelo seleccionado incluye las siguientes variables: \(x1\) a \(x5\), \(x9\), \(x10\), \(x17\) y \(x20\) (asegúrese que entiende el porqué se escoge dicho modelo según el gráfico). Estimemos este modelo y guardémoslo en el objeto modelo4.
Los resultados se reportan en el Cuadro 6.2. Este modelo también tiene variables no significativas individualmente.
| Modelo 4 | |
|---|---|
| (Intercept) | 11.17*** |
| (1.35) | |
| x1 | 0.66* |
| (0.26) | |
| x2 | 1.70*** |
| (0.27) | |
| x3 | 0.96*** |
| (0.26) | |
| x4 | 0.99*** |
| (0.26) | |
| x5 | 0.93*** |
| (0.27) | |
| x9 | -0.50 |
| (0.27) | |
| x10 | 0.39 |
| (0.28) | |
| x17 | 0.33 |
| (0.25) | |
| x20 | -0.73* |
| (0.28) | |
| R2 | 0.73 |
| Adj. R2 | 0.71 |
| Num. obs. | 150 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
El mismo paquete tiene una función que permite realizar el algoritmo empleando el criterio de información \(AIC\) (y otros como el mismo \(R^2\) ajustado). Para el \(AIC\) la función es ols_step_forward_aic(). El único argumento necesario es un objeto de clase lm que contenga el modelo máximo.
##
## Selection Summary
## --------------------------------------------------------------------
## Variable AIC Sum Sq RSS R-Sq Adj. R-Sq
## --------------------------------------------------------------------
## x2 764.228 1679.790 1376.927 0.54954 0.54650
## x5 736.593 1926.638 1130.079 0.63030 0.62527
## x4 719.613 2060.953 995.764 0.67424 0.66754
## x3 711.036 2128.745 927.972 0.69642 0.68804
## x20 707.767 2160.781 895.936 0.70690 0.69672
## x1 702.927 2200.715 856.001 0.71996 0.70821
## x9 702.696 2213.351 843.366 0.72409 0.71049
## x10 702.488 2225.675 831.042 0.72813 0.71270
## --------------------------------------------------------------------El modelo seleccionado incluye las siguientes variables: \(x1\) a \(x5\), \(x9\), \(x10\) y \(x20\). Nota que al llamar al objeto fwd.model.3 podemos observar cuál variable fue adicionada en cada uno de los 8 pasos. En esta oportunidad, la primera variable adicionada al modelo fue la \(x2\) y la última \(x10\). Los resultados los podemos ver de manera gráfica si se emplea la función plot() sobre el objeto fwd.model.3.
En el slot denominado predictors podemos encontrar las variables que se seleccionaron en el mejor modelo. Así podemos estimar el mejor modelo según este algoritmo y el criterio de información \(AIC\) de la siguiente manera (esto evita tener que escribir manualmente la fórmula como lo habíamos hecho en los casos anteriores).
# se extraen las variables del mejor modelo según el algoritmo
vars.modelo5 <- fwd.model.3$predictors
# se contruye la fórmula
formula.modelo5 <- as.formula(
paste("y ~ ", paste (vars.modelo5, collapse=" + "),
sep=""))
# constata que la fórmula es correcta
formula.modelo5## y ~ x2 + x5 + x4 + x3 + x20 + x1 + x9 + x106.3.2 Stepwise backward regression
De manera similar podemos emplear tanto el paquete leaps como el paquete olsrr para encontrar un modelo partiendo del modelo que incluye todas las variables y quitando una variable en cada paso. En este caso tendremos el siguiente resultado si empleamos el criterio del \(R^2\) ajustado.
El modelo tiene las variables x1 a x5, x8 a x10, x17 y de x19 a x21. Es decir, llega a la misma conclusión que el método forward.
De manera similar, podemos emplear la función ols_step_backward_p() del paquete olsrr para seleccionar el mejor modelo empleando el valor p de la prueba individual para eliminar variables. El argumento que necesita esta función es el objeto que contenga la estimación del modelo máximo.
En este caso el modelo seleccionado incluye las siguientes variables: x1 a x5, x8, x9, x10, x17, x19 a x21. En el compartimiento $model del objeto que acabamos de crear quedan almacenado el mejor modelo, guardémoslo en el objeto modelo6.
Nota que este modelo también tiene variables no significativas individualmente. Ustedes deberían emplear las técnicas que ya conocen para encontrar un mejor modelo sin variables no significativas69. Los resultados se reportan en el Cuadro 6.3.
Nuevamente, como lo hicimos con el algoritmo forward, podemos emplear el paquete olsrr y la función ols_step_backward_aic() para encontrar el mejor modelo de acuerdo con este algoritmo y el criterio de información \(AIC\).
En el Cuadro 6.3 se reporta el resultado de este modelo.
| Modelo 5 | |
|---|---|
| (Intercept) | 11.35*** |
| (1.35) | |
| x1 | 0.69** |
| (0.26) | |
| x2 | 1.72*** |
| (0.27) | |
| x3 | 0.95*** |
| (0.26) | |
| x4 | 1.05*** |
| (0.26) | |
| x5 | 1.05*** |
| (0.25) | |
| x9 | -0.42 |
| (0.27) | |
| x10 | 0.41 |
| (0.28) | |
| x20 | -0.74* |
| (0.28) | |
| R2 | 0.73 |
| Adj. R2 | 0.71 |
| Num. obs. | 150 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
Este modelo tiene dos variables no significativas individualmente. El lector ya conoce el procedimiento para eliminar estas variables que no son significativas para obtener un mejor modelo70.
El modelo seleccionado incluye las siguientes variables: x1 a x5, x9, x10 y X20. Nuevamente podemos recuperar el mejor modelo con el compartimiento $model del objeto que acabamos de crear. Guardémoslo en le objeto modelo7.
Este modelo también tiene variables no significativas individualmente, pero muchas más que los modelos anteriores. Esto no es una característica de este algoritmo, solo es coincidencia. Los resultados se reportan en el Cuadro 6.4.
| Modelo 6 | Modelo 7 | |
|---|---|---|
| (Intercept) | 11.07*** | 11.35*** |
| (1.37) | (1.35) | |
| x1 | 0.58* | 0.69** |
| (0.27) | (0.26) | |
| x2 | 1.69*** | 1.72*** |
| (0.28) | (0.27) | |
| x3 | 0.89** | 0.95*** |
| (0.27) | (0.26) | |
| x4 | 0.98*** | 1.05*** |
| (0.26) | (0.26) | |
| x5 | 0.88** | 1.05*** |
| (0.27) | (0.25) | |
| x8 | -0.31 | |
| (0.27) | ||
| x9 | -0.51 | -0.42 |
| (0.28) | (0.27) | |
| x10 | 0.42 | 0.41 |
| (0.28) | (0.28) | |
| x17 | 0.31 | |
| (0.26) | ||
| x19 | 0.31 | |
| (0.29) | ||
| x20 | -0.78** | -0.74* |
| (0.29) | (0.28) | |
| x21 | 0.31 | |
| (0.29) | ||
| R2 | 0.74 | 0.73 |
| Adj. R2 | 0.71 | 0.71 |
| Num. obs. | 150 | 150 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
6.3.3 Combinando forward y backward (step regression)
También podemos crear un modelo de regresión a partir de un conjunto de posibles variables explicativas ingresándolas y eliminándolas basados en si se aumenta o no el \(R^2\) ajustado, de forma escalonada hasta que ya no quede ninguna variable para ingresar o eliminar (método combinado). El modelo de partida debe incluir todas las variables explicativas candidatas. Empleando el paquete paquete leaps y la función que ya conocemos regsubsets() . Para emplear este algoritmo solo se necesita cambiar el argumento method. En este caso se requiere method =“seqrep”.
En este caso el modelo tiene las siguientes variables: x1, x2, x3, x4, x5, x8, x9, x10, x17, x20, x21. El lector puede estimar el correspondiente modelo (llámelo modelo8) los resultados de este modelo se encuentran en Cuadro 6.5. Nuevamente, el modelo incluye variables no significativas.
| Modelo 8 | |
|---|---|
| (Intercept) | 11.11*** |
| (1.37) | |
| x1 | 0.65* |
| (0.26) | |
| x2 | 1.69*** |
| (0.28) | |
| x3 | 0.90** |
| (0.27) | |
| x4 | 0.98*** |
| (0.26) | |
| x5 | 0.93*** |
| (0.27) | |
| x8 | -0.29 |
| (0.27) | |
| x9 | -0.48 |
| (0.28) | |
| x10 | 0.43 |
| (0.28) | |
| x17 | 0.36 |
| (0.25) | |
| x20 | -0.76** |
| (0.28) | |
| x21 | 0.33 |
| (0.29) | |
| R2 | 0.74 |
| Adj. R2 | 0.71 |
| Num. obs. | 150 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
Otra forma de emplear este método es usando el valor p como criterio para quitar o incluir variables. Esto se puede hacer empleando la función ols_step_both_p() del paquete olsrr. Esta función tiene como único argumento un objeto de la clase lm que corresponde al modelo máximo. Para este contexto tendremos el siguiente código.
En este caso el modelo seleccionado incluye las variables \(x1\) a \(x5\) y \(x20\). El lector puede constatar que el correspondiente modelo es el reportado en el Cuadro 6.6. Estimemos este modelo y guardémolo en el objeto modelo9.
Finalmente, empleando el criterio de AIC tendremos que el mejor modelo incluye las variables \(x1\) a \(x5\), \(x9\), \(x10\) y \(x20\). Este modelo se reporta en el Cuadro 6.6 y se guardó en el objeto modelo10. Este modelo tiene dos variables no significativas.
| Modelo 9 | Modelo 10 | |
|---|---|---|
| (Intercept) | 11.07*** | 11.35*** |
| (1.37) | (1.35) | |
| x1 | 0.58* | 0.69** |
| (0.27) | (0.26) | |
| x2 | 1.69*** | 1.72*** |
| (0.28) | (0.27) | |
| x3 | 0.89** | 0.95*** |
| (0.27) | (0.26) | |
| x4 | 0.98*** | 1.05*** |
| (0.26) | (0.26) | |
| x5 | 0.88** | 1.05*** |
| (0.27) | (0.25) | |
| x8 | -0.31 | |
| (0.27) | ||
| x9 | -0.51 | -0.42 |
| (0.28) | (0.27) | |
| x10 | 0.42 | 0.41 |
| (0.28) | (0.28) | |
| x17 | 0.31 | |
| (0.26) | ||
| x19 | 0.31 | |
| (0.29) | ||
| x20 | -0.78** | -0.74* |
| (0.29) | (0.28) | |
| x21 | 0.31 | |
| (0.29) | ||
| R2 | 0.74 | 0.73 |
| Adj. R2 | 0.71 | 0.71 |
| Num. obs. | 150 | 150 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
6.4 Pongamos todo junto
En la práctica queremos emplear un único modelo, para eso debemos comparar los modelos que hemos encontrado, anidados o no. Pero antes es mejor comparar modelos que tengan solo variables explicativas significativas. Es decir, modelos que no tengan variables que no son estadísticamente importantes para explicar la variable dependiente.
Recordemos que en este ejercicio de selección automática del mejor modelo, hemos construido ya varios modelos candidatos a mejor modelo como se resume en el Cuadro 6.7.
| Nombre del objeto | Algoritmo | Criterio |
|---|---|---|
| Modelo3 | Forward | \(R^2\) ajustado |
| Modelo4 | Forward | valor p |
| Modelo5 | Forward | AIC |
| Modelo6 | Backward | \(R^2\) ajustado |
| Modelo7 | Backward | AIC |
| Modelo8 | Both | \(R^2\) ajustado |
| Modelo9 | Both | valor p |
| Modelo10 | Both | AIC |
| Fuente: elaboración propia. |
En la siguiente subsección veremos un método para limpiar las variables no significativas de manera automática y en la segunda subsección compararemos los modelos.
6.4.1 Eliminando automáticamente variables no significativas
Como se discutió anteriormente, es posible que uno de los algoritmos nos arroje un modelo candidato a ser el “mejor” modelo que tenga variables no significativas. Es decir, los algoritmos y criterios no garantizan que el modelo tenga todas las variables estadísticamente significativas. Para eliminar de manera iterativa aquellas variables que no sean individualmente significativas, podemos emplear la función remueve.no.sinifica() que crearemos a continuación. Puedes seguir cada línea de la función para entender los “trucos” que se emplean.
remueve.no.sinifica <- function(modelo, p){
# Extraer el data.frame
datos <- modelo$model
# Extraer el nombre de todas las variables X
all_vars <- all.vars(formula(modelo))[-1]
# extraer el nombre de la variables y
dep_var <- all.vars(formula(modelo))[1]
# Extraer las variables no significativas
# resumen del modelo
summ <- summary(modelo)
# extrae los valores p
pvals <- summ[[4]][, 4]
# creando objeto para guardar las variables no significativas
not_signif <- character()
not_signif<- names(which(pvals > p))
# Si hay alguna variable no-significativa
while(length(not_signif) > 0){
all_vars <- all_vars[!all_vars %in% not_signif[1]]
# nueva formula
myForm <- as.formula(paste(paste(dep_var, "~ "),
paste (all_vars, collapse=" + "), sep=""))
# re-escribe la formula
modelo <- lm(myForm, data= datos)
# Extrae variables no significativas.
summ <- summary(modelo)
pvals <- summ[[4]][, 4]
not_signif <- character()
not_signif <- names(which(pvals > p))
not_signif <- not_signif[!not_signif %in% "(Intercept)"]
}
modelo.limpio <- modelo
return(modelo.limpio)
}Para ver un ejemplo, regresemos al modelo construido por medio del algoritmo forward y el criterio del \(R^2\) ajustado (ese modelo lo guardamos en el objeto modelo3). La función que acabamos de construir (remueve.no.sinifica()) tiene dos argumentos, el primero es un objeto de clase lm y el segundo el nivel de significancia que indica el nivel por debajo del cual se considera que una variable es significativa. Corramos esta función para el objeto modelo3 con un nivel de significancia del 5% y guardemos los resultados en un objeto que denominaremos modelo3.a.
Antes de continuar, comparemos estos dos modelos reportados en el Cuadro 6.8.
| Modelo 3 | Modelo 3a | |
|---|---|---|
| (Intercept) | 11.07*** | 12.44*** |
| (1.37) | (1.31) | |
| x1 | 0.58* | |
| (0.27) | ||
| x2 | 1.69*** | 1.78*** |
| (0.28) | (0.27) | |
| x3 | 0.89** | 0.95*** |
| (0.27) | (0.26) | |
| x4 | 0.98*** | 1.21*** |
| (0.26) | (0.25) | |
| x5 | 0.88** | 1.16*** |
| (0.27) | (0.25) | |
| x8 | -0.31 | |
| (0.27) | ||
| x9 | -0.51 | |
| (0.28) | ||
| x10 | 0.42 | |
| (0.28) | ||
| x17 | 0.31 | |
| (0.26) | ||
| x19 | 0.31 | |
| (0.29) | ||
| x20 | -0.78** | -0.61* |
| (0.29) | (0.27) | |
| x21 | 0.31 | |
| (0.29) | ||
| R2 | 0.74 | 0.71 |
| Adj. R2 | 0.71 | 0.70 |
| Num. obs. | 150 | 150 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
Ahora todas las variables son significativas. Realicemos el mismo procedimiento para todos los modelos. Asegúrate que puedes obtener los modelos que se reportan en los Cuadros 6.9 y 6.10.
| Modelo 3a | Modelo 4.a | Modelo 5.a | Modelo 6.a | |
|---|---|---|---|---|
| (Intercept) | 12.44*** | 11.46*** | 11.46*** | 12.44*** |
| (1.31) | (1.34) | (1.34) | (1.31) | |
| x2 | 1.78*** | 1.66*** | 1.66*** | 1.78*** |
| (0.27) | (0.26) | (0.26) | (0.27) | |
| x3 | 0.95*** | 0.93*** | 0.93*** | 0.95*** |
| (0.26) | (0.26) | (0.26) | (0.26) | |
| x4 | 1.21*** | 1.09*** | 1.09*** | 1.21*** |
| (0.25) | (0.25) | (0.25) | (0.25) | |
| x5 | 1.16*** | 1.06*** | 1.06*** | 1.16*** |
| (0.25) | (0.25) | (0.25) | (0.25) | |
| x20 | -0.61* | -0.71** | -0.71** | -0.61* |
| (0.27) | (0.27) | (0.27) | (0.27) | |
| x1 | 0.66* | 0.66* | ||
| (0.26) | (0.26) | |||
| R2 | 0.71 | 0.72 | 0.72 | 0.71 |
| Adj. R2 | 0.70 | 0.71 | 0.71 | 0.70 |
| Num. obs. | 150 | 150 | 150 | 150 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||||
| Modelo 7.a | Modelo 8.a | Modelo 9.a | Modelo 10.a | |
|---|---|---|---|---|
| (Intercept) | 11.92*** | 11.46*** | 11.46*** | 11.46*** |
| (1.31) | (1.34) | (1.34) | (1.34) | |
| x2 | 1.70*** | 1.66*** | 1.66*** | 1.66*** |
| (0.27) | (0.26) | (0.26) | (0.26) | |
| x3 | 0.86** | 0.93*** | 0.93*** | 0.93*** |
| (0.26) | (0.26) | (0.26) | (0.26) | |
| x4 | 1.03*** | 1.09*** | 1.09*** | 1.09*** |
| (0.24) | (0.25) | (0.25) | (0.25) | |
| x5 | 1.00*** | 1.06*** | 1.06*** | 1.06*** |
| (0.25) | (0.25) | (0.25) | (0.25) | |
| x1 | 0.66* | 0.66* | 0.66* | |
| (0.26) | (0.26) | (0.26) | ||
| x20 | -0.71** | -0.71** | -0.71** | |
| (0.27) | (0.27) | (0.27) | ||
| R2 | 0.70 | 0.72 | 0.72 | 0.72 |
| Adj. R2 | 0.69 | 0.71 | 0.71 | 0.71 |
| Num. obs. | 150 | 150 | 150 | 150 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||||
Los resultados muestran que los modelos 3 y 6 arriban a la misma especificación: x2, x3, x4, x5 y x20 (en el Cuadro 6.7 se puede ver a qué algoritmo y criterio corresponde cada uno de esos modelos). Los modelos 4, 5, 8, 9 y 10 implican emplear las mismas variables explicativas: x1, x2, x3, x4, x5 y x20 (en el Cuadro 6.7 se puede ver a qué algoritmo y criterio corresponde cada uno de esos modelos). El modelo 7 emplea solamente las variables x2, x3, x4, y x5. Estos resultados nos llevan a comparar tres modelos que están anidados.
6.4.2 Comparación de modelos
Finalmente, es importante comparar los 3 modelos. Los tres modelos que compararemos son: \[\begin{equation} {y_i} = {\beta_1} + {\beta_2}x{1_i} + {\beta_3}x{2_i} + {\beta_4}x{3_i} + {\beta_5}x{4_i} + {\beta_6}x{5_i} + {\beta_7}x{20_i} + {\varepsilon_i} \tag{6.1} \end{equation}\] \[\begin{equation} {y_i} = {\beta_1} + {\beta_3}x{2_i} + {\beta_4}x{3_i} + {\beta_5}x{4_i} + {\beta_6}x{5_i} + {\beta_7}x{20_i} + {\varepsilon_i} \tag{6.2} \end{equation}\] \[\begin{equation} {y_i} = {\beta_1} + {\beta_3}x{2_i} + {\beta_4}x{3_i} + {\beta_5}x{4_i} + {\beta_6}x{5_i} + {\varepsilon_i} \tag{6.3} \end{equation}\] Por simplicidad y para evitar confusiones, llamemos a estos tres modelos A, B y C, respectivamente. Así, el modelo B se encuentra anidado en el A. El modelo C está anidado en el modelo B y, por tanto, también en el C.
modeloA <- lm(y ~ x1 + x2 + x3 + x4 + x5 + x20, datos)
modeloB <- lm(y ~ x2 + x3 + x4 + x5 + x20, datos)
modeloC <- lm(y ~ x2 + x3 + x4 + x5, datos)El siguiente paso del científico de datos es escoger entre estos modelos. Para esto podemos emplear pruebas F para modelos anidados empleando la función anova(). Ahora procedamos a comparar los modelos A y B.
## Analysis of Variance Table
##
## Model 1: y ~ x2 + x3 + x4 + x5 + x20
## Model 2: y ~ x1 + x2 + x3 + x4 + x5 + x20
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 144 895.94
## 2 143 856.00 1 39.935 6.6713 0.0108 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1La prueba F permite rechazar la hipótesis nula de que el modelo B es mejor que el modelo A (con un 95% de confianza). Es decir, el modelo A es mejor. Ahora continuemos con las comparaciones del modelo A y C.
## Analysis of Variance Table
##
## Model 1: y ~ x2 + x3 + x4 + x5
## Model 2: y ~ x1 + x2 + x3 + x4 + x5 + x20
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 145 927.97
## 2 143 856.00 2 71.971 6.0115 0.003113 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Con un 99% de confianza se puede rechazar la hipótesis nula de que el modelo C es mejor que el A. En otras palabras, el mejor modelo es el A: \[\begin{equation} {y_i} = {\beta_1} + {\beta_2}x{1_i} + {\beta_3}x{2_i} + {\beta_4}x{3_i} + {\beta_5}x{4_i} + {\beta_6}x{5_i} + {\beta_7}x{20_i} + {\varepsilon_i} \tag{6.4} \end{equation}\]
Los resultados de la estimación de este modelo se presentan en el Cuadro 6.11.
| Modelo A | |
|---|---|
| (Intercept) | 11.46*** |
| (1.34) | |
| x1 | 0.66* |
| (0.26) | |
| x2 | 1.66*** |
| (0.26) | |
| x3 | 0.93*** |
| (0.26) | |
| x4 | 1.09*** |
| (0.25) | |
| x5 | 1.06*** |
| (0.25) | |
| x20 | -0.71** |
| (0.27) | |
| R2 | 0.72 |
| Adj. R2 | 0.71 |
| Num. obs. | 150 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
Para finalizar, recordemos que los datos fueron simulados de un modelo (DGP) real en el que las variables explicativas eran de \(x1\) a \(x5\). Las otras variables no se empleaban para simular \(y\). Nuestra selección automática nos lleva a encontrar un modelo muy cercano al real.
6.5 Comentarios finales
Existen otros métodos de selección de modelos menos tradicionales. Por ejemplo, el paquete subselect (Orestes Cerdeira et al., 2020) cuenta con algoritmos genéticos (GA) para la selección de modelos (ver función anneal()). También se puede explorar la función RegBest() del paquete FactoMineR (Lê et al., 2008) que emplea otras técnicas de inteligencia artificial para la selección de modelos. ¡Inténtalo!
Referencias
Si la respuesta a la pregunta de negocio implica un tipo de analítica diagnóstica. ↩︎
Si la respuesta a la pregunta de negocio implica un tipo de analítica predictiva. ↩︎
De aquí en adelante se omitirá la alusión a la posibilidad de emplear las técnicas de este capítulo para hacer analítica predictiva. Esto se hace solamente para ahorrar tiempo y espacio. Tienes que tener en cuenta que las técnicas que estudiaremos aquí pueden ser aplicadas para encontrar el mejor modelo de regresión independientemente si este se emplea o no para hacer analítica diagnóstica o predictiva y aún podría ser prescriptiva.↩︎
Nota que cuando se cuenta con una teoría que se desea probar, este problema no existe. Es decir, en la aproximación econométrica tradicional discutida en la sección 1.3 la teoría nos dirá cuál debería ser el modelo a probar y este problema de seleccionar el modelo con los datos desaparece. Pero como se discutió en esa misma sección la aproximación del científico de datos es muy diferente y, por tanto, este problema de la selección del mejor modelo se encuentra en el centro del quehacer diario del científico de datos que emplea el modelo de regresión.↩︎
Los datos se pueden descargar de la página web del libro: https://www.icesi.edu.co/editorial/modelo-clasico/↩︎
La variable \(x9\) es significativa con un nivel de confianza del 90%. Usaremos un nivel de confianza del 95%.↩︎
Esto puede tomar un rato, dado que se están estimando \(1024\) modelos.↩︎
Noten que esta aproximación tiene un problema práctico difícil de resolver. Se emplean múltiples pruebas individuales que acumulan el error tipo I. No existe almuerzo gratis, este es el costo de emplear esta aproximación. Adicionalmente, en presencia de heteroscedasticidad (Ver Capítulo 9) o autocorrelación (Ver Capítulo 11) estos valores p no serían válidos por no tener en cuenta el problema y, por tanto, las conclusiones podrían ser erradas.↩︎
Noten que esta aproximación también tiene el problema mencionado para la aproximación forward.↩︎
Dado que los criterios de información (\(AIC\) o \(BIC\)) solo difieren al comparar modelos con número diferentes de variables explicativas, el resultado final de los cálculos que realice esta función no depende del criterio de información que se emplee (Lumley, 2020). Así, esta función se puede emplear también para escoger el mejor modelo empleando los criterios de información. En ese caso el código que se presenta más adelante deberá ser modificado para emplear dichos criterios. Pero no es necesario modificar el código correspondiente a la función regsubsets() que se presenta a continuación.↩︎
Si se desea seleccionar el modelo empleando criterios de información, entonces la última linea de código debería ser modificada a
plot(fwd.model, scale = "bic")para el caso de SBC y para el caso del AIC se debe emplearplot(fwd.model, scale = "Cp"). Cp corresponde al criterio de información Cp de Mallows. La literatura ha demostrado que los resultados obtenidos con el Cp de Mallows (en orden) son los mismos que los del AIC para los modelos lineales (Boisbunon et al., 2013)). Es decir, el criterio de información Cp y el AIC son equivalentes en el orden que generan.↩︎Más adelante en la sección 6.4.1 de este capítulo se discute como remover estas variables empleando una función que automatiza el proceso.↩︎
Más adelante en la sección 6.4.1 de este capítulo se discute como remover estas variables empleando una función que automatiza el proceso.↩︎