5 Caso de estudio
5.1 Introducción
En los capítulos anteriores hemos estudiado los principios básicos del MBA y cómo implementar en R este tipo de análisis. En este Capítulo presentamos un estudio de caso para aplicar todos los conceptos presentados en los capítulos anteriores y mostrar cómo el proceso de exploración de datos puede hacer replantear o precisar las preguntas de negocio.
Antes de iniciar, es importante recordar que, como lo estudiamos en el Capítulo 1, el proceso del business analytics permite pasar de datos a insights para la toma de decisiones. Este proceso parte de una pregunta de negocio que es definida por la organización con ayuda del analytics translator. Una vez que la pregunta está definida y se cuenta con los datos, las primeras actividades son la limpieza y preparación de los datos, su exploración y visualización y el modelado que se requiera para responder a la pregunta de negocio planteada. Estas actividades son responsabilidad del científico de datos. Posteriormente, los insights descubiertos en el modelado deben ser comunicados a los tomadores de decisiones; esta actividad es responsabilidad principal del analytics translator.
Este Capítulo está organizado siguiendo el orden de estas actividades. Primero se presentarán los resultados de cada una de las fases, de tal manera que aquellos de ustedes que se encuentren (o estén interesados) en el rol de analytics translator se concentren en los resultados y los insights. En el Anexo de este Capítulo, los interesados en el rol de científico de datos podrán encontrar todo el código que se emplea en cada una de las actividades.
5.2 El contexto y la pregunta de negocio
Para este caso emplearemos una base de datos que contiene transacciones para la panadería en línea The Bread Basket de Edimburgo (Escocia), que han sido publicadas por Mittal (2018). La panadería The Bread Basket se encuentra en el casco histórico de Edimburgo, y se ha convertido en punto de “peregrinación” para los amantes del pan artesanal (Hery & Widjaja, 2024). Su propuesta fusiona técnicas clásicas británicas con sabores de Argentina y España (Oliveira, 2018). En sus vitrinas conviven baguettes recién horneadas con alfajores de dulce de leche y ensaimadas mallorquinas. La oferta de productos argentinos y españoles de esta panadería está descrita en varios estudios que emplean datos (Egbeola, 2023; Oliveira, 2018).
Entre enero de 2016 y diciembre de 2017, la panadería registró 9465 transacciones y se vendieron 94 ítems diferentes. Para ese entonces, The Bread Basket funcionaba principalmente durante el día (de media mañana a primeras horas de la tarde) y combinaba la atención tradicional en tienda con un servicio de pedidos en línea. La panadería registró meticulosamente cada venta, y la hora y día de esta. Algunos autores como Egbeola (2023) indican que los clientes podían ordenar sus productos a través de la web y recogerlos en la tienda, lo cual era un elemento innovador para un negocio de este tipo en esa época.
Además de panes y repostería, la tienda ofrecía experiencias especiales y productos promocionales. Por ejemplo, organizaba una sesión titulada “Afternoon with the Baker” (Tarde con el panadero) para interactuar con clientes, y vendía artículos de merchandising como camisetas y tarjetas de ocasión (por ejemplo, tarjetas de San Valentín)50. El detalle de cada transacción revela que la panadería presentaba un modelo híbrido que combina cafetería de barrio, tienda gourmet y microeventos gastronómicos.
La panadería, como la mayoría de negocios, estaba en ese momento buscando incrementar sus ventas. Para lograr su objetivo, el gerente tenía las siguientes preguntas de negocio51:
- ¿Tiene sentido hacer un descuento en el café?
- ¿Cuál sería un combo que dispare las ventas?
- ¿Qué recomendaciones se pueden hacer para vender más té?
El archivo bread basket.csv contiene cada una de las transacciones de esta panadería en línea entre el 30 de octubre del 2016 y el 9 de abril de 2017. Los datos originalmente fueron descargados de https://www.kaggle.com/datasets/mittalvasu95/the-bread-basket?resource=download (Mittal, 2018). Los datos que se emplean a continuación están disponibles en la página web del libro en el archivo bread basket.csv.
La base de datos contiene 20507 registros correspondientes a 9465 transacciones realizadas. La base de datos cuenta con 5 columnas, que representan igual número de variables. Las variables son:
Transaction: identificador único y numérico de la transacción. Esta variable permite agrupar los distintos ítems que componen una misma compra.Item: Nombre del producto adquirido.date_time: Marca de fecha y hora exactas del registro (formato dd-mm-aaaa hh:mm).period_day: Franja del día en la que ocurre la venta (Morning, Afternoon, Evening o Night).
weekday_weekend: Variable que marca si la transacción se realizó en días laborales (Weekday) o fines de semana (Weekend).
5.3 Exploración de los datos
Tras cargar los datos52, el científico de datos empezó a explorarlos. Una de las primeras ideas que se le ocurrió, fue crear un cuadro que permitiera observar el porcentaje de las transacciones que se hacen por tipo de día y momento del día. Los resultados se reportan en el Cuadro 5.1.
| weekday | weekend | Sum | |
|---|---|---|---|
| afternoon | 35.13 | 18.64 | 53.77 |
| evening | 1.79 | 0.97 | 2.76 |
| morning | 27.98 | 15.37 | 43.35 |
| night | 0.03 | 0.10 | 0.13 |
| Sum | 64.92 | 35.08 | 100.00 |
| Fuente: elaboración propia. |
Solo el 0.13% de las transacciones se realizan en la medianoche53 (Ver Cuadro 5.1 fila night). Y las transacciones de la noche (evening) representan el 2.76% de las transacciones totales (Ver Cuadro 5.1 fila evening). Es decir, entre las 6 p.m. y las 6 a.m. (evenning y night) solo se presentan el 2.89 % de las transacciones.
Estos resultados del Cuadro 5.1 permitieron al científico de datos empezar a “sospechar” que se deberían analizar los datos por periodo del día y no todos en conjunto. Los resultados mostraban que la mayoría de las transacciones ocurren en la tarde (afternoon) y las mañanas (morning). Por lo tanto, debería concentrar la atención en esos periodos. Tras un chequeo rápido con el analytics translator acordaron que tenía sentido seguir explorando esa idea de concentrar la atención en esos periodos. El conocimiento del negocio del analytics translator le permitía entender que el comportamiento de los compradores y sus gustos eran muy diferentes de noche y no valía el esfuerzo analizar ese periodo. Por eso decidieron concentrar la atención en lo que ocurre en la tarde (afternoon) y las mañanas (morning)54.
Después de esa decisión surgieron varias preguntas nuevas que inquietaban al analytics translator para poder comunicar su decisión a los tomadores de decisiones:
- ¿Cuántas observaciones tendremos ahora?
- ¿Cuántos productos se pierden con esta decisión?
El científico de datos encontró rápidamente la respuesta a estas preguntas. Hay 4 ítems que se venden en los periodos de night y evening que no se venden en el resto del día. Y pasamos de 9,465 a 9,192 transacciones, es decir, 273 transacciones menos. Esto no es sustancial y permite que nuestro análisis se concentre en dos periodos del día.
Entonces procedió a actualizar el Cuadro 5.1, sin las transacciones de los periodos de night y evening, obteniendo el Cuadro 5.2.
| weekday | weekend | Sum | |
|---|---|---|---|
| afternoon | 36.17 | 19.19 | 55.36 |
| morning | 28.81 | 15.83 | 44.64 |
| Sum | 64.98 | 35.02 | 100.00 |
| Fuente: elaboración propia. |
La siguiente exploración que realizó el científico de datos tenía que ver con los días de semana y los de los fines de semana. Para eso empezó a crear un gráfico de calendario (Calendar plot)55 (Ver Figura 5.1).
Figura 5.1: Número de transacciones de la mañana y de la tarde de la panadería
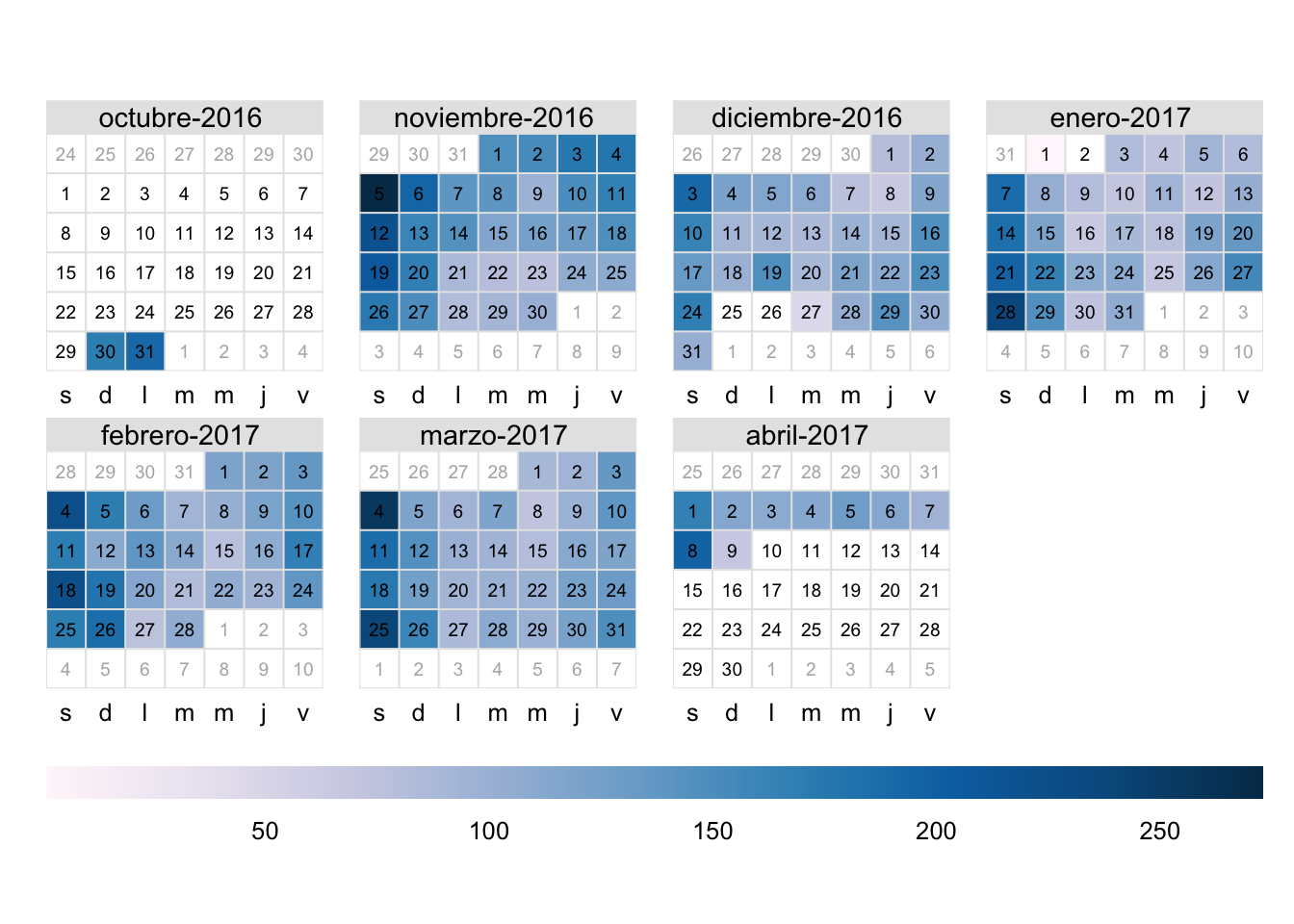
Figura 5.2: Número de transacciones de la mañana de la panadería
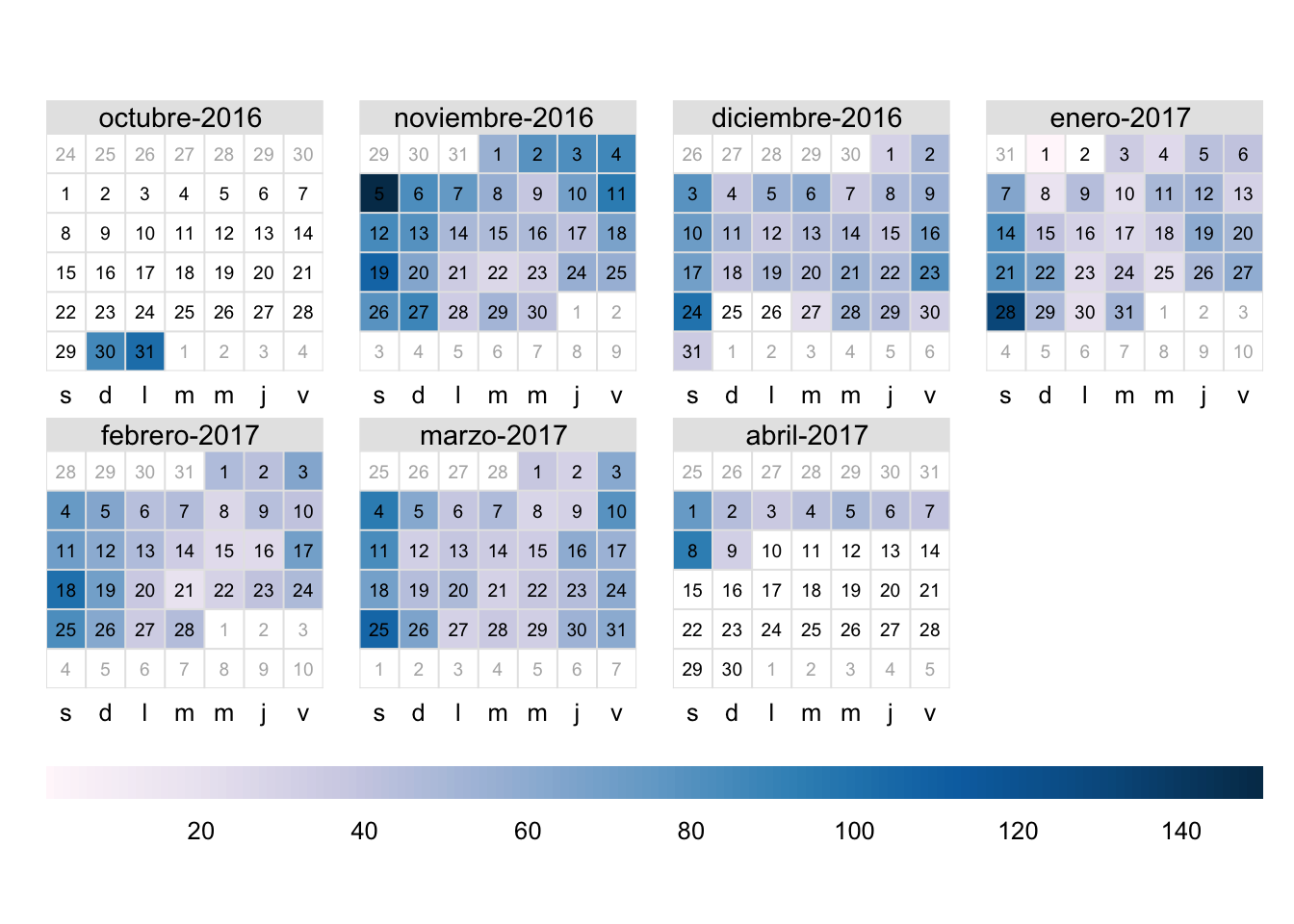
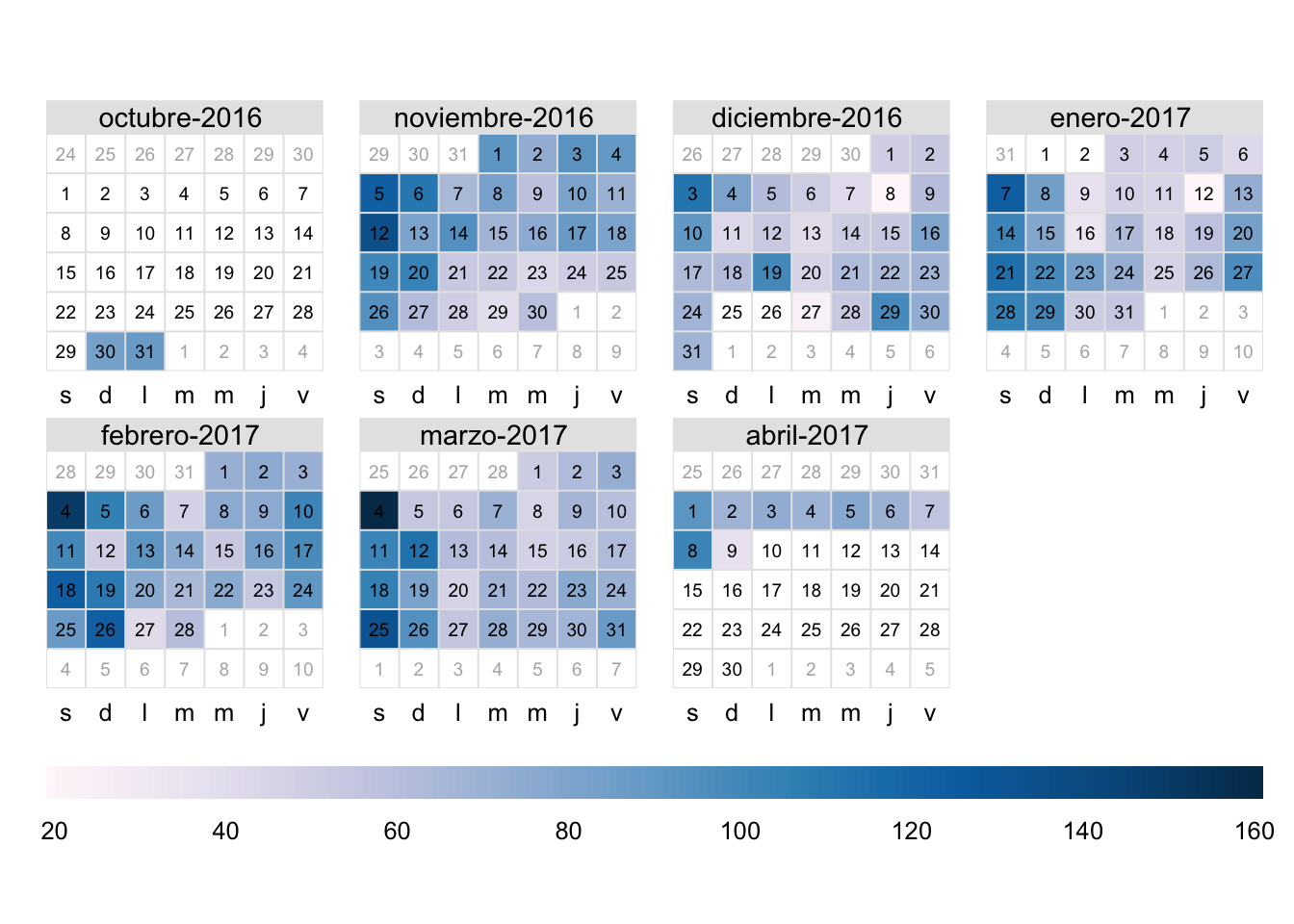
Figura 5.3: Número de transacciones de la tarde de la panadería
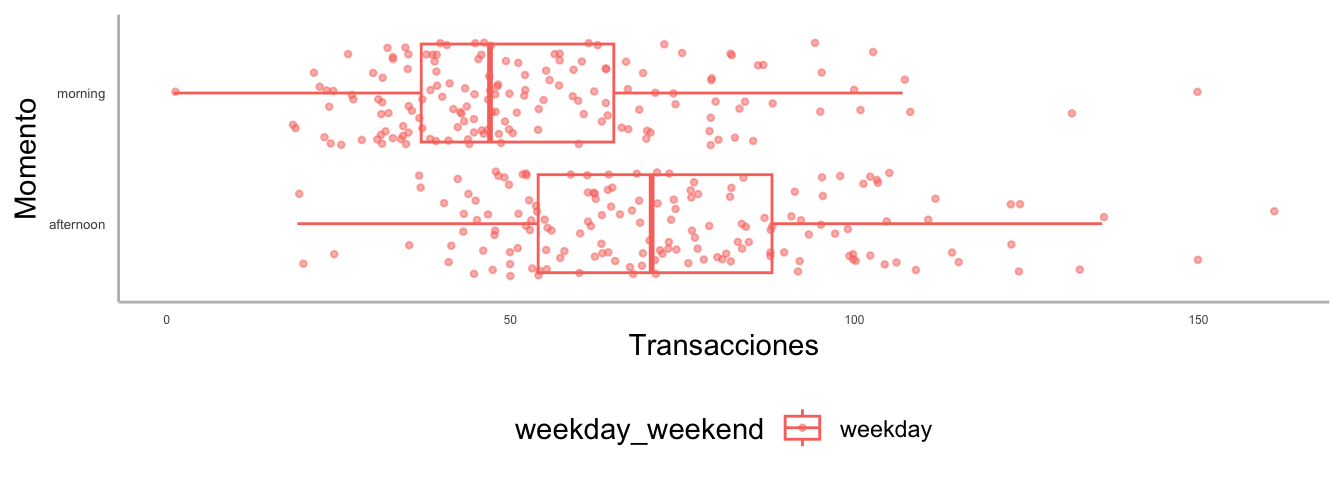
De estas visualizaciones, el científico de datos intuyó que existía una diferencia en el comportamiento del número de transacciones entre los fines de semana y durante los días laborales. Otra manera de ver esa diferencia fue empleando un boxplot, como en la Figura 5.4 y la Figura 5.5.
Figura 5.4: Distribución del número de transacciones de la panadería por tipo de día y momento del día
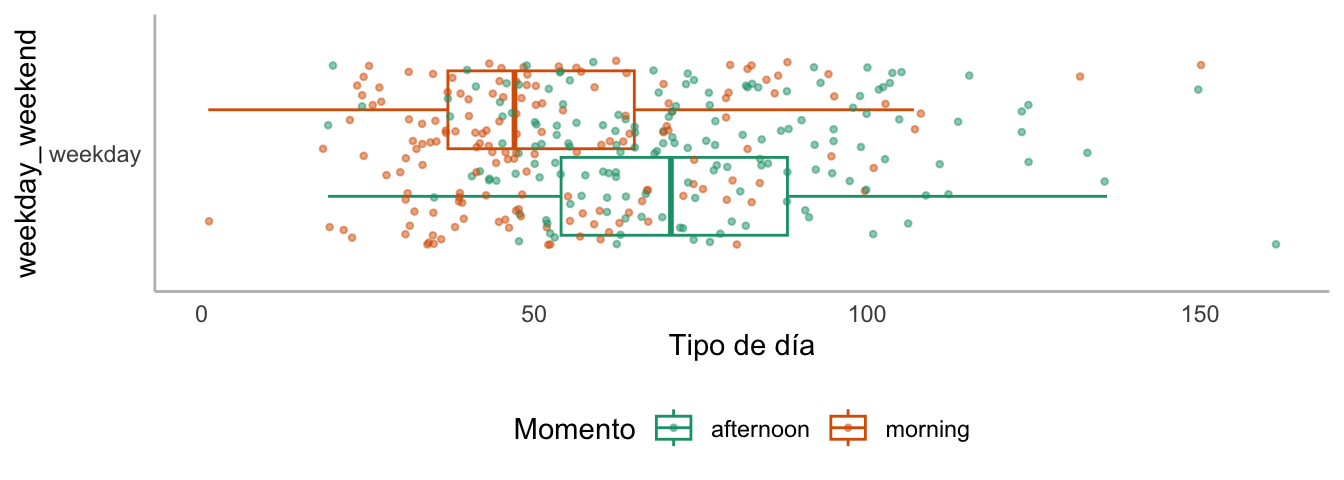
Figura 5.5: Distribución del número de transacciones de la panadería por momento del día y tipo de día
Otras visualizaciones alternas se presentan en las Figuras 5.6 y 5.7.
Figura 5.6: Densidad estimada para el número de transacciones de la panadería por tipo de día y momento del día
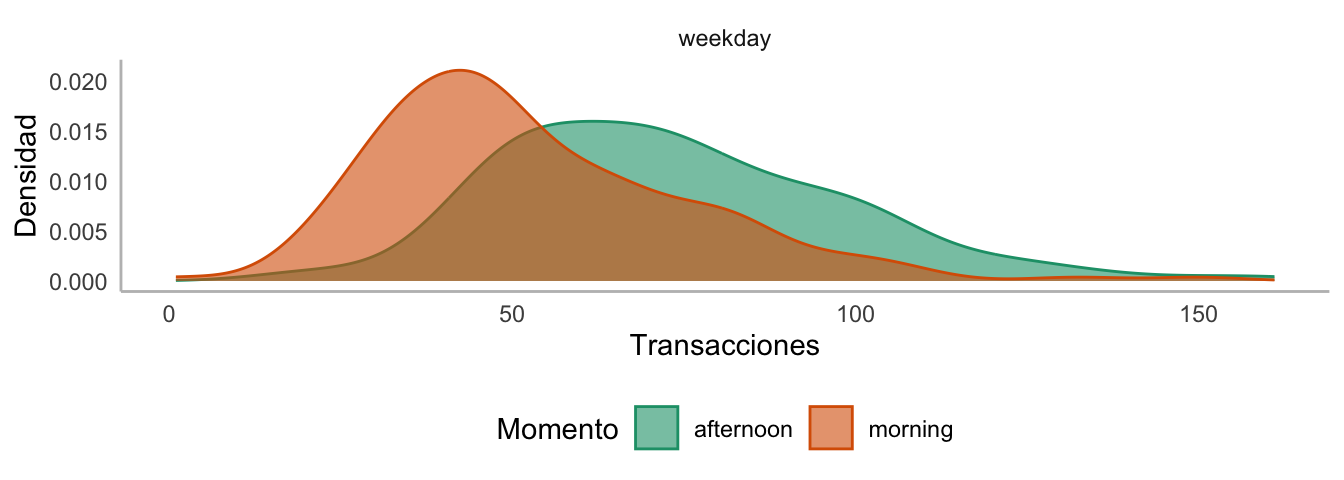
Figura 5.7: Densidad estimada para el número de transacciones de la panadería por momento del día y tipo de día
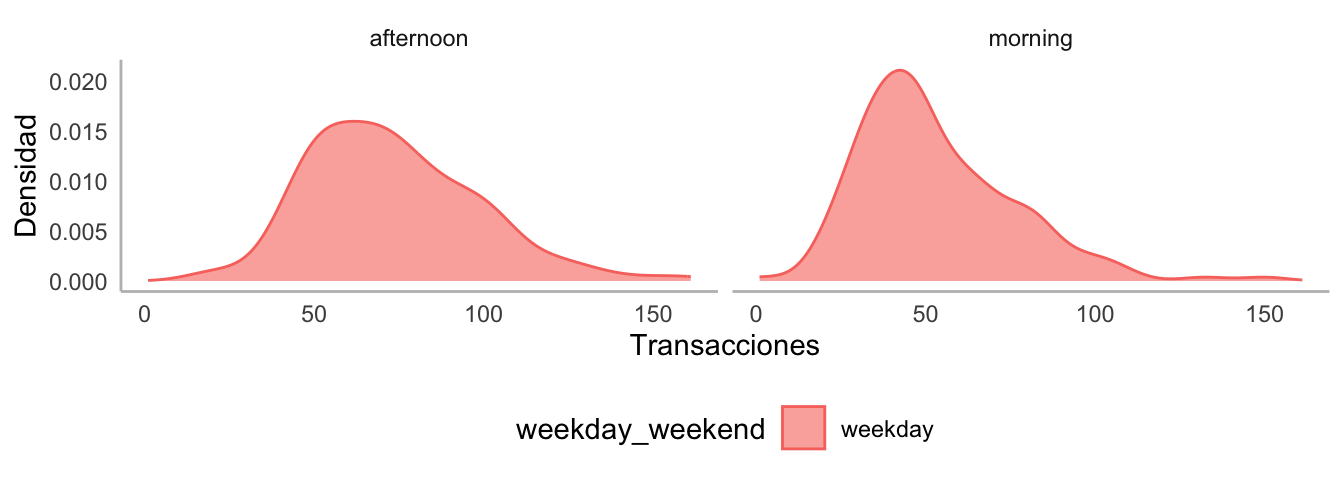
Las visualizaciones le permitieron intuir al científico de datos que el número de transacciones es diferente por tipo de día y momento del día. Con estos nuevos insights, el científico de datos exploró si los productos presentes en las canastas también diferían por tipo de día y momento del día.
Así, el científico de datos construyó visualizaciones para los ítems más frecuentes por momento del día y por tipo de día, como se ve en la Figura 5.8.
Figura 5.8: Ítems más frecuentes en las transacciones de la panadería por momento del día y tipo de día (proporción 0-1)
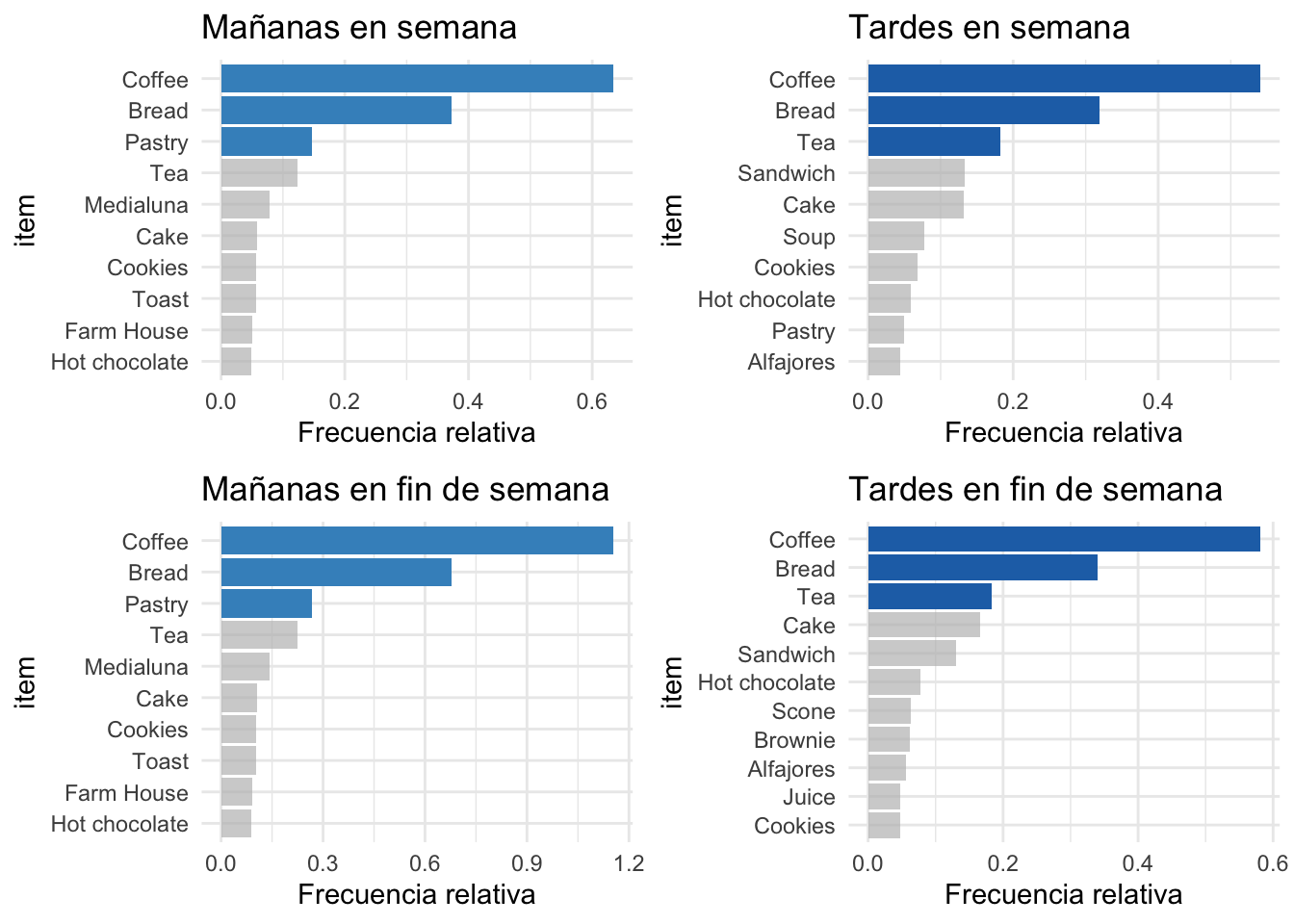
El científico de datos notó que los dos primeros ítems más frecuentes son el café y el pan, sin importar la hora o el tipo de día. El tercer ítem es idéntico en las mañanas y en las tardes sin importar el tipo de día. A partir del cuarto ítem ya se empiezan a diferenciar los productos más frecuentes.
5.4 Reformulación de la pregunta de negocio
Claramente, esta exploración mostraba que existe diferencia entre el comportamiento de las ventas, entre el tipo de día (weekday_weekend) y el momento del día (period_day) y, por tanto, deberían tomarse decisiones diferentes para los días y los momentos del día.
Estos hallazgos llevaron al científico de datos y al analytics translator a replantearse las preguntas de negocio iniciales. Tras consultas con los tomadores de decisiones, por parte del analytics translator, se replantearon las preguntas de negocio de tal manera que las nuevas preguntas de negocio fueron:
- ¿Existe alguna diferencia entre las reglas de asociación, dependiendo del tipo de día (
weekday_weekend) y el momento del día (period_day)? - ¿Tiene sentido hacer un descuento en el café?
- ¿Se puede crear un combo con sentido que sirva cualquier día y en cualquier momento del día?
- ¿Qué recomendaciones se pueden hacer para vender más té?
5.5 Modelado
Con las preguntas ya claras y el conocimiento de los datos y del negocio, el científico de datos procedió a encontrar las reglas por tipo de días y momento del día. El científico de datos, de común acuerdo con el analytics translator, decidió emplear umbrales para el soporte de 1% (0.01) y para la confianza de 25% (0.25). Así mismo, decidieron solo reportar reglas con, por lo menos, un ítem en el RHS y en el LHS.
Se encontraron el siguiente número de reglas no redundantes:
- 21 para los días de la semana en la tarde,
- 37 para los fines de semana en la tarde,
- 17 para los días de la semana en la mañana y
- 26 para los fines de semana en la mañana.
Con las reglas encontradas para cada uno de estos grupos, el científico de datos y el analytics translator procedieron a analizar los resultados.
5.6 Resultados por tipo y momento del día
Para poder encontrar los insights para el negocio, el científico de datos preparó tablas y visualizaciones que permitieran entender mejor las reglas encontradas. Con estos insumos, se sentaron con el analytics translator a analizar los resultados.
5.6.1 Reglas para los días de la semana por la tarde
Las reglas identificadas por el científico de datos para los días de la semana por la tarde se reportan en la Figura 5.9. En las Figuras 5.10 y 5.11 se presentan visualizaciones de las métricas de las reglas.
La canasta de las transacciones registradas en la franja de la tarde de los días laborales muestra un patrón de consumo claro: las bebidas calientes, en particular Coffee, funcionan como “eje” de la mayoría de las 21 reglas detectadas. Según la Figura 5.9,, ocho de las diez reglas con mayor lift presentan a Coffee como consecuente directo y las dos restantes a Tea, lo que confirma que los productos de pastelería suelen comprarse como acompañantes de la bebida estrella. Un ejemplo es la regla \(\left\{ Pastry \right\} \rightarrow \left\{ \text{Coffee} \right\}\), cuyo lift es 1.41, la confianza 0.64 y la cobertura 0.14; es decir, la canasta ocurre un 41 % más de lo esperado si los ítems fueran independientes y aparece en el 14% de las transacciones de la tarde de los días laborales.
Aunque el soporte individual de los artículos rara vez supera el 3%, el lift elevado indica que el emparejamiento no es cuestión del azar. Este resultado presenta oportunidades para dinamizar ventas mediante promociones dirigidas. En el extremo opuesto, la regla \(\left\{ Soup \right\} \rightarrow \left\{ Tea \right\}\), con un lift de 1.62 y soporte de 0.02, revela un nicho reducido pero coherente: clientes que prefieren una combinación ligera a media tarde. Tal segmento es ideal para ensayar un “combo” de sopa + té sin canibalizar la demanda principal de café.
Figura 5.9: Resultados de aplicar el algoritmo Apriori a las transacciones de los días de semana en la tarde
Figura 5.10: Visualización de las métricas de las reglas obtenidas al aplicar el algoritmo Apriori a las transacciones de los días de semana en la tarde.
Figura 5.11: Visualización alternativa de las reglas obtenidas al aplicar el algoritmo Apriori a las transacciones de los días de semana en la tarde.
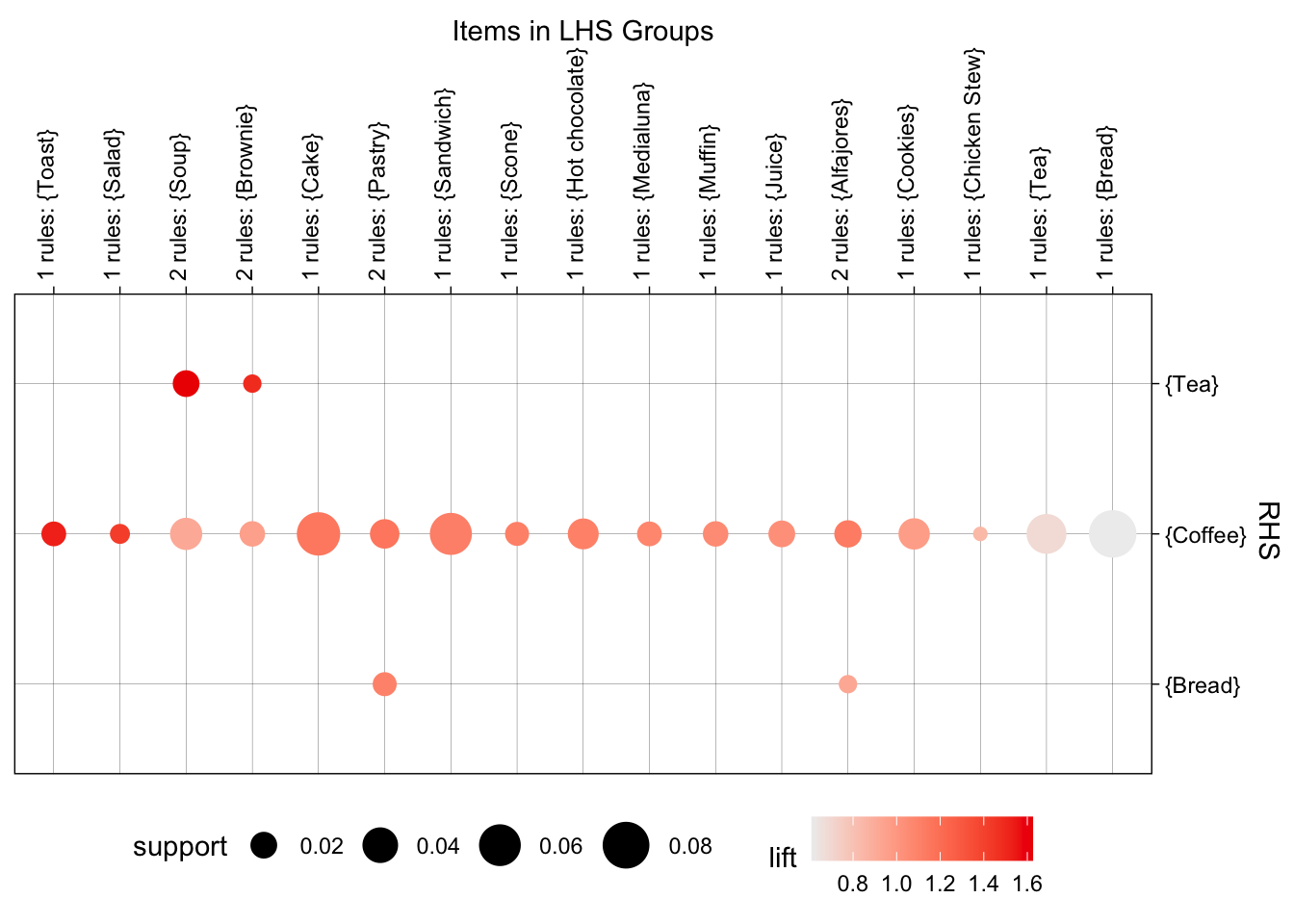
La nube de soporte y lift que aparece en la Figura 5.10 muestra dos grupos: reglas con bajo soporte, pero alto lift (nichos diferenciadores) y reglas con soporte y confianza medias (combinaciones frecuentes, menos probables). La Figura 5.11 completa el panorama al mostrar al Coffee como el consecuente de la mayoría de las reglas encontradas.
5.6.2 Reglas para los fines de semana por la tarde
Las reglas identificadas por el científico de datos para los fines de semana por la tarde se reportan en la Figura 5.12. En las Figuras 5.13 y 5.14 se presentan visualizaciones de las métricas de las reglas.
El análisis de las reglas de asociación para las tardes de los fines de semana encontró 37 reglas. En este caso, las reglas con mayor lift están principalmente dirigidas hacia productos de pastelería (Cake) y bebidas calientes como el té (Tea). La regla con el lift más alto es \(\left\{ \text{Coffee, Hot chocolate} \right\} \rightarrow \left\{ Cake \right\}\), con un valor de 2.07. Este lift implica que, cuando se compran conjuntamente café y chocolate caliente, la probabilidad de adquirir pastel se incrementa en un 107% respecto a lo esperado bajo independencia. De manera similar, otras reglas que apuntan hacia la compra de Cake tienen altos valores de lift, indicando que en las tardes de fin de semana, el pastel actúa como un complemento habitual de las bebidas calientes.
Por otro lado, aunque con menor lift relativo, se destacan las asociaciones cuyo consecuente es Coffee, en especial aquellas que provienen de alimentos salados o preparaciones específicas como ensaladas o brunches (Spanish Brunch, Salad y Hearty & Seasonal). Estas reglas presentan valores de confianza alrededor del 60% y valores de lift que van desde 1.30 hasta 1.46, indicando asociaciones relevantes pero menos sorprendentes que las dirigidas hacia el pastel.
Además, se identifican reglas que vinculan productos típicos de merienda tradicional, como \(\left\{ Scone \right\} \rightarrow \left\{ Tea \right\}\), con un lift de 1.67 y un soporte cercano al 2%. Esta regla es particularmente interesante, dado que no apareció en el análisis realizado para días laborales, lo que señala un hábito de consumo exclusivo de fines de semana.
Figura 5.12: Resultados de aplicar el algoritmo Apriori a las transacciones del fin de semana en la tarde
Figura 5.13: Visualización de las métricas de las reglas obtenidas al aplicar el algoritmo Apriori a las transacciones de los fines de semana en la tarde.
Figura 5.14: Visualización de las reglas obtenidas al aplicar el algoritmo Apriori a las transacciones de los fines de semana en la tarde.
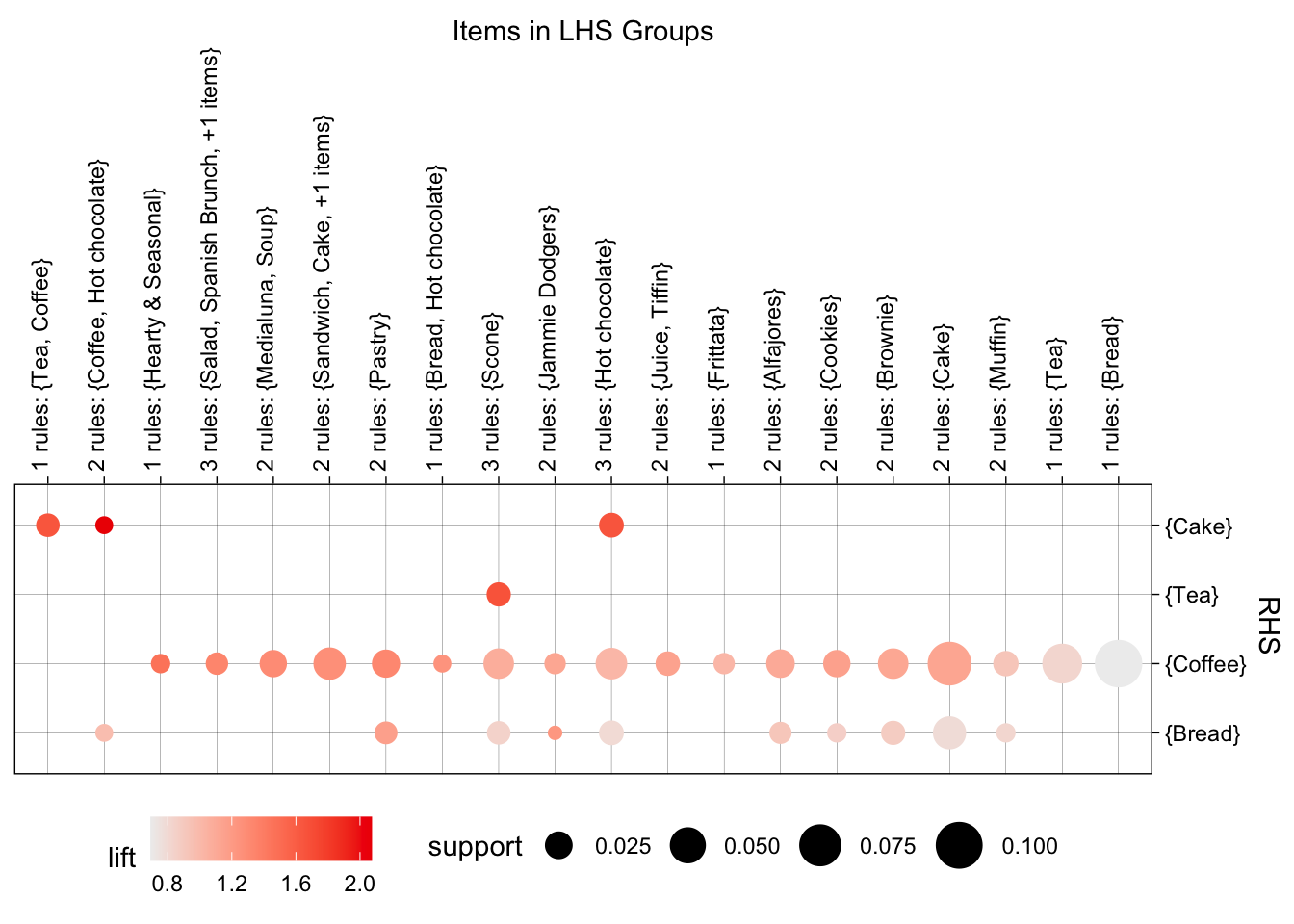
La Figura 5.13 también permite observar claramente dos grupos: reglas con alto valor de lift pero bajo soporte (generalmente asociadas con pastel) y reglas con soporte medio y confianza alta, típicamente asociadas al café. La Figura 5.14 muestra que también tenemos reglas de asociación cuyo consecuente es el pan (Bread), pero siempre acompañado como consecuente de café o pastel.
Estos resultados subrayan diferencias notables en los patrones de consumo durante las tardes de los fines de semana respecto a los días laborales, destacándose especialmente por la centralidad del pastel y la aparición de combinaciones específicas propias del fin de semana.
5.6.3 Reglas para los días de la semana por la mañana
Las reglas identificadas por el científico de datos para los fines de semana por la tarde se reportan en la Figura 5.15. En las Figuras 5.16 y 5.17 se presentan visualizaciones de las métricas de las reglas.
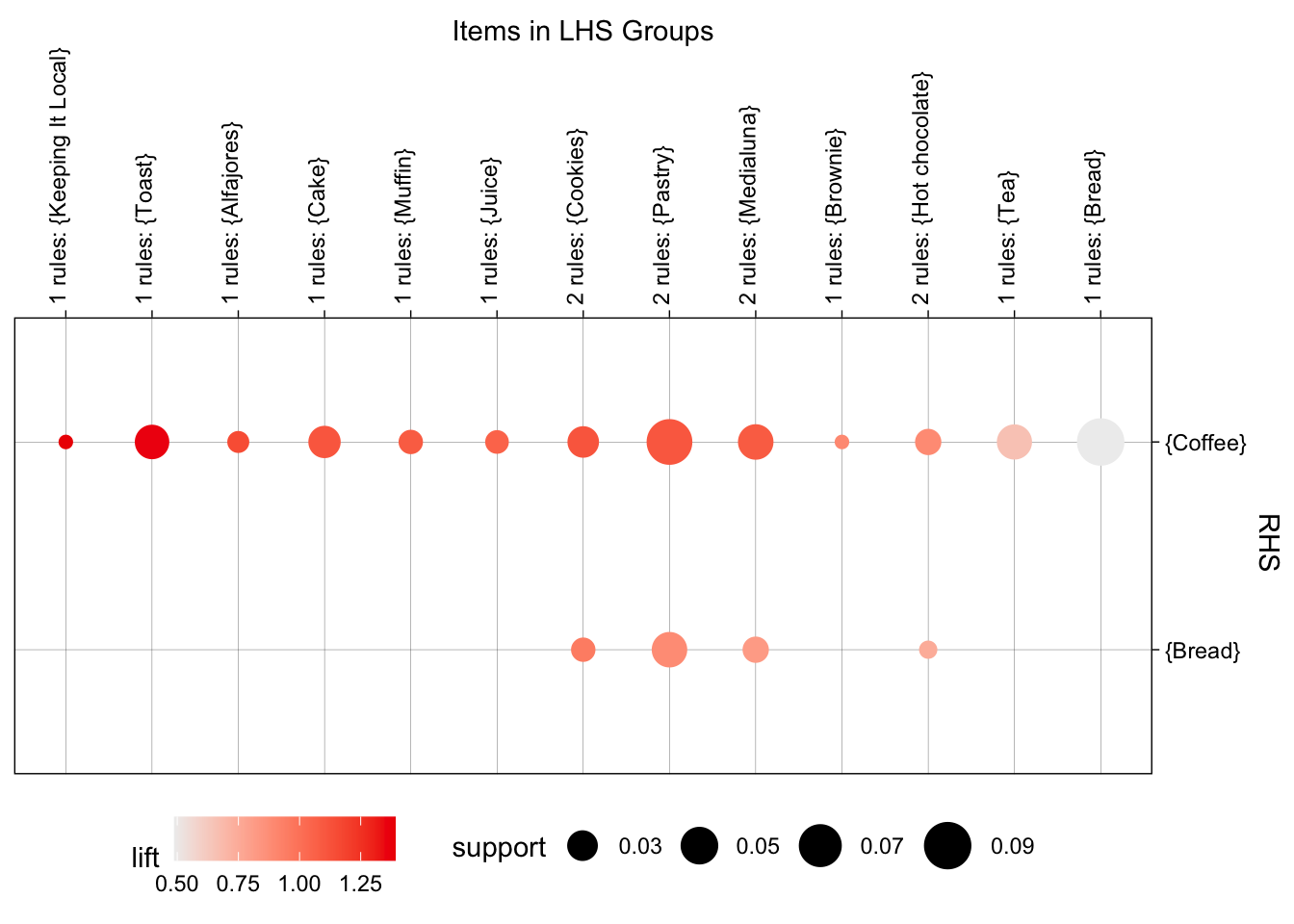
El análisis realizado para las transacciones correspondientes a las mañanas de los días laborales identificó 17 reglas no redundantes con un soporte mínimo del 1% y una confianza mínima del 25%. En esta franja horaria, la mayoría de las reglas tienen como consecuente bebidas calientes, particularmente Coffee, aunque aparecen tres reglas de asociación con consecuente Bread. La regla más destacada en términos de lift es \(\left\{ \text{Keeping It Local} \right\} \rightarrow \left\{ \text{Coffee} \right\}\), que registra un valor de 1.39. Esta regla sugiere que, durante las mañanas laborales, la compra de \(\text{Keeping It Local}\) incrementa en casi un 39% la probabilidad de adquirir café, respecto a lo que se esperaría si estas compras fueran independientes. De manera similar, otras combinaciones relevantes, como \(\left\{ Toast \right\} \rightarrow \left\{ \text{Coffee} \right\}\) y \(\left\{ Alfajores \right\} \rightarrow \left\{ \text{Coffee} \right\}\), presentan valores elevados de confianza (alrededor del 60%), pero cobertura relativamente baja, inferior al 10%.
Figura 5.15: Resultados de aplicar el algoritmo Apriori a las transacciones de la semana en la mañana
La Figura 5.16 muestra una concentración de reglas con soporte moderado (entre 2 % y 7 %) y confianza alta (superior al 50 %), especialmente aquellas cuyo consecuente es Coffee. Por otro lado, la Figura 5.17 proporciona una representación alternativa de estos resultados, en la que se visualiza claramente que las reglas con mayor soporte están asociadas al consumo de café. Esta figura complementa el análisis previo al mostrar visualmente la estructura y frecuencia de estas combinaciones en el segmento analizado.
Figura 5.16: Visualización de las métricas de las reglas obtenidas al aplicar el algoritmo Apriori a las transacciones de los días de la semana en la mañana.
Figura 5.17: Visualización de las reglas obtenidas al aplicar el algoritmo Apriori a las transacciones de los días de semana en la mañana.
5.6.4 Reglas para fin de semana por la mañana
Las reglas identificadas por el científico de datos para los fines de semana por la tarde se reportan en la Figura 5.18. En las Figuras 5.19 y 5.20 se presentan visualizaciones de las métricas de las reglas. Para las transacciones de las mañanas de los fines de semana, el análisis identificó 26 reglas no redundantes con un soporte mínimo del 1% y una confianza mínima del 25%.
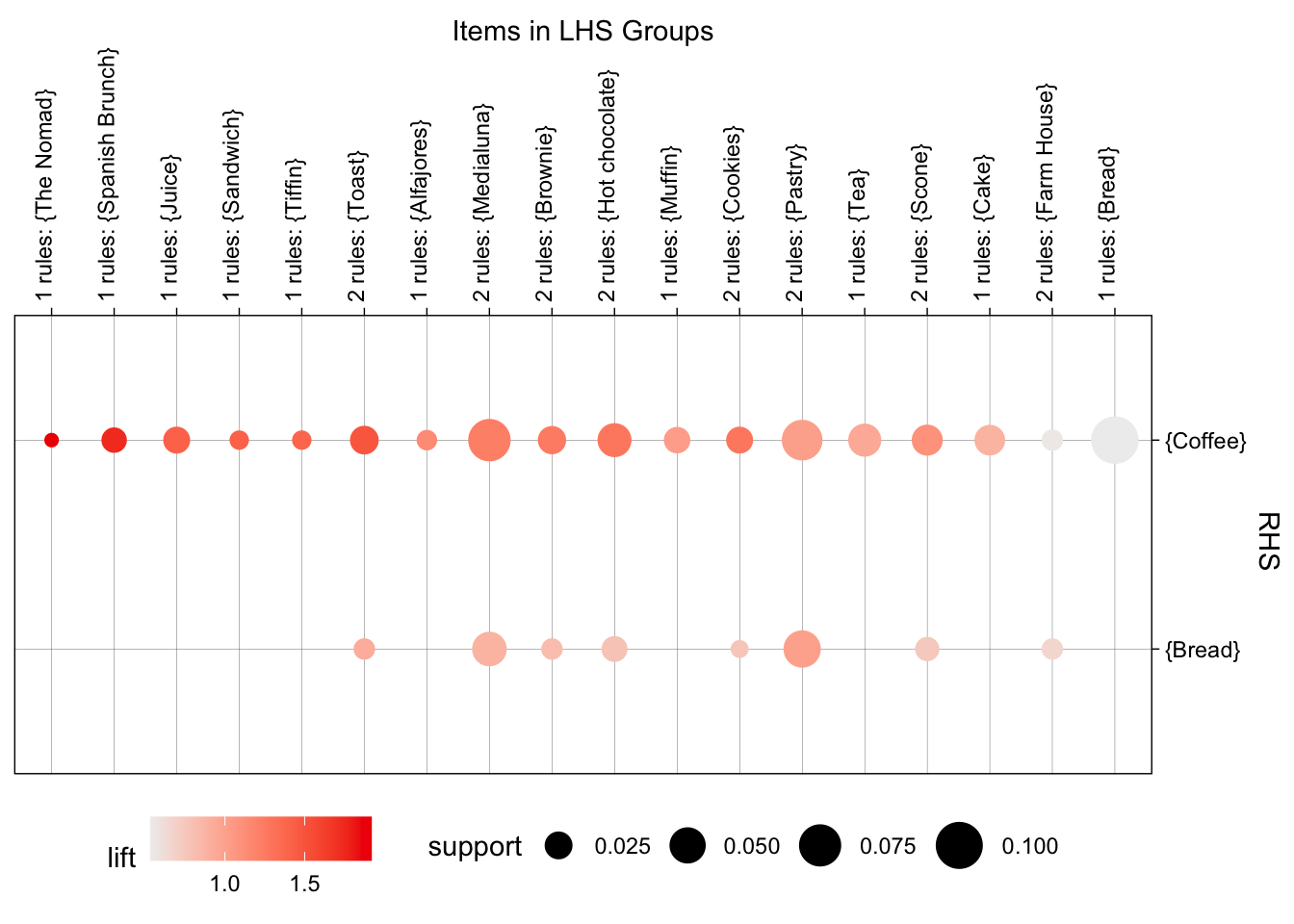
En esta franja sobresalen nuevamente reglas cuyo consecuente es el Coffee, acompañado como antecedente de productos típicos del desayuno o brunch como Toast, Pastry y Medialuna. La regla más destacada por su valor de lift es \(\left\{ \text{The Nomad} \right\} \rightarrow \left\{ Coffee \right\}\), con un valor de 1.92. Es decir, durante las mañanas de fin de semana, la compra de $ $ incrementa en un 92% la probabilidad de comprar café, en comparación con la compra independiente de estos productos. Asimismo, la regla \(\left\{ \text{Spanish Brunch} \right\} \rightarrow \left\{ Coffee \right\}\) presenta un alto valor de lift y confianza (85%).
Figura 5.18: Resultados de aplicar el algoritmo Apriori a las transacciones del fin de semana en la mañana
Figura 5.19: Visualización de las métricas de las reglas obtenidas al aplicar el algoritmo Apriori a las transacciones del fin de semana en la mañana.
La Figura 5.19 muestra que la mayoría de las reglas se concentran alrededor de un soporte del 2% al 6%. Adicionalmente, existen reglas menos frecuentes pero altamente relevantes desde la perspectiva del lift, lo que sugiere patrones muy específicos de consumo en estas mañanas de fin de semana.
Por su parte, la Figura 5.20 ofrece una visualización complementaria, evidenciando cómo las reglas con mayores valores de soporte involucran de manera consistente al café.
Figura 5.20: Visualización de las reglas obtenidas al aplicar el algoritmo Apriori a las transacciones de los fines de semana en la mañana.
5.7 Insights
Con estos resultados, el científico de datos y el analytics translator se sentaron a generar los insights para el negocio. Para esto empezaron a responder las preguntas de negocios planteadas (Ver Sección 5.4). Ellos ya estaban convencidos de que la primera pregunta (¿existe alguna diferencia entre las reglas de asociación según el tipo de día y el momento del día?) ya se podía resolver. Tras examinar los cuatro subconjuntos resultantes de cruzar weekday/weekend con morning/afternoon, la respuesta era evidente.
En las mañanas de los días de semana se detectaron 17 reglas no redundantes: el 82 % culmina en Coffee y el 18 % en “Bread”. Predomina un consumo funcional; reglas como \(\left\{ \text{Toast} \right\} \rightarrow \left\{ Coffee \right\}\)” o \(\left\{ \text{Farm House Toast} \right\} \rightarrow \left\{ Coffee \right\}\) muestran lifts cercanos a 1.4 y confianzas en torno al 60 %, lo que sugiere que los consumidores están buscando energía rápida más que indulgencia para iniciar su jornada laboral. Cuando llega el fin de semana por la mañana, el número de reglas asciende a 26 y los consecuentes se reparten entre Coffee (69%) y Bread (31%). Aparece así un “desayuno relajado”: combinaciones como \(\left\{ \text{Spanish Brunch} \right\} \rightarrow \left\{ Coffee \right\}\)” tienen soportes inferiores al 2% pero lifts de 1.745, señal de un nicho que aprecia este tipo de desayunos. También aparecen reglas como \(\left\{ \text{Alfajores} \right\} \rightarrow \left\{ Coffee \right\}\) que muestran algunos consumidores buscando un toque indulgente.
El panorama cambia en la tarde de los días de semana, donde emergen 21 reglas. Coffee concentra el 81% de los consecuentes, seguido de Tea (9.5%) y Bread (9.5%). Las reglas \(\left\{ \text{Soupe} \right\} \rightarrow \left\{ Tea \right\}\) y \(\left\{ \text{Salad} \right\} \rightarrow \left\{ Coffee \right\}\) presentan un lift relativamente alto, mostrando un patrón de reglas más asociado a un almuerzo rápido. Finalmente, la tarde de fin de semana presenta 37 reglas. Coffee corresponde al 62% de los consecuentes de las reglas encontradas, Bread al 27% y Cake domina el 8%. La regla \(\left\{ \text{Coffee, Hot chocolate} \right\} \rightarrow \left\{ Cake \right\}\) presenta un lift superior a 2,0, reflejando un comprador que se premia con ítems dulces durante el fin de semana.
La comparación entre mañana y tarde confirma que el desayuno se centra en bebidas calientes y pan básico, mientras que las tardes añaden repostería y bebidas especiales, con lifts más elevados en sábado y domingo. Estos resultados muestran que sí existe diferencia entre las reglas de asociación según el tipo de día y el momento del día. Los resultados justifican la necesidad de estrategias diferenciadas de bundling, precios y exhibición según franja y tipo de día.
Tras responder la primera pregunta, el analytics translator y el científico de datos centran su atención a la tercera pregunta: ¿se puede crear un combo con sentido que sirva cualquier día y en cualquier momento del día?
La primera reacción es responder no, pues las reglas son diferentes. No obstante, una lectura transversal de las reglas muestra que la canasta que contiene Coffee y Pastry, donde Pastry incluye medialunas, croissants y piezas de hojaldre, aparece con métricas consistentes en los cuatro escenarios analizados. En las mañanas de días laborales las reglas del tipo \(\left\{ \text{Pastry} \right\} \rightarrow \left\{ Coffee \right\}\) alcanza un soporte del 8% y una confianza del 59%, con lift de 1.1; en las mañanas de fin de semana mantiene un soporte del 7% y lift de 1.01; en las tardes laborales aparece con confianza del 64% y lift de 1.41; y en las tardes de fin de semana exhibe un soporte del 3%, confianza del 61% y lift de 1.32. Estas métricas indican que, aunque la intensidad varía, la asociación se mantiene positiva y relevante en cualquier día y momento.
Desde la lógica comercial, el combo Coffee y Pastry tiene sentido universal: responde al impulso de energía rápida de la mañana, al antojo de media tarde y al hábito indulgente del fin de semana. Su soporte agregado ronda el 6% de todas las transacciones, suficiente para garantizar rotación, y el lift no cae por debajo de la unidad, lo que significa que el combo vende siempre más de lo esperado bajo independencia.
Por tanto, el analytics translator decidió llevar como propuesta construir un combo base: Coffee y Pastry, con un precio ligeramente inferior al ticket promedio, sin restricción horaria, permitiendo variar la pieza de pastelería según el inventario (croissant a primera hora, brownie por la tarde). De este modo se aprovecha una regla robusta y se ofrece al cliente una oferta coherente, fácil de comunicar y operativamente simple de implementar.
Cuando tuvieron claras las respuestas a estas dos preguntas, procedieron a generar insights para responder una pregunta que genera mucha controversia en la panadería: ¿tiene sentido hacer un descuento en el café? La respuesta a esta pregunta ya era evidente: No tiene sentido hacer un descuento directo en el café. Los resultados sugieren que es mejor concentrar los incentivos en los acompañamientos o en combos, no en la bebida que ya se vende sola.
Los resultados del caso muestran que Coffee es, por sí mismo, el producto de mayor frecuencia en todas las franjas y tipos de día, entre el 45 y el 65% de las transacciones (Ver Figuras 5.8). Al mismo tiempo, las reglas donde el café actúa como consecuente apenas superan la independencia (lift de aproximadamente 1.1), lo que indica que las ventas del resto de los ítems apenas añaden probabilidad adicional sobre una demanda ya cautiva. Hacer un descuento en un artículo con alta rotación y bajo lift produciría una simple erosión del margen: los clientes seguirían pidiendo café, pagarían menos por él y el efecto arrastre sobre otros productos sería mínimo.
En cambio, las reglas con lifts realmente elevados (por ejemplo mayores a 1.5) involucran repostería o bebidas alternativas, lo que sugiere que el incentivo debe concentrarse en el acompañamiento o en el bundle, no en la bebida ancla. Por tanto, la estrategia óptima es mantener el precio del café y ofrecer promociones del tipo Coffee y Pastry con rebaja aplicada al pastel, o combos temáticos donde el té o el chocolate caliente se vendan con repostería premium. De esta forma se protege la rentabilidad del café, se impulsa el ticket medio y se potencian las asociaciones con mayor valor estratégico reveladas por el Market Basket Analysis.
Finalmente, el analytics translator y el científico de datos enfrentaron la última pregunta: ¿qué recomendaciones se pueden hacer para vender más té? Las reglas de asociación confirman que el té comparte un vínculo estructural con ítems “anzuelo” específicos, más que con descuentos directos en su propio precio. En la franja tarde de los días de semana la regla\(\left\{ \text{Soupe} \right\} \rightarrow \left\{ Tea \right\}\) muestra el lift más alto (1.62) y una confianza cercana al 30%; de forma análoga, en presencia de repostería premium (p. ej., Brownie o Pastry) el té mantiene lifts superiores a 1.4. Esto revela que la decisión de añadir una infusión se activa cuando el cliente se orienta hacia productos salados ligeros o dulces indulgentes.
Empleando estos insumos, el analytics translator llega a la conclusión de que la promoción idónea no es rebajar el precio del té, sino empaquetarlo con los detonantes que elevan su probabilidad de compra. Un menú fijo “Sopa del día + Té”, visible solo de 12:00 a 18:00 en días laborales, capitaliza la regla más poderosa y refuerza la percepción de almuerzo ligero. De modo complementario, la barra puede ofrecer un upgrade de bebida caliente a quienes eligen repostería premium: “¿Brownie? Pruébalo con nuestro té Earl Grey”, dejando la rebaja (si la hay) en el pastel, no en la infusión. Para los sábados y domingos, donde la indulgencia se dispara, un paquete “Tea-time” de dos porciones de pastel y dos tés sueltos premium (stock limitado, 15–18 h) introduce sensación de ocasión especial y evita la canibalización del café.
El analytics translator también pensó en la visibilidad del producto. Los resultados soportan que puede ser una buena idea reubicar las variedades de té junto a sopas o ensaladas en la vitrina, y crear en la carta digital la sección “Light lunch + Tea”, facilitan la asociación mental que refleja el MBA. Añadir un mensaje de valor —“Recarga de agua caliente gratis” entre las 10 h y las 12 h— prolonga la experiencia sin costo significativo y resulta especialmente atractivo para quienes trabajan desde la cafetería. Por último, propone una campaña personalizada en la app o por SMS, dirigida a clientes con reiteradas compras de repostería pero sin historial de té, puede ofrecer un cupón de 15% para su primera infusión.
Con todos estos insights, el analytics translator y el científico de datos procedieron a construir una presentación que les permita transmitir todos los insights para facilitar la toma de decisiones del negocio.
5.8 Comentarios finales
A lo largo de este Capítulo seguimos el camino completo de un MBA, desde la depuración de la base del Bread Basket hasta la extracción, visualización e interpretación de reglas de asociación. Primero segmentamos los datos por tipo de día y franja horaria. Esto se debe a que los datos mostraban que los patrones de consumo y las canastas de compra no eran iguales. Por ejemplo, los clientes en la mañana laboral buscaban energía funcional, mientras que en la tarde del fin de semana se premiaban con repostería premium. Esta decisión metodológica, aunque parece simple en términos de cálculo, es muy importante para obtener información. Ayudó a encontrar señales que se habrían perdido en un análisis general, como el papel de la sopa para impulsar las ventas de té o la fuerza del café como producto principal. Como resultado, se encontró en un conjunto de reglas no redundantes, robustas y accionables, sustentadas con métricas de soporte, confianza y lift.
Los hallazgos tienen implicaciones estratégicas directas. Mantener el café sin promociones y centrar las ofertas en sus acompañantes preserva el margen de la bebida de mayor rotación. Los bundles “Coffee & Pastry” o “Sopa + Té” capturan patrones universales y de nicho sin necesidad de jugosos descuentos, mientras que la reubicación física y digital de los tés junto a productos salados ligeros multiplica su visibilidad. Al mismo tiempo, el ejercicio de business analytics nos sugiere tácticas de personalización que van más allá del mostrador. Por ejemplo, un cupón dirigido a quienes compran brownies pero nunca té, o una notificación in-app que aparece cuando el carrito incluye sopa. Estas acciones convierten la minería de reglas en una palanca de CRM.
Desde un enfoque práctico, el caso muestra la importancia de establecer niveles de soporte y confianza que se alineen con la realidad del negocio. También destaca la necesidad de eliminar reglas repetitivas para no abrumar a los tomadores de decisiones con información innecesaria y elegir visualizaciones claras y útiles en lugar de complicadas. Las visualizaciones, bien combinadas, permiten al analytics translator conectar la intuición del gerente con la evidencia estadística del científico de datos.
Es importante reconocer las limitaciones del ejercicio. Trabajamos con un histórico de dieciocho meses y con tickets de un único punto de venta; ignoramos información de precios y márgenes unitarios; y no modelamos estacionalidad ni efectos de promociones pasadas. Cada una de estas ausencias es, al mismo tiempo, una oportunidad para expandir el análisis: reglas secuenciales, canastas en cliente, integración con pronósticos de demanda y pruebas A/B que midan el impacto financiero de los bundles propuestos.
Una implementación exitosa requerirá una hoja de ruta sencilla: ajustar combos, re-exhibir productos clave, lanzar campañas personalizadas y refrescar el MBA de forma trimestral. El indicador final no será el número de reglas descubiertas, sino la evolución del ticket medio, la rotación de inventario y la satisfacción del cliente.
Con esta aplicación cerramos este libro. Mostrando cómo una técnica clásica, aplicada con rigor y traducida con claridad, se transforma en decisiones que generan valor tangible. Queda en tus manos experimentar, medir y compartir lo aprendido, alimentando un ciclo virtuoso de mejora continua. Recuerda que “en el mundo del business analytics, ¡la imaginación es el límite!”.
Anexo con código del caso
El siguiente código fue empleado para obtener los resultados de esta Capítulo.
Carga y exploración de los datos
En esta sección se presenta el código empleado para generar los resultados de la Sección 5.3. Primero se cargan los paquetes y los datos.
# Cargar paquetes
library(tidyr)
library(dplyr)
library(lubridate)
library(data.table)
library(xts)
library(ggplot2)
library(forcats)
# Leer datos
pan <- read.csv("./05-Caso/bread basket.csv")
# Convertir period_day y weekday_weekend a factor
pan <- pan %>%
mutate(across(c("period_day", "weekday_weekend"), as.factor))El siguiente código permite construir el Cuadro 5.1.
# Descripción de los datos
tabla_period_day <- pan %>%
select(-Item, -date_time ) %>%
unique() %>%
select(-Transaction)
# Crear tabla de frecuencias (absolutas)
tabla_period_day <- table(tabla_period_day$period_day, tabla_period_day$weekday_weekend, dnn = c("Momento del día", "Tipo de día"))
tabla_period_day <- addmargins(tabla_period_day, margin = c(1, 2))
# Crear tabla de frecuencias (relativas)
tabla_period_day <- round(tabla_period_day / tabla_period_day[5,3] * 100,2)
tabla_period_dayCon el siguiente código se eliminan las observaciones para la noche.
# eliminar las observaciones que corresponden a night y evening
pan <- pan %>%
filter(period_day %in% c("morning", "afternoon")) %>%
droplevels() # se requiere quitar los niveles de los factores que ya no son útilesEl Cuadro 5.2 se produce con las siguientes líneas de código:
tabla_period_day_2 <- pan %>%
select(-Item, -date_time ) %>%
unique() %>%
select(-Transaction)
tabla_period_day_2 <- table(tabla_period_day_2$period_day, tabla_period_day_2$weekday_weekend, dnn = c("Momento del día", "Tipo de día"))
tabla_period_day_2 <- addmargins(tabla_period_day_2, margin = c(1, 2))
tabla_period_day_2 <- round(tabla_period_day_2 / tabla_period_day_2[3,3] * 100,2)El siguiente código genera el gráfico de calendario que se reporta en la Figura 5.1).
transacciones_todas <- full_join(transacciones_totales, transacciones_morning, by = "date") %>%
full_join(transacciones_afternoon, by = "date")
# instalar el paquete si no se tiene
# install.packages("tbl2xts")
# Cargar el paquete
library(tbl2xts)
# Crear objeto de clase serie de tiempo (clase xts)
trans_total <- tbl_xts(transacciones_todas) %>%
na.fill( fill = 0.00)
# Chequear la clase del objeto
class(trans_total)
# Guardar la variable date_time en formato fecha
temp <- as.POSIXlt(pan$date_time, format="%d-%m-%Y %H:%M")
# instalar el paquete si no se tiene
# install.packages("lubridate")
# Cargar el paquete
library(lubridate)
# Crear la variable ´date´
pan$date <- date(temp)
# Crear la serie de tiempo de transacciones
transacciones_totales <- pan %>%
select(Transaction, date ) %>%
group_by(date) %>%
tally(name = "total")
transacciones_morning <- pan %>%
filter(period_day == "morning") %>%
select(Transaction, date ) %>%
group_by(date) %>%
tally(name = "morning")
transacciones_afternoon <- pan %>%
filter(period_day == "afternoon") %>%
select(Transaction, date ) %>%
group_by(date) %>%
tally(name = "afternoon")
transacciones_todas <- full_join(transacciones_totales, transacciones_morning, by = "date") %>%
full_join(transacciones_afternoon, by = "date")
# instalar el paquete si no se tiene
# install.packages("tbl2xts")
# Cargar el paquete
library(tbl2xts)
# Crear objeto de clase serie de tiempo (clase xts)
trans_total <- tbl_xts(transacciones_todas) %>%
na.fill( fill = 0.00)
# Chequear la clase del objeto
class(trans_total)
# instalar el paquete si no se tiene
# install.packages("openair")
# Cargar el paquete
library(openair)
# instalar el paquete si no se tiene
# install.packages("RColorBrewer")
# Cargar el paquete
library(RColorBrewer)
# crear paleta de 9 colores azules
colores <- brewer.pal(9, "PuBu")
calendarPlot(transacciones_todas, pollutant = "total", year = c(2016, 2017), key.position = "bottom", cols= colores) Las Figura 5.4 y la Figura 5.5 fueron construidas con el siguiente código:
transacciones_todas$day <- weekdays(transacciones_todas$date)
transacciones_todas %>%
pivot_longer(c("total", "morning", "afternoon"), names_to = "Momento", values_to = "Transacciones") %>%
mutate_at('Momento', as.factor) %>%
mutate(weekday_weekend = ifelse (day %in% c("Saturday", "Sunday"), "weekend", "weekday")) %>%
filter(Momento != "total") %>%
ggplot(aes(x=weekday_weekend, y =Transacciones, col = Momento )) +
scale_color_brewer(palette = "Dark2", type = "div") +
scale_fill_brewer(palette = "Dark2", type = "div") +
geom_boxplot( fill = "white", outlier.shape = NA) +
geom_jitter( size= 0.85, alpha = 0.5) +
ylab("Tipo de día") +
coord_flip() +
theme_minimal() +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(), legend.position = "bottom",
axis.line = element_line(linewidth = 0.5, colour = "gray"))
transacciones_todas %>%
pivot_longer(c("total", "morning", "afternoon"), names_to = "Momento", values_to = "Transacciones") %>%
mutate_at('Momento', as.factor) %>%
mutate(weekday_weekend = ifelse (day %in% c("Saturday", "Sunday"), "weekend", "weekday")) %>%
filter(Momento != "total") %>%
ggplot(aes(col=weekday_weekend, y =Transacciones, x = Momento )) +
geom_boxplot( fill = "white", outlier.shape = NA) +
geom_jitter( size= 0.85, alpha = 0.5) +
coord_flip() +
theme_minimal() +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(), legend.position = "bottom", axis.text.x = element_text(size = 4.5, angle = 0), axis.text.y = element_text(size = 5),
axis.line = element_line(linewidth = 0.5, colour = "gray"))Las Figuras 5.6 y 5.7 fueron construidas con el siguiente código:
transacciones_todas %>%
pivot_longer(c("total", "morning", "afternoon"), names_to = "Momento", values_to = "Transacciones") %>%
mutate_at('Momento', as.factor) %>%
mutate(weekday_weekend = ifelse (day %in% c("Saturday", "Sunday"), "weekend", "weekday")) %>%
filter(Momento != "total") %>%
ggplot(aes(col= Momento, x =Transacciones, fill = Momento )) +
scale_color_brewer(palette = "Dark2", type = "div") +
scale_fill_brewer(palette = "Dark2", type = "div") +
geom_density( alpha = 0.6) + ylab("Densidad") +
facet_wrap(~weekday_weekend) +
theme_minimal() +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(), legend.position = "bottom",
axis.line = element_line(linewidth = 0.5, colour = "gray"))
transacciones_todas %>%
pivot_longer(c("total", "morning", "afternoon"), names_to = "Momento", values_to = "Transacciones") %>%
mutate_at('Momento', as.factor) %>%
mutate(weekday_weekend = ifelse (day %in% c("Saturday", "Sunday"), "weekend", "weekday")) %>%
filter(Momento != "total") %>%
ggplot(aes(col= weekday_weekend, x =Transacciones, fill = weekday_weekend )) +
geom_density( alpha = 0.6) + ylab("Densidad") +
facet_wrap(~Momento) +
theme_minimal() +
theme(panel.grid.major = element_blank(), panel.grid.minor = element_blank(), legend.position = "bottom",
axis.line = element_line(linewidth = 0.5, colour = "gray")) La Figura 5.8 fue creada con el siguiente código:
## creación de datos
# datos afternoon weekday
datos_aft_week <- pan %>%
filter(period_day == "afternoon") %>%
filter(weekday_weekend =="weekday")
#número de transacciones en afternoon weekday
num_transacciones_aft_week <- n_distinct(datos_aft_week$Transaction)
top_productos_aft_week <- datos_aft_week %>%
group_by(Item) %>%
summarise(proporcion = n()/num_transacciones_aft_week) %>%
top_n(10, proporcion) %>%
arrange(proporcion)
# datos afternoon weekday
datos_aft_weekend <- pan %>%
filter(period_day == "afternoon") %>%
filter(weekday_weekend =="weekend")
#número de transacciones en afternoon weekday
num_transacciones_aft_weekend<- n_distinct(datos_aft_weekend$Transaction)
top_productos_aft_weekend <- datos_aft_weekend %>%
group_by(Item) %>%
summarise(proporcion = n()/num_transacciones_aft_weekend) %>%
top_n(10, proporcion) %>%
arrange(proporcion)
# datos morning weekday
datos_mor_week <- pan %>%
filter(period_day == "morning") %>%
filter(weekday_weekend =="weekday")
#número de transacciones en morning weekday
num_transacciones_mor_week <- n_distinct(datos_mor_week$Transaction)
top_productos_mor_week <- datos_mor_week %>%
group_by(Item) %>%
summarise(proporcion = n()/num_transacciones_mor_week) %>%
top_n(10, proporcion) %>%
arrange(proporcion)
# datos morning weekend
datos_mor_weekend <- pan %>%
filter(period_day == "morning") %>%
filter(weekday_weekend =="weekend")
#número de transacciones en morning weekend
num_transacciones_mor_weekend <- n_distinct(datos_mor_weekend$Transaction)
top_productos_mor_weekend <- datos_mor_week %>%
group_by(Item) %>%
summarise(proporcion = n()/num_transacciones_mor_weekend) %>%
top_n(10, proporcion) %>%
arrange(proporcion)
library(gghighlight)
p1 <- top_productos_mor_week %>%
mutate(Item=factor(Item, Item)) %>%
ggplot( aes(x = Item, y = proporcion)) +
geom_col(fill = blues9[6]) +
coord_flip()
p1 <- p1 + labs( y="Frecuencia relativa (proporción 0-1)",
x="item", title = "Mañanas en días de la semana") +
theme_minimal() + gghighlight(Item %in% c('Coffee', 'Bread', 'Pastry'), use_direct_label = F)
p2 <- top_productos_aft_week %>%
mutate(Item=factor(Item, Item)) %>%
ggplot( aes(x = Item, y = proporcion)) +
geom_col(fill = blues9[7]) +
coord_flip()
p2 <- p2 + labs( y="Frecuencia relativa (proporción 0-1)",
x="item", title = "Tardes en días de la semana") +
theme_minimal() + gghighlight(Item %in% c('Coffee', 'Bread', 'Tea'), use_direct_label = F)
p3 <- top_productos_mor_weekend %>%
mutate(Item=factor(Item, Item)) %>%
ggplot( aes(x = Item, y = proporcion)) +
geom_col(fill = blues9[6]) +
coord_flip()
p3 <- p3 + labs( y="Frecuencia relativa (proporción 0-1)",
x="item", title = "Mañanas en fin de semana") +
theme_minimal() + gghighlight(Item %in% c('Coffee', 'Bread', 'Pastry'), use_direct_label = F)
p4 <- top_productos_aft_weekend %>%
mutate(Item=factor(Item, Item)) %>%
ggplot( aes(x = Item, y = proporcion)) +
geom_col(fill = blues9[7]) +
coord_flip()
p4 <- p4 + labs( y="Frecuencia relativa (proporción 0-1)",
x="item", title = "Tardes en fin de semana") +
theme_minimal() + gghighlight(Item %in% c('Coffee', 'Bread', 'Tea'), use_direct_label = F)
library(ggpubr)
figura <- ggarrange(p1, p2, p3, p4,
ncol = 2, nrow = 2)
figura5.8.1 Modelado
En esta sección se presenta el código que generó los resultados de las secciones 5.5 y 5.6. Las reglas de asociación se encuentran con el siguiente código:
library(arules)
## creación de datos
# datos afternoon weekday
datos_aft_week <- pan %>%
filter(period_day == "afternoon") %>%
filter(weekday_weekend =="weekday")
datos_aft_week <- split(datos_aft_week$Item,
datos_aft_week$Transaction)
datos_tra_aft_week <- as(datos_aft_week, "transactions")
# datos afternoon weekday
datos_aft_weekend <- pan %>%
filter(period_day == "afternoon") %>%
filter(weekday_weekend =="weekend")
datos_aft_weekend <- split(datos_aft_weekend$Item,
datos_aft_weekend$Transaction)
datos_tra_aft_weekend <- as(datos_aft_weekend, "transactions")
# datos morning weekday
datos_mor_week <- pan %>%
filter(period_day == "morning") %>%
filter(weekday_weekend =="weekday")
datos_mor_week <- split(datos_mor_week$Item,
datos_mor_week$Transaction)
datos_tra_mor_week <- as(datos_mor_week, "transactions")
# datos morning weekday
datos_mor_weekend <- pan %>%
filter(period_day == "morning") %>%
filter(weekday_weekend =="weekend")
datos_mor_weekend <- split(datos_mor_weekend$Item,
datos_mor_weekend$Transaction)
datos_tra_mor_weekend <- as(datos_mor_weekend, "transactions")La visualización interactiva de las reglas se generan con el siguiente código:
# Tabla con resultados con solo 3 decimales
quality(reglas_aft_week)<-round(quality(reglas_aft_week),digits=3)
inspectDT(reglas_aft_week)
plot(reglas_aft_week, engine= "plotly")
library(arulesViz)
# analissi gráfico de los resultados
plot(reglas_aft_week, method="grouped")
Referencias
Esta conclusión surge de la misma base de datos que estudiaremos más adelante.↩︎
Estas preguntas de negocio son ficticias. Hasta aquí la narración corresponde a hechos reales documentados por otros autores y soportados en la base de datos. Las preguntas de negocio son construidas para efectos pedagógicos de este capítulo y no existe ninguna evidencia sobre cuál era la real pregunta de negocio o si existía alguna.↩︎
La narración de esta, y de las siguientes secciones, es ficticias y fue construida recreando lo que los autores consideramos una interacción común entre un analytics translator y un equipo de científicos de datos.↩︎
Es importante recordar que típicamente el horario de Evening va de 6 p.m. a 12 a.m y el del periodo night va de 12 a.m. a 6 a.m.↩︎
Los horarios de la mañana (morning) y tarde (afternoon) típicamente van de 6 a.m. a 12 p.m. y de 12 p.m. a 6 p.m., respectivamente.↩︎
El gráfico de calendario es una visualización de datos de series de tiempo que utiliza un formato de calendario para mostrar información temporal (Alonso & Largo, 2023). A diferencia de los gráficos de líneas, el gráfico de calendario muestra los datos en un contexto temporal natural, facilitando la identificación de patrones como estacionalidad o ciclos. Así mismo, esta visualización permite comparar fácilmente diferentes períodos (meses, años) al colocarlos uno al lado del otro. Adicionalmente, al emplear el formato familiar del calendario, esta visualización facilita la comprensión de los datos a personas sin experiencia en análisis de datos (Alonso & Largo, 2023).↩︎