2 Un ejemplo sencillo
2.1 Introducción
En el Capítulo 1 hicimos referencia a lo que es un MBA (sigla del término en inglés Market Basket Analysis o análisis de canasta). Sin embargo, aún debes tener muchas dudas acerca de qué es el MBA. En este capítulo emplearemos un ejemplo sencillo para aclarar conceptos fundamentales y explicar la lógica de las reglas de asociación del business analytics. De esta manera, este capítulo será de utilidad tanto para quien tiene el rol de científico de datos como para el analytics translator.
Al entender la lógica del proceso, es posible ejecutarlo (científico de datos) y saber qué decisiones se pueden tomar en el negocio (analytics translator) de acuerdo con las asociaciones propuestas. Este capítulo brinda los conceptos y el vocabulario que deben tener en común ambos roles para permitir la comunicación entre ellos. Las preguntas de negocio y la estrategia detrás de ellas serán comunicadas por el analytics translator a los científicos de datos. A su vez, los insights generados por el MBA realizado por los científicos de datos, que serán comunicados al analytics translator.
Por simplicidad, supongamos que estamos analizando datos de una tienda que solo vende cuatro productos: pan, leche, cerveza y pañales. Y con los datos queremos responder dos preguntas de negocio:
La leche, al ser un producto perecedero que requiere refrigeración, puede implicar altos costos de almacenamiento y exhibición. Por eso, un gerente de tienda puede estar tentado a no ofrecer este producto, pero esto podría implicar que se dejen de vender otros productos. En este orden de ideas. La primera pregunta será: ¿se puede retirar del portafolio de la tienda la leche sin afectar las compras de otros productos?
Por otro lado, se acerca la fecha de expiración del lote de pan que está en la góndola y, antes de tener que botar el producto, el gerente del punto de venta quisiera ofrecer el pan en un combo a sus clientes. De esta manera, la segunda pregunta de negocio es: ¿qué producto debería acompañar al pan en un “combo” promocional?
Para realizar nuestro MBA será necesario primero contar con datos de transacciones (Sección 2.2); también requeriremos métricas de asociación de productos y conjuntos de estos (Sección 2.3); y finalmente es necesario contar con algoritmos para seleccionar las reglas más interesantes (Sección 2.4). Veamos estos elementos en detalle.
2.2 Los datos
Supongamos, para facilitar nuestro aprendizaje, que tenemos datos para cinco transacciones de nuestra tienda que solo vende cuatro productos: pan, leche, cerveza y pañales. En el Cuadro 2.1 se ve el reporte de los productos comprados en las cinco transacciones que tenemos. Noten que cada transacción (fila del Cuadro 2.1) solo tiene información del producto que está presente en la canasta de compra; los datos no incluyen ni precios de cada uno de los productos, ni cantidades compradas de cada producto.
| ID | Productos |
|---|---|
| 1 | pan, leche |
| 2 | pan, cerveza, pañales |
| 3 | pan |
| 4 | pan, leche, cerveza, pañales |
| 5 | cerveza, pañales |
| Fuente: datos ficticios. |
En la primera compra (ID = 1) se incluyeron los productos pan, leche. Esta compra se denomina transacción. Estos productos comprados corresponden a una tirilla de compra18. Una canasta se define como el conjunto de artículos que se adquieren en una compra (transacción). En este contexto, a un artículo o producto se le denomina ítem19. Esta definición permite emplear en este contexto el término carrito de compra como sinónimo de canasta.
Nota que la primera canasta está conformada por los ítems pan, leche. La segunda canasta contiene los ítems pan, cerveza, pañales. En el Cuadro 2.1 tenemos cinco canastas diferentes, cada una identificada con un ID diferente. Es importante reconocer que en este tipo de análisis nos importa la presencia del ítem en la transacción y no la cantidad del ítem comprado. Cuando tenemos datos que reportan transacciones, como los reportados en el Cuadro 2.1, se dice que contamos con datos transaccionales. Así, para hacer un MBA necesitaremos contar con datos transaccionales.
Regresando al Cuadro 2.1, podemos observar que los pañales fueron comprados con cerveza en tres de las cinco transacciones. Lo que hace que los pañales y la cerveza sean un conjunto de ítems frecuente (en inglés, frequent itemset). Adicionalmente, el pan fue el ítem más frecuentemente comprado.
Para formalizar un poco, se emplea la teoría de los conjuntos (una rama de las matemáticas que trabaja con conjuntos). En este caso se emplean los corchetes ({}) para enumerar los elementos de un conjunto y se emplea la coma (,) para separar cada elemento del conjunto. Así, la primera canasta se expresará como:
\[
\left\{ pan, leche \right\}
\]
y la quinta canasta se representa como:
\[ \left\{ cerveza, pañales \right\} \]
Recordemos que en nuestro ejemplo, la tienda vende pan, leche, cerveza y pañales. Para hacer las cosas más fáciles, llamemos \(X\) al conjunto de todos los ítems que se pueden comprar en la tienda. Es decir, \[ X = \left\{ pan, leche, cerveza, pañales \right\} \]
De esta manera, todas las cinco transacciones observadas en el Cuadro 2.1 corresponden a subconjuntos de \(X\). Por ejemplo, la canasta tres es un subconjunto de tamaño uno (contienen un ítem de los cuatro ítems posibles). Las canastas uno y cinco son de tamaño dos.
El MBA en tu vida
Las películas o series que ves en Netflix u otro servicio de streaming se pueden también considerar como una canasta. De hecho, estas plataformas de streaming usan el MBA para sugerirte qué película o serie ver a continuación.
Las canciones que escuchas y tus playlists en Spotify también son consideradas como una canasta. Spotify utiliza algoritmos del MBA para recomendarte nueva música basada en tus preferencias reveladas en las canciones escuchadas y listas de reproducción anteriores.
Además, las compras que realizas en línea en plataformas como Amazon o Mercado Libre también emplean MBA para sugerir productos relacionados o complementarios a los que ya tienes en tu “carrito” de compra o en tus compras anteriores.
Todas estas aplicaciones son conocidas en el business analytics como modelos de recomendación. Los modelos de recomendación se definen como sistemas que sugieren ítems relevantes para los usuarios en función de sus preferencias o de consumidores similares y comportamientos pasados. Los modelos de recomendación pueden ser implementados empleando diferentes algoritmos que corresponden a diferentes “filosofías”.
Estos algoritmos pueden clasificarse según los algoritmos que se emplean en aquellos basados en:
Reglas de asociación (como las estudiadas en este libro): Estos algoritmos encuentran qué ítems son comprados con otros en la misma canasta y así sugieren aquellos ítems que aún no están presentes en la canasta del cliente. Estos algoritmos realizan la tarea de encontrar reglas de asociación.
Filtros colaborativos basados en el usuario (User-based collaborative filtering): Estos algoritmos generan recomendaciones al encontrar usuarios similares a través de sus comportamientos pasados. Estos algoritmos realizan la tarea de formar clústeres.
Filtros colaborativos basados en ítems (Item-based collaborative filtering): A diferencia de los algoritmos anteriores, estos emplean la similitud entre ítems basada en las valoraciones de los usuarios para encontrar ítems similares a los que le gustan al usuario. Estos algoritmos realizan la tarea de formar clústeres.
Modelos de factores latentes (Latent factor models): Estos algoritmos encuentran las relaciones entre usuarios e ítems. Estos modelos asignan a cada usuario y a cada elemento un conjunto de factores latentes que capturan las preferencias y características relevantes. Estos algoritmos realizan la tarea de hacer regresiones.
Ítems populares: Estos algoritmos no personalizados recomiendan a todos los usuarios los ítems más populares que aún no han valorado. Estos algoritmos realizan la tarea de resumir datos, al emplear estadísticas descriptivas para crear la recomendación.
Así, los algoritmos para encontrar reglas de asociación estudiados en este libro se pueden emplear para construir modelos de recomendación, pero no todos los modelos de recomendación emplean reglas de asociación.
Una manera de explorar los datos transaccionales es visualizándolos mediante una matriz de ítems (item matrix). La matriz de ítems permite tener una visión general de todas las transacciones y artículos al mismo tiempo. Es una visualización que en las columnas tiene los diferentes productos y en las filas cada una de las transacciones. Una celda oscura significa que el artículo pertenece a esa transacción, mientras que una celda blanca significa que el artículo no forma parte de la transacción. En la Figura 2.1 se presenta la Matriz de ítems para las transacciones de nuestro ejemplo registradas en el Cuadro 2.1.
Figura 2.1: Ítems por transacción
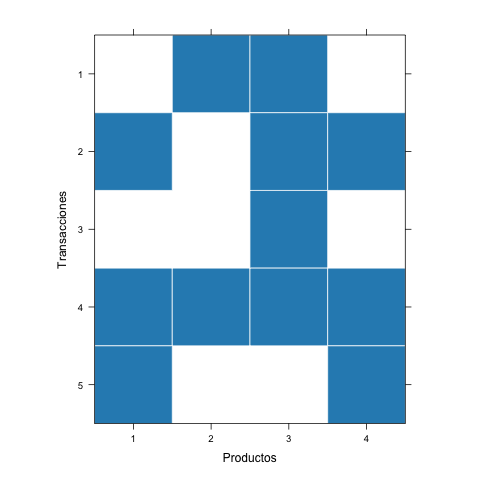
Hay que tener cuidado al emplear esta visualización cuando se trabaja con millones de transacciones, pues es posible que tu computador se congele al tratar de hacer la visualización o, en el mejor de los escenarios, será muy difícil observar algo en ella.
Este tipo de visualización proporciona una visión general de las transacciones y nos da indicios sobre la frecuencia con la que los artículos forman parte de las transacciones. De hecho, a partir de esta visualización se puede calcular una métrica conocida como la densidad de la matriz de ítems. Esta métrica es la relación entre las celdas sombreadas y el número total de celdas. En nuestro ejemplo tenemos 12 celdas de 20; es decir, una densidad del 60%. Una densidad del 100% implica que todas las canastas contienen todos los productos, mientras que una densidad del 0% implica que ninguna canasta contiene ningún producto.
Noten que, si bien la densidad de la matriz de ítems nos permite saber qué tan poblada es la matriz de ítems, esta métrica no nos permite determinar nada sobre la variedad de posibles cestas que se pueden construir. Solo nos muestra qué tanto se compran todos los ítems disponibles. Pero es importante tener cuidado cuando tengamos muchos ítems y transacciones; es posible que en esos casos la densidad no sea de interés para responder alguna pregunta de negocio.
De hecho, con los cuatro ítems que vende la tienda sería posible crear 16 canastas diferentes. En la Figura 2.2 se presentan todos los posibles subconjuntos que podemos crear de un conjunto \(X\) conformado por cuatro elementos (\(A\), \(B\), \(C\) y \(D\)). Es decir, \(X = \left\{ A, B, C, D \right\}\)
Figura 2.2: Todas las posibles canastas (subconjuntos) de un universo de 4 ítems.
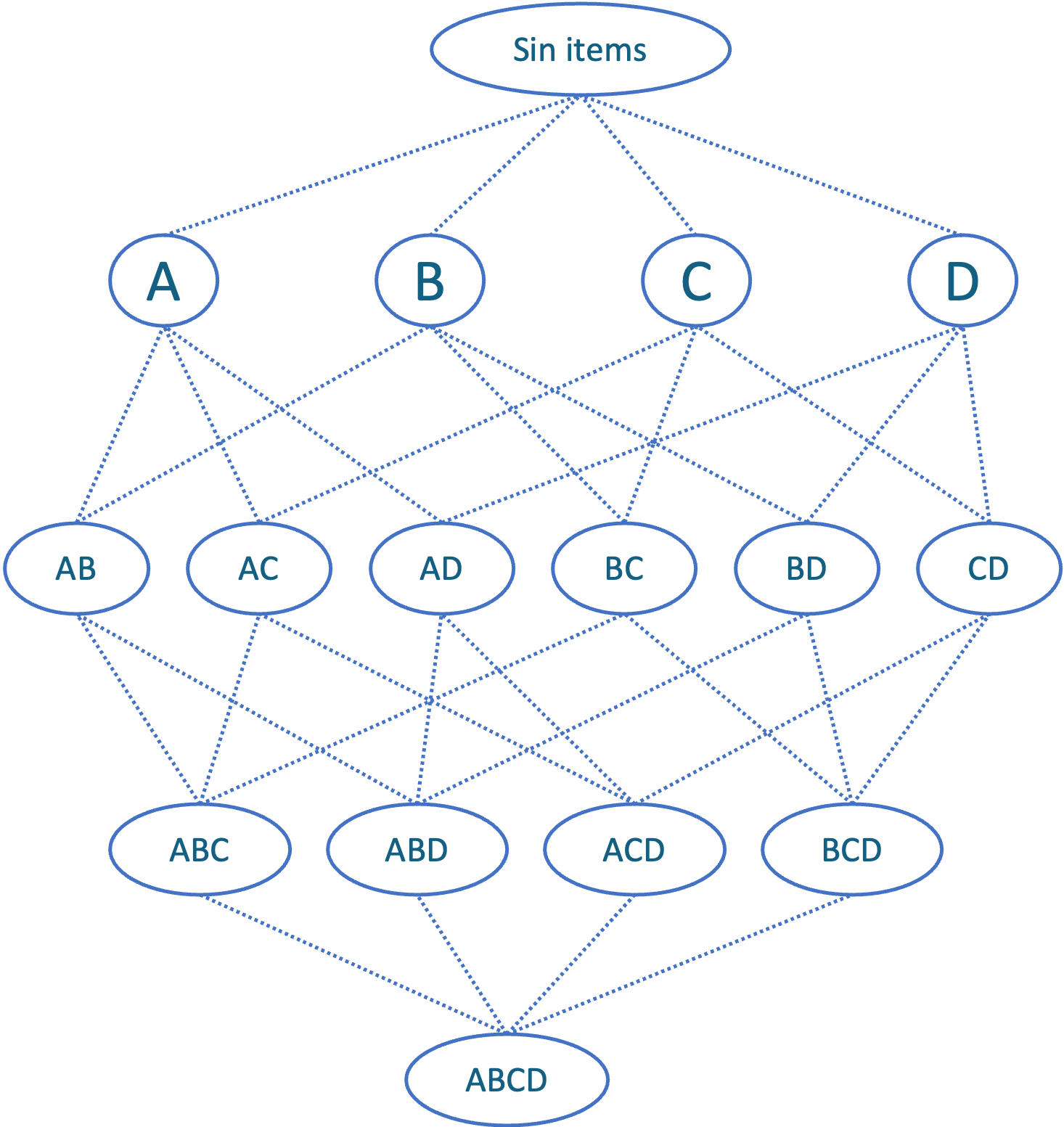
En general, si tenemos \(n\) ítems, entonces podremos crear \(2^n\) posibles canastas. Lo que hace que se aumente rápidamente el número de posibles canastas a medida que aumenta la cantidad de ítems disponibles. Esto hace el MBA mucho más retador cuando el número de productos disponibles en una tienda se hace grande. Para facilitar el estudio de las canastas y la selección de reglas, se han diseñado unas métricas que estudiaremos a continuación.
2.3 Métricas para itemsets y reglas de asociación
Una regla de asociación implica encontrar la relación entre un conjunto de productos que será probablemente comprado si ya está presente en la canasta un conjunto determinado de bienes. Por ejemplo, una regla de asociación podría ser: si ya están en la canasta cerveza y leche, se comprará pan. En general, se pueden construir reglas de asociación entre todos los (\(2^n\)) posibles subconjuntos. Pero esto no sería práctico dado que serán muchas reglas de asociación. Adicionalmente, algunas reglas de asociación serán irrelevantes al no ser observadas con frecuencia, es decir, al tener una poca probabilidad de ocurrencia. Por eso, en la práctica, queremos concentrar la atención solamente en reglas que sean potencialmente “relevantes”. Para establecer qué regla puede ser relevante, se emplean típicamente tres métricas de asociación:
- soporte (support en inglés),
- confianza (confidence en inglés),
- cubrimiento (coverage en inglés) y
- lift.
A continuación veremos cada una de estas medidas.
2.3.1 Soporte (de un itemset)
El soporte representa la “popularidad” de un conjunto de artículos o ítems. En la jerga del MBA, un conjunto de artículos se conoce por el término en inglés itemset20. El soporte de un itemset \(Y\) cualquiera (\(supp(Y)\)) es la proporción de transacciones en las que aparece el conjunto de ítems\(Y\) (como un subconjunto de cada transacción).
Formalmente, el soporte de un itemset \(Y\) se puede expresar como: \[ supp(Y)=\frac{freq(Y)}{N} \] donde \(freq(Y)\) es la frecuencia en que se observa el conjunto de productos \(Y\) y \(N\) es el número de canastas observadas en los datos.
Regresando a nuestro ejemplo, se reporta en el Cuadro 2.1, el itemset compuesto por solo el producto pan (\(Y = \left\{ pan \right\}\)) está contenido (es un subconjunto) de 4 de las 5 canastas. Por eso, el itemset pan tiene un soporte de 80% (4/5).
Tal vez sea más interesante conocer el soporte de itemsets que contengan más de un artículo. Por ejemplo, el itemset cerveza y pañales (\(Y = \left\{ cerveza, pañales \right\}\)) tiene un soporte del 60% (3 de 5 canastas). En el Cuadro 2.2 se muestran con negrita los itemsets que contienen cerveza y pañales en las tranasacciones observadas.
Nota que cuando hablamos del itemset cerveza y pañales (\(Y = \left\{ cerveza, pañales \right\}\)), nos estamos refiriendo a un itemset que es resultado de la unión de los subconjuntos \(A = \left\{ cerveza \right\}\) y \(B = \left\{ pañales \right\}\). Es decir, \(Y = A \cup B\).
| ID | Productos |
|---|---|
| 1 | pan, leche |
| 2 | pan, cerveza, pañales |
| 3 | pan |
| 4 | pan, leche, cerveza, pañales |
| 5 | cerveza, pañales |
| Fuente: elaboración propia. |
Por otro lado, el itemset de pan y leche tiene un soporte de 40% (2/5). De esta manera se puede calcular el soporte para todos los subconjuntos de canasta posibles. Es decir, para los (\(2^n\)) posibles subconjuntos, que en este caso del ejemplo son 16 (Ver Figura 2.2).
En la práctica emplearemos el soporte para “filtrar” aquellas reglas que solo incluyan itemsets con un determinado soporte. Por ejemplo, reglas con itemsets que tengan como mínimo un soporte del 20%.
2.3.2 Confianza (de una regla)
La confianza corresponde al porcentaje de veces que se incluye en la canasta el itemset \(B\) dado que ya estaba en la canasta el itemset \(A\). Es decir, es la probabilidad observada (frecuencia relativa) de la presencia del itemset \(B\) cuando ya estaba presente el itemset \(A\). En otras palabras, estamos calculando una métrica para una regla de la forma IFTTT: “si pasa esto, entonces ocurre aquello”. En este caso, si ya se tiene \(A\) en la canasta, entonces ocurre \(B\). Esta regla la podemos expresar de la siguiente manera empleando la notación de la teoría de conjuntos: \[ A \rightarrow B \]
\(A\) es conocido como el antecedente de la regla y \(B\) como el consecuente. \(A\) también es conocida en la literatura del MBA como la condición que se encuentra a mano izquierda (LHS en inglés por Left-Hand-Side) y, de manera análoga, \(B\) es la condición de la mano derecha (RHS en inglés por Right-Hand-Side).
Regresando a esta métrica, la confianza de la regla \(A \rightarrow B\) (\(conf(A \rightarrow B)\)) se define como la probabilidad que se dé la regla \(A \rightarrow B\) dado (condicional a) que \(A\) ya ocurrió. Visto de otra manera, la confianza es el soporte de la unión de \(A\) y \(B\) dividido por el soporte de \(A\). De manera formal, \[ conf(A \rightarrow B)=\frac{supp(A\cup B)}{supp(A)} \] Si te sientes más familiarizado con la notación empleada en los cursos de estadística, la confianza se puede interpretar como una estimación de la probabilidad de que ocurra el itemset \(B\) dado que ya se observó el itemset \(A\); formalmente, \(P\left ( \left.B \right| A \right )\).
Por ejemplo, la confianza de la regla \(cerveza \rightarrow pañales\) es de 1 o 100% ( \(supp(cerveza \cup pañales) = 3/5\) o 60% y \(supp(cerveza) = 3/5\) o 60%). Esto quiere decir que, en nuestro ejemplo, existe una probabilidad del 100% de observar pañales en la canasta, dado que ya se tiene cerveza en esta. Por otro lado, la confianza de la regla \(pan \rightarrow leche\) es de 0.5 o 50% ( \(supp(pan \cup leche) = 2/5\) o 40% y \(supp(pan) = 4/5\) o 80%). En otras palabras, según lo observado, cuando ya está el pan en la canasta, existe una probabilidad del 50% de que se incluya la leche.
También es posible calcular la confianza para itemsets que incluyan más de un producto. Por ejemplo, supongamos que queremos conocer la confianza de que se incluya pan en la canasta si ya se tiene cerveza y pañales en la canasta; es decir, la regla \(\left\{ cerveza, pañales\right\}\rightarrow pan\). En este caso, tenemos que el soporte del itemset \(\left\{ cerveza, pañales \right\}\) es del 60% (3 de 5 canastas) y el soporte del itemset \(\left\{ pan, cerveza, pañales \right\}\) es del 40% (2 de 5 canastas). Esto implica que la confianza de la regla \(\left\{ cerveza, pañales \right\} \rightarrow pan\) es 2/3 o 66.7%.
Nota que no necesariamente la confianza de la regla \(A \rightarrow B\) será igual a la de la regla \(B \rightarrow A\). Por ejemplo, intenta calcular la confianza de la regla \(pan \rightarrow \left\{ cerveza, pañales \right\}\).
Uno de los problemas que puede tener la confianza de la regla \(A \rightarrow B\) es que esta depende fuertemente de la popularidad de A y no de B, y esto puede sesgar la importancia de una regla de asociación. Por ejemplo, la confianza de la regla \(leche \rightarrow pan\) es de 1 o 100% por la baja popularidad de la leche. Recuerda que ya habíamos encontrado que la confianza de la regla \(pan \rightarrow leche\) es de 50%.
Así como el soporte, la confianza se puede calcular para todas las posibles combinaciones disponibles y es empleada en la práctica para concentrar nuestra atención a reglas que tengan una confianza relativamente alta21.
En otras palabras, el soporte y la confianza nos dan una medida de qué tan interesante puede ser un itemset y una regla, respectivamente. En un MBA las organizaciones22 establecen unos umbrales mínimos de soporte y confianza de tal manera que se pueda comparar la fortaleza de unos conjuntos de artículos (itemsets) y reglas a la luz de las prácticas y riesgos que quiera asumir la organización.
2.3.3 Lift (de una regla)
Para resolver el problema que tiene la confianza y tener en cuenta la popularidad individual de ambos itemsets, se ha creado la métrica de elevación (más conocida por el término en inglés lift). El lift de una regla \(A \rightarrow B\) es la confianza de esa regla dividida por el soporte del itemset \(A\). Es decir, \[ lift(A \rightarrow B)=\frac{conf(A \rightarrow B)}{supp(B)} \] O dicho de otra manera, es el soporte del itemset \(A \cup B\) relativo al soporte de \(A\) y \(B\). \[ lift(A \rightarrow B)=\frac{supp(A \cup B)}{supp(A) \cdot supp(B)} \]
Esta última expresión implica que el lift de una regla es la probabilidad conjunta de que dos itemsets aparezcan juntos en una transacción, dividida por el producto de las probabilidades individuales de observar cada uno de los itemsets independientemente.
Intuitivamente, el lift representa la probabilidad de que el itemset \(B\) se compre cuando se compra el conjunto de artículos \(A\), teniendo en cuenta la popularidad de \(B\). Es la relación entre el soporte observado de la regla \(A \rightarrow B\) y el soporte que se esperaría si la compra del itemset \(B\) fuera independiente del itemset \(B\). Por eso el lift tiene una interpretación interesante:
- Si \(lift(A \rightarrow B) = 1\), entonces no hay asociación entre los itemsets \(A\) y \(B\) (son independientes).
- Si \(lift(A \rightarrow B) > 1\), entonces es probable que se compre el itemset \(B\) si se compra el \(A\). En otras palabras, representa una asociación positiva entre los dos itemsets, lo que significa que los itemsets tienden a aparecer juntos con más frecuencia de lo esperado al azar.
- Si \(lift(A \rightarrow B) < 1\), entonces es poco probable que se compre el itemset \(B\) si se compra el \(A\). Es decir, existe una asociación negativa entre los dos itemsets, lo que significa que los itemsets tienden a aparecer juntos con menos frecuencia de lo esperado al azar.
En el caso de nuestro ejemplo, el lift de la regla \(cerveza \rightarrow pañales\) es de \(3/5 \approx 1.67\) ( \(conf(cerveza \rightarrow pañales) = 1\) y \(supp(pañales) = 3/5\) ). Lo que implica que es probable que se compren pañales cuando se compra cerveza. Por otro lado, el lift de la regla \(\left\{ cerveza, pañales \right\} \rightarrow pan\) es \((2/3) / (4/5) = 5/6 \approx 0.83\). Es decir, es poco probable que se compre pan si en la canasta ya está incluido el itemset \(\left\{ cerveza, pañales \right\}\).
De esta manera, el lift es una métrica que nos ayuda a determinar si la combinación de un producto o productos con otro u otros mejora las posibilidades de realizar una venta. Además, también podemos descubrir si una regla de asociación no tiene ningún efecto o, peor aún, si es perjudicial.
2.3.4 Cobertura (de una regla)
Una medida que nos permite entender la frecuencia con la que se puede aplicar la regla es la cobertura (en inglés, coverage o cover). La cobertura también es conocida como el soporte de la mano izquierda (en inglés Left Hand Side support o LHS-support). Como lo indica este último nombre, la cobertura es el soporte del itemset que es antecedente de la regla o condición que se encuentra a la izquierda (LHS). Por ejemplo, en la regla \(pan \rightarrow \left\{ cerveza, pañales \right\}\) el antecedente es el itemset conformado por pan. Entonces, la cobertura de la regla \(pan \rightarrow \left\{ cerveza, pañales \right\}\) sería igual a \(supp(pan) = 2/5\) o 40%. En otras palabras, la regla \(pan \rightarrow \left\{ cerveza, pañales \right\}\) se podría aplicar con una probabilidad del 40%.
2.4 Algoritmo para encontrar reglas
Hasta aquí hemos estudiado métricas que permiten caracterizar subconjuntos (itemsets) de productos como el soporte y reglas como la confianza, el lift y la cobertura. En la práctica, concentrar la atención en los \(2^n\) posibles itemsets o \(3^n - 2^{n+1} + 1\) posibles reglas de asociación será muy difícil. En el caso de nuestro sencillo ejemplo, una tienda con cuatro productos, estaríamos hablando de 16 itemsets y 50 reglas de asociación. Pero en el caso de un supermercado, fácilmente tendremos más de mil productos (\(n=1000\)), lo que convierte el número de itemsets y reglas en una magnitud muy grande.
Por eso la pregunta natural es: ¿cómo descartar las reglas que no son pertinentes empleando estas métricas? En otras palabras, necesitamos un algoritmo23 que nos permita descartar rápidamente reglas que potencialmente no serán interesantes.
El algoritmo más sencillo (pero potente) y más usado para esta tarea se conoce como el algoritmo Apriori24. El algoritmo Apriori fue propuesto por Agrawal et al. (1994) como un algoritmo que parte de todos los itemsets que contienen un solo producto y va considerando de manera iterativa itemsets que contienen un elemento más. Este tipo de aproximación se conoce como una aproximación de abajo hacia arriba (bottom-up en inglés). La idea detrás de este algoritmo es muy sencilla. Si un itemset \(\left\{ A \right\}\) con un solo producto es poco frecuente, entonces todos los itemsets que lo contengan (súperconjuntos), como \(\left\{A,B\right\}\), \(\left\{ A,C \right\}\) y \(\left\{A,B,C\right\}\), serán también infrecuentes. De esta manera, podemos descartar reglas que contengan los itemsets de un producto que sean relativamente poco populares25.
Así, el algoritmo Apriori implica los siguientes pasos:
Seleccionar todos los itemsets observados que tienen un solo producto.
Calcular el soporte de los itemsets seleccionados. Este paso se conoce como generación de candidatos.
Empleando el umbral aceptable para el soporte previamente establecido, descartar todos los itemsets seleccionados que no superen el umbral. Así mismo, descartar todos los itemsets más grandes que contengan los itemsets descartados.
Seleccionar los itemsets que tengan un producto más y realizar el paso 2 y 3 nuevamente.
Parar el algoritmo cuando no existan más itemsets para evaluar.
Veamos un ejemplo para entender la lógica de este algoritmo. Supongamos que un almacén tiene disponibles cinco ítems: (\(A\), \(B\), \(C\), \(D\) y \(E\)). En la Figura 2.3 se presentan todos los posibles itemsets.
Figura 2.3: Todas las posibles canastas (subconjuntos) de un universo de 5 ítems.
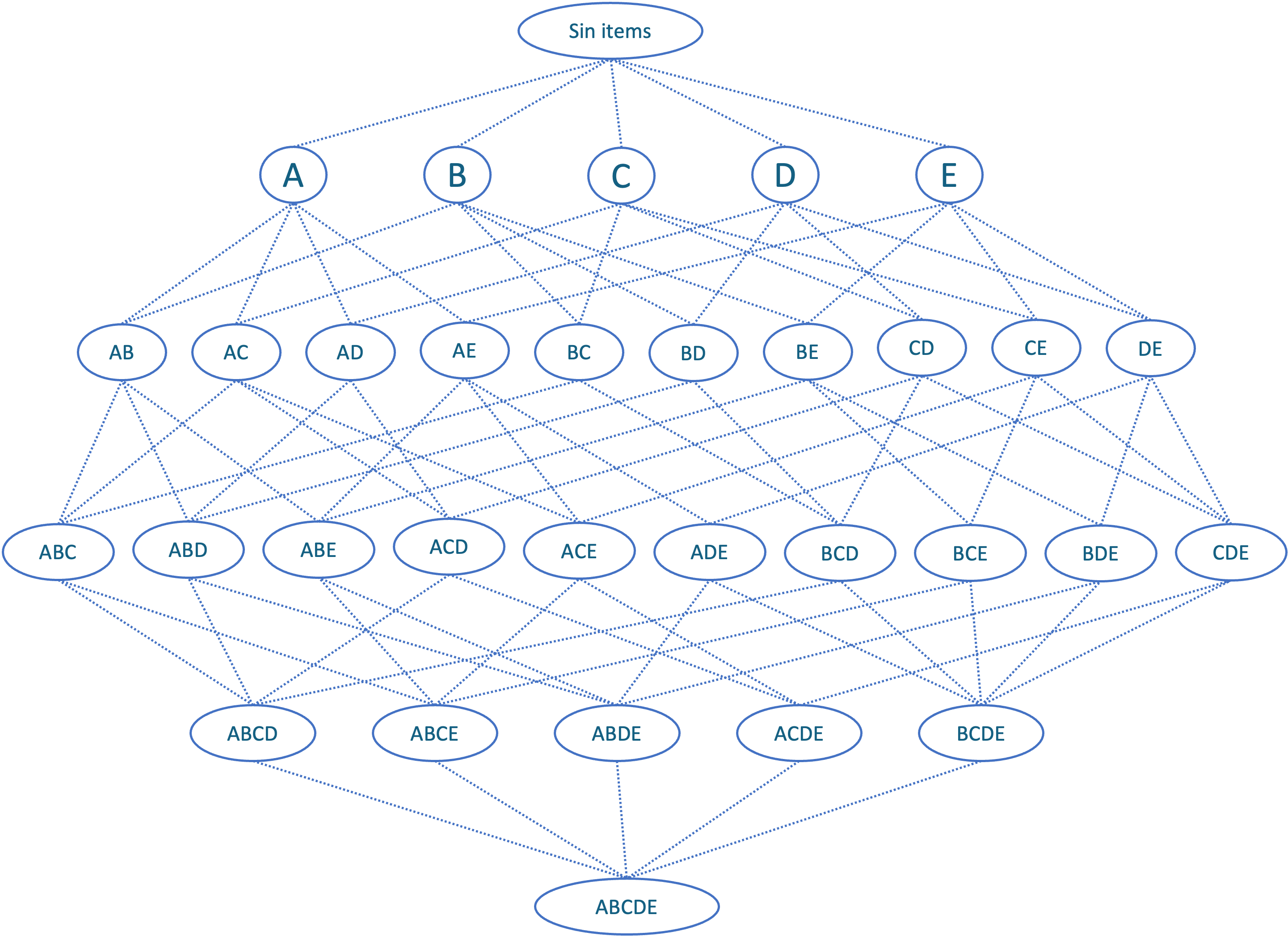
El primer paso del algoritmo implica empezar por los itemsets con un solo ítem como se muestra en la Figura 2.4.
Figura 2.4: Paso 1 del algoritmo A-Piori.
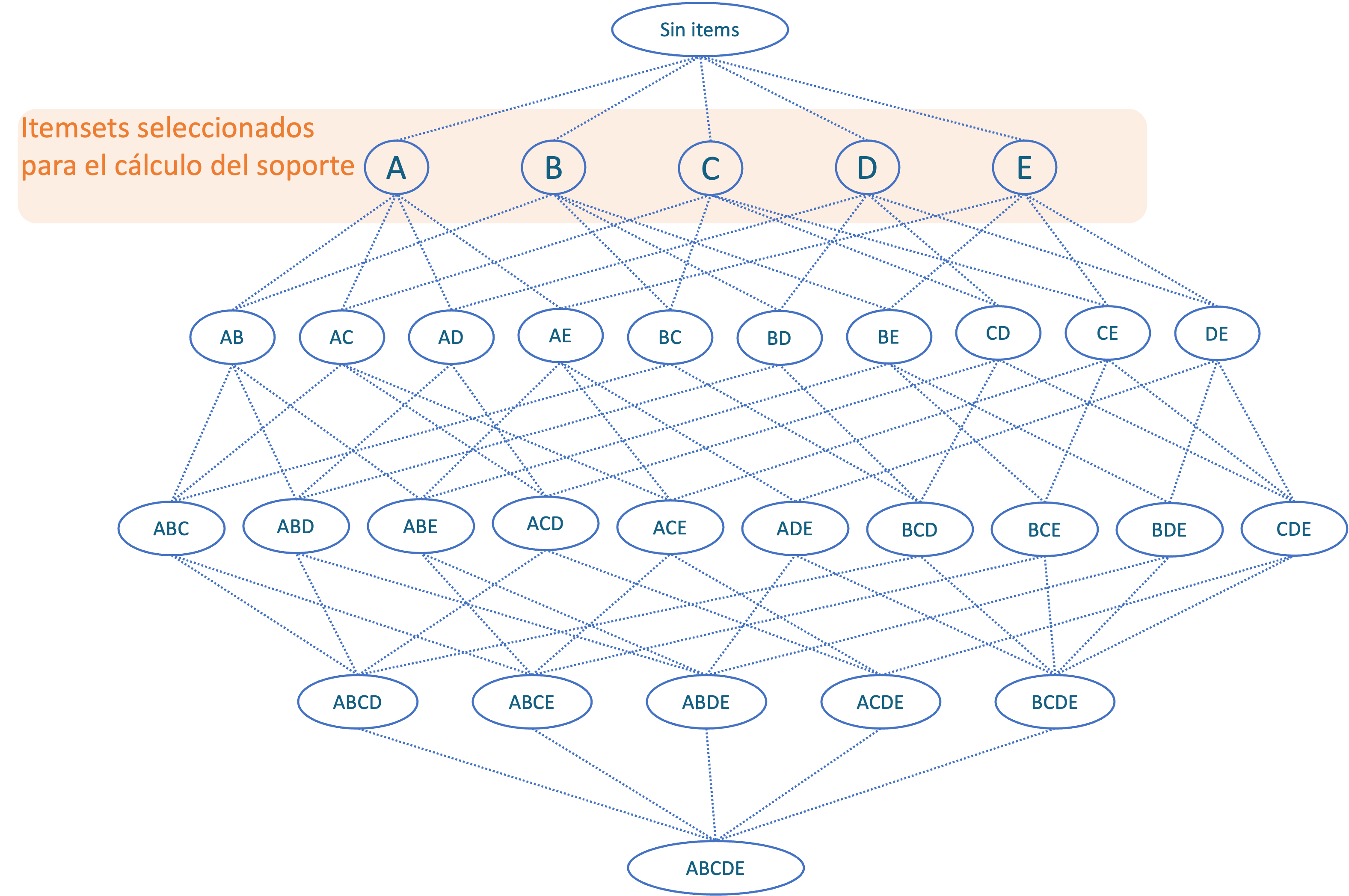
El segundo paso implica calcular el soporte para cada uno de esos conjuntos. Ahora, supongamos que todos los itemsets tienen un soporte por encima del umbral establecido. Entonces, el tercer paso implica conservar todos los itemsets.
El cuarto paso implica seleccionar los itemsets que contengan un elemento más, como se muestra en la Figura 2.5. Y ahora repetiremos el paso 2 en la segunda iteración. Es decir, calcularemos el soporte de los nuevos itemsets.Figura 2.5: Paso 4 del algoritmo A-Piori en la primera iteración.
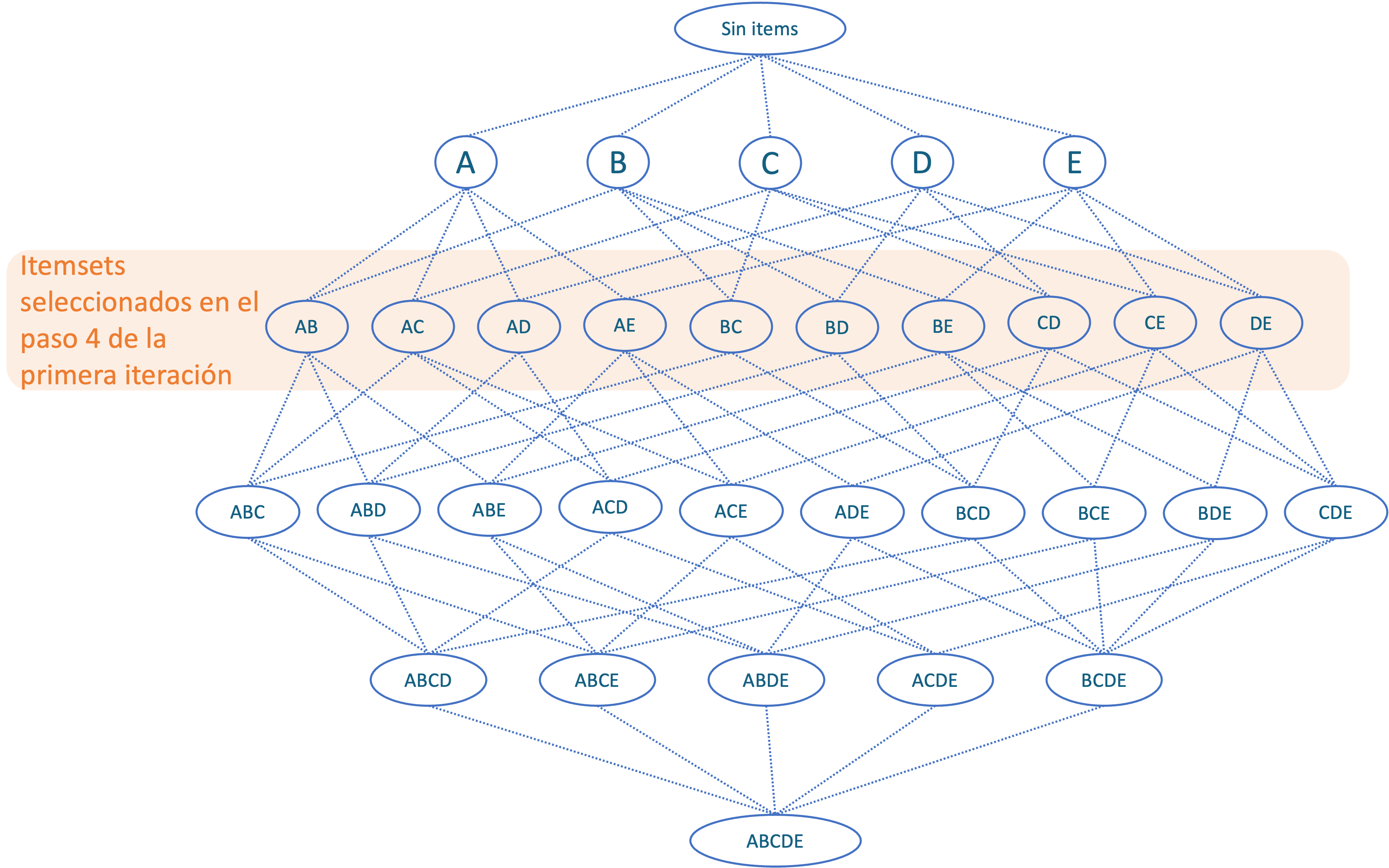
Ahora, supongamos que el itemset \(\left\{A,B\right\}\) tiene un soporte por debajo del umbral. Esto significa descartar todos los itemsets que contengan \(\left\{A,B\right\}\). Tal como se presenta en la Figura 2.6.
Figura 2.6: Paso 3 del algoritmo A-Piori en la segunda iteración.
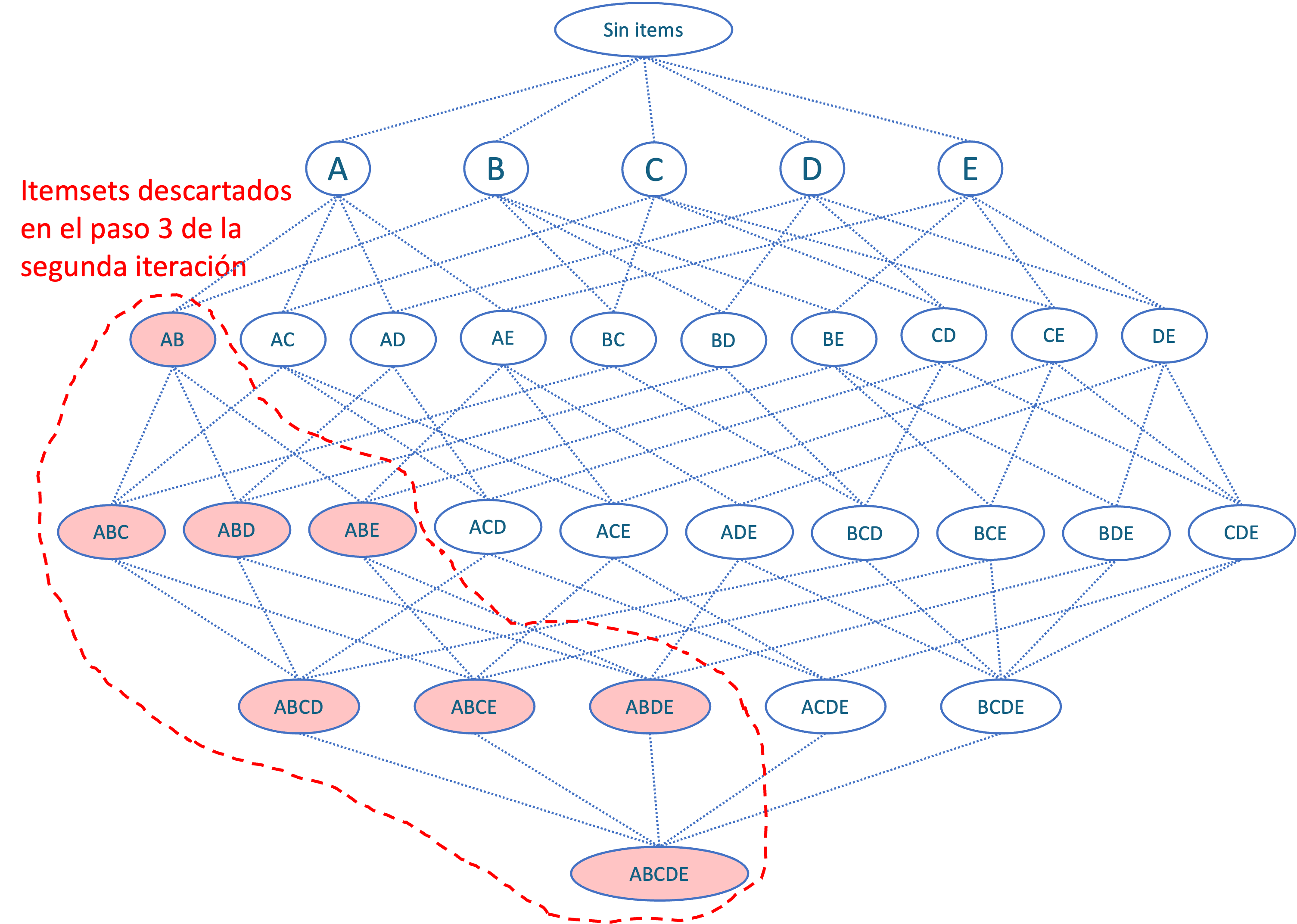
Ahora, el paso 4 en la segunda iteración implica seleccionar los itemsets con un artículo más, tal como se muestra en la Figura 2.7.
Figura 2.7: Paso 4 del algoritmo A-Piori en la segunda iteración.
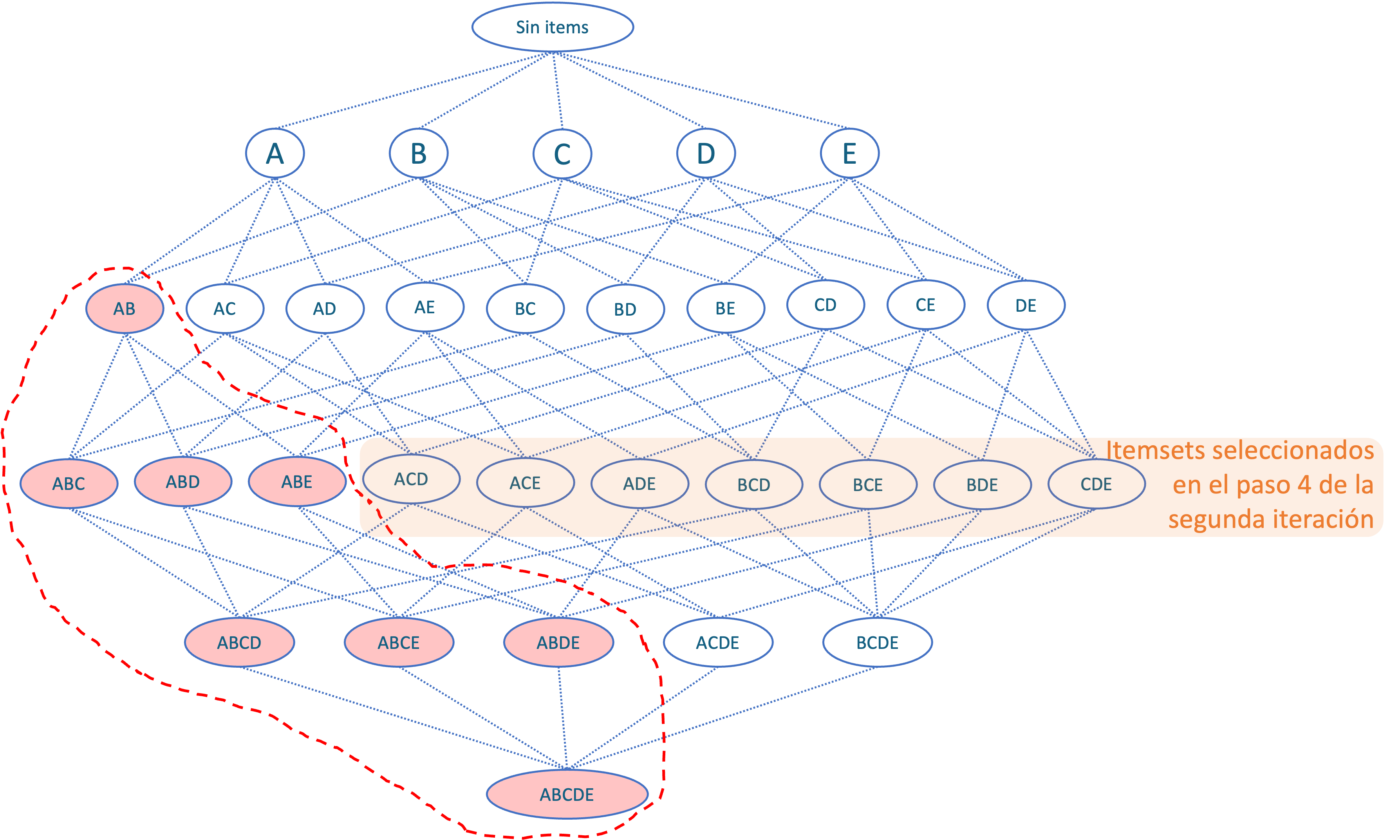
Posteriormente, se repetiría el paso 2 al 4 hasta que se agoten los itemsets. Al final, con los itemsets que superan el umbral de soporte, se calcula la confianza, lift y cobertura para todas las reglas que se puedan establecer con los itemsets que quedan. Finalmente, el MBA continuará examinando las reglas disponibles para tomar decisiones de negocio.
Con este ejemplo, te puedes dar cuenta de cómo este algoritmo empieza rápidamente a reducir el número de itemsets y reglas que se analizarán, dejando solamente aquellas que cumplen el soporte (la popularidad) establecida como umbral. Nuestro ejemplo, por razones pedagógicas, emplea un número muy pequeño de ítems. Puedes imaginarte cómo este algoritmo facilita la vida cuando se cuenta con cientos o miles de productos, como ocurre en los almacenes de cadena.
Uno de los problemas del algoritmo Apriori es el costo computacional de la generación de conjuntos de elementos frecuentes. En ese proceso se necesita escanear la base de datos muchas veces, lo que conlleva un aumento del tiempo y reduce el rendimiento, en especial si la base de datos es relativamente grande.
Una de las decisiones más importantes para implementar este algoritmo es la definición del umbral para el soporte. Entre más bajo sea el umbral, menos itemsets serán descartados, pero entre más alto sea, podríamos estar descartando reglas relativamente razonables. Esa elección del umbral normalmente se basa en experiencia previa o ensayo y error. En general, es común empezar el análisis empleando un umbral del 10% como valor inicial.
El algoritmo Apriori también puede ser empleado fijando como métrica para el umbral la confianza, el lift o una combinación de estos. De esta manera, al usar el algoritmo Apriori sobre un conjunto de transacciones, nuestro objetivo es identificar todas las reglas de asociación que tengan un valor igual o mayor al umbral de soporte, de confianza o lift.
Para nuestro ejemplo, si empleamos un umbral del 30% para el soporte y uno de 50% para la confianza, el algoritmo Apriori encuentra las cinco reglas que se presentan en el Cuadro 2.3. Las columnas “LHS” y “RHS” corresponden al antecedente y consecuente de cada una de las reglas, respectivamente, y las filas corresponden a cada una de las reglas identificadas por el algoritmo Apriori con los umbrales de soporte y confianza establecidos.
| LHS | RHS | Soporte | Confianza | Cobertura | Lift | |
|---|---|---|---|---|---|---|
| {cerveza} | => | {pañales} | 0.6 | 1.00 | 0.6 | 1.67 |
| {pañales} | => | {cerveza} | 0.6 | 1.00 | 0.6 | 1.67 |
| {leche} | => | {pan} | 0.4 | 1.00 | 0.4 | 1.25 |
| {pan} | => | {leche} | 0.4 | 0.50 | 0.8 | 1.25 |
| {cerveza} | => | {pan} | 0.4 | 0.67 | 0.6 | 0.83 |
| {pan} | => | {cerveza} | 0.4 | 0.50 | 0.8 | 0.83 |
| {pañales} | => | {pan} | 0.4 | 0.67 | 0.6 | 0.83 |
| {pan} | => | {pañales} | 0.4 | 0.50 | 0.8 | 0.83 |
| {cerveza, pañales} | => | {pan} | 0.4 | 0.67 | 0.6 | 0.83 |
| {cerveza, pan} | => | {pañales} | 0.4 | 1.00 | 0.4 | 1.67 |
| {pan, pañales} | => | {cerveza} | 0.4 | 1.00 | 0.4 | 1.67 |
| Fuente: elaboración propia. |
El algoritmo Apriori encuentra la regla “cuando en la canasta está la cerveza, se compra pañales”, que tiene una popularidad del 60% (soporte) y una confianza del 100% (ver primera fila del Cuadro 2.3). Es decir, el itemset cerveza y pañales (\(\left\{ cerveza, pañales \right\}\)) fue observado en el 60% de las transacciones, y en todos los casos en los que la cerveza ya estaba en el “carrito”, se incluyeron pañales en la transacción. Así mismo, el lift para esa regla es mayor que 1, lo cual implica que es muy probable que se compren pañales cuando en el “carrito” de compra tenemos cerveza. Nota que para nuestro ejemplo (no siempre será así) se obtienen los mismos resultados para la regla \(pañales \rightarrow cerveza\). En este caso se detectaron once reglas.
2.5 Reglas que no agregan valor
No toda regla que encontramos con el algoritmo Apriori es útil o relevante para el negocio. Una buena regla no solo debe tener un equilibrio entre frecuencia (soporte), confianza, cubrimiento y lift, sino también que sean relativamente sencillas de accionar. Cuando se generan reglas de asociación, es común encontrar reglas que, aunque técnicamente distintas, expresan la misma relación de manera más compleja o menos eficiente. Estas son conocidas como reglas redundantes.
Una regla se considera redundante cuando su información ya está contenida en otra regla más simple o más general. A menudo, las reglas redundantes son más largas, incluyen más productos, pero no ofrecen una ganancia real en términos de soporte o confianza.
Para entender mejor este concepto, consideremos las siguientes reglas:
\(\left\{ cerveza \right\} \rightarrow \left\{ pan \right\}\) (quinta fila del Cuadro 2.3) y
\(\left\{ cerveza, pañales \right\} \rightarrow \left\{ pan \right\}\) (novena fila del Cuadro 2.3).
La segunda regla incluye un producto adicional en el antecedente (pañales), pero no mejora la confianza o el lift en relación con la primera. Si los pañales no contribuyen sustancialmente a hacer más fuerte la predicción de compra del pan, la segunda regla puede considerarse redundante.
Desde un punto de vista de comunicación y acción, es preferible conservar reglas más simples y directas, ya que son más fáciles de entender, comunicar y activar comercialmente.
Nota que también son redundantes las reglas:
\(\left\{ cerveza, pan \right\} \rightarrow \left\{ pañales \right\}\) (décima fila del Cuadro 2.3) y
\(\left\{ pan, pañales \right\} \rightarrow \left\{ cerveza \right\}\) (última fila del Cuadro 2.3).
En el Cuadro 2.4 se presentan las reglas de asociación después de descartar las reglas redundantes.
| LHS | RHS | Soporte | Confianza | Cobertura | Lift | |
|---|---|---|---|---|---|---|
| {cerveza} | => | {pañales} | 0.6 | 1.00 | 0.6 | 1.67 |
| {pañales} | => | {cerveza} | 0.6 | 1.00 | 0.6 | 1.67 |
| {leche} | => | {pan} | 0.4 | 1.00 | 0.4 | 1.25 |
| {pan} | => | {leche} | 0.4 | 0.50 | 0.8 | 1.25 |
| {cerveza} | => | {pan} | 0.4 | 0.67 | 0.6 | 0.83 |
| {pan} | => | {cerveza} | 0.4 | 0.50 | 0.8 | 0.83 |
| {pañales} | => | {pan} | 0.4 | 0.67 | 0.6 | 0.83 |
| {pan} | => | {pañales} | 0.4 | 0.50 | 0.8 | 0.83 |
| Fuente: elaboración propia. |
En términos formales, una regla de asociación \({A}' \rightarrow B\) se considera redundante si existe al menos otra regla \(A \rightarrow B\) donde \(A\) es un subconjunto de \({A}'\) (\(A \subset {A}'\)) y ambas tienen los mismos valores de soporte y confianza26. En otras palabras, la información que aporta \(\left\{ {A}' \right\} \rightarrow \left\{ B \right\}\) está completamente contenida en una regla más general. La regla \(\left\{ {A}' \right\} \rightarrow \left\{ B \right\}\) no mejora la capacidad predictiva. Dicho de forma intuitiva, una regla redundante es como repetir lo mismo con palabras de más. Si ya sabemos que “comprar cerveza implica comprar pan”, añadir “y pañales” al antecedente sin aumentar la probabilidad de observar pan no agrega valor para las organizaciones. Solo agranda la lista de reglas y dificulta concentrar la atención en aquellas que permiten tomar decisiones. Es apenas natural que todas las reglas que no sean considerada redundantes, serán denominadas reglas no redundantes27.
La identificación y eliminación de normas redundantes es una labor técnica responsabilidad del científico de datos. Sin embargo, el analytics translator también tiene un papel importante en este proceso de eliminación de reglas redundantes; este papel debe cooperar en la interpretación de las reglas filtradas, garantizando que el conjunto final de reglas mantenga su importancia para el negocio y no se pierdan descubrimientos potencialmente valiosos debido a una eliminación automática excesivamente rigurosa.
2.6 Respondiendo las preguntas de negocio
Regresemos a las preguntas de negocio originales para darles respuesta con los insights del MBA. La primera pregunta de negocio era: ¿se puede retirar del portafolio la leche sin afectar las compras de otros productos? Esta pregunta surgió porque el gerente de la tienda estaba pensando en no ofrecer la leche para disminuir costos de almacenamiento y exhibición.
De las reglas identificadas, podemos centrar nuestra atención en aquellas cuyo antecedente (LHS) contenga la leche. En este caso tenemos la regla \(\left\{ leche \right\} \rightarrow \left\{ pan \right\}\) (Ver la tercera fila del Cuadro 2.3), que tiene una alta probabilidad de que la leche impulse el pan (lift superior a uno) y, siempre que se incluye leche en la transacción, se incluye pan (confianza del 100%). Así, dejar de vender leche implicará que se dejará de vender pan; este es un riesgo que debería medir el gerente antes de sacar de su portafolio la leche. Se requerirá de un análisis más minucioso que cuantifique los ahorros en costos de sacar la leche y las pérdidas en ingreso por dejar de vender pan y leche.
La segunda pregunta era: ¿qué producto debería acompañar al pan en un “combo” promocional? Esta pregunta estaba motivada por la necesidad de vender pan antes de su pronta fecha de expiración. Para responder esta pregunta, centremos la atención en reglas que en el consecuente (RHS) tengan pan:
- \(\left\{ leche \right\} \rightarrow \left\{ pan \right\}\) (tercera fila del Cuadro 2.4),
- \(\left\{ cerveza \right\} \rightarrow \left\{ pan \right\}\) (quinta fila del Cuadro 2.4) y
- \(\left\{ pañales \right\} \rightarrow \left\{ pan \right\}\) (séptima fila del Cuadro 2.4).
Las dos últimas reglas tienen un lift inferior a uno, lo cual implica que es poco probable que se compre el pan. Así, podemos descartar esas dos reglas. La regla \(\left\{ leche \right\} \rightarrow \left\{ pan \right\}\) tiene un lift mayor a uno (1.25) y una confianza del 100%. Así, tiene sentido hacer un combo para evacuar rápidamente el pan que incluya leche y pan.
De las reglas encontradas también podemos generar insights valiosos para tomar otras decisiones del negocio (¿se te ocurre alguna?). Los resultados del MBA combinados con ingenio pueden traer muchos beneficios a los establecimientos minoristas.
2.7 Implicaciones prácticas
El resultado de este análisis muestra que es esencial la interacción entre el analytics translator y el científico de datos. El tabajo conjunto de estas partes es evidente al a) determinar cuál es la condición, en este caso el producto, de la mano derecha (RHS) y de la mano izquierda (LHS); b) analizar los resultados de soporte, confianza y lift para la toma de decisiones. Las decisiones con base en estos resultados tendrán consecuencias sobre la rentabilidad del negocio.
La respuesta a las preguntas de si es posible retirar la leche del portafolio y qué producto sería un buen combo para el pan, responden a la idea de entender hábitos del consumidor y cómo estos se traducen en su comportamiento de compra. Al entender estos patrones de comportamiento es posible hacer una oferta de productos pertinente para el consumidor y generar mayor rentabilidad para el fabricante del producto y el canal minorista. La leche no es un producto estrella porque solo es el antecedente en uno de los tipos de canasta, pero tiene una coincidencia fuerte con la compra de pan, el cuál sí es un producto determinante en la compra de todos los productos en el punto de venta. Es decir, en este ejemplo el pan es un producto ancla y la leche es un producto de nicho.
El producto ancla 28 es un elemento esencial en la tienda porque es el que genera recordación y es atractivo para una gran masa de consumidores (Choi, 2018) (producto ancla). Mientras tanto el producto de nicho solo es atractivo para un exclusivo grupo de consumidores. Es decir, es un grupo pequeño pero con hábitos o características individuales que facilitan que ocurra la compra del producto A junto al producto B. Dado el tamaño pequeño y las características específicas de un segmento nicho, la tienda pueda aprovechar esta oportunidad para hacer actividades promocionales más efectivas al estar dirigidas específicamente a este grupo (ver Capítulo 1 marketing de nicho). En cuanto al producto ancla, algunas tiendas minoristas deciden ofrecer el producto ancla bajo su propia marca que el consumidor asocia a un precio bajo, aumentando la demanda por el producto (Al-Monawer et al., 2021)29 (marca propia).
Las preguntas de este ejemplo con relación al pan y la leche esperan ser simples para mostrar cómo es posible utilizar el MBA en la toma de decisiones importantes para las marcas y los canales minoristas. No obstante, las aplicaciones del MBA no se restringen a este ejemplo o al contexto del mercadeo. El MBA se puede utilizar en diferentes áreas. En general, el MBA puede identificar patrones de comportamiento en grandes conjuntos de datos en los que importa la presencia o no de una característica, comportamiento o ítem, lo cual tiene aplicación en diferentes áreas.
Por ejemplo, en el campo de la salud, puede emplearse para detectar qué morbilidades están asociadas con otras (se presentan al mismo tiempo). Esto puede ayudar a los médicos a identificar pacientes que podrían estar en mayor riesgo de desarrollar ciertas enfermedades y tomar medidas preventivas.
En el campo de la seguridad, el MBA se utiliza para detectar patrones de comportamiento sospechosos en transacciones financieras. En este contexto, una transacción puede ser las actividades que se realizan en un día; por ejemplo: retiro en oficina, retiro en cajero, consignación y traslados. El MBA puede encontrar los itemsets y reglas comunes de tal manera que, si se observa un itemset atípico o una regla con poca confianza, puede marcarse como un comportamiento sospechoso.
En el ámbito de la logística y el transporte, el MBA se utiliza para optimizar las rutas de entrega y reducir los costos de transporte. Por ejemplo, si se detecta que ciertos productos tienden a ser comprados juntos con frecuencia, se pueden agrupar en la misma ubicación de almacenamiento para facilitar la preparación de pedidos.
2.8 Comentarios finales
En este capítulo discutimos los datos transaccionales que son empleados en el MBA y las métricas más comunes para caracterizar itemsets (soporte) y reglas de asociación (confianza, lift y cobertura). Así mismo, estudiamos el algoritmo Apriori, que permite concentrar la atención sobre reglas “interesantes”.
Al conocer la lógica del MBA, es claro que un uso efectivo requiere del trabajo conjunto de los roles del científico de datos y del analytics translator. El primero transforma los datos transaccionales y crea reglas de asociación empleando algoritmos; esto con un criterio coherente con las preguntas estratégicas del negocio. El segundo indica los lineamientos estratégicos desde el mercadeo y entiende los resultados para motivar decisiones prácticas que usen esas reglas de asociación.
Con un juego de datos transaccionales sencillo y empleando las herramientas del MBA, mostramos cómo encontrar reglas que podían responder las preguntas de negocio planteadas y permitir hacer analítica prescriptiva. Es decir, sugerir cuál es la mejor acción a tomar. En el área del retail (venta minorista), los resultados del MBA combinados con creatividad pueden traer muchos beneficios. Finalmente discutimos algunas implicaciones prácticas del ejercicio, destacando el potencial que tiene el MBA como herramienta de análisis en otros contextos.
Las aplicaciones del MBA son muchas, ¡la imaginación es el límite!
Referencias
Imagínate el recibo que te dan en un supermercado con el listado de los productos que compraste. Tirilla que incluye precio y número de unidades de cada producto.↩︎
En algunas oportunidades escucharás el término SKU en vez de ítem. El SKU (la sigla de stock keeping unit) es el término técnico que se emplea en la gestión de inventarios para un tipo distinto de artículo para la venta o el inventario; en otras palabras, la referencia de un producto. Por ejemplo, el paquete de papas fritas de una marca en particular de 50 gramos tendrá un SKU y el paquete de 100 gramos del mismo tipo de papas fritas de la misma marca tendrá otro SKU y será tratado como si fuera otro ítem. En este libro no entraremos en ese detalle, pero nota que todo lo que estudiaremos aquí dependerá de qué definas como un ítem y esto dependerá de la pregunta de negocio. Es decir, si definimos como ítem las papas fritas o a un nivel más específico de papas fritas, los diferentes SKU para las papas fritas dependerán del problema bajo estudio.↩︎
Nota que un itemset puede estar constituido por un solo ítem o por muchos de ellos.↩︎
Si se tienen \(n\) items, entonces el total de itemsets que se pueden conformar es \(2^n\) y el total de reglas de asociación son \(3^n - 2^{r+1} + 1\). En el caso de nuestro ejemplo, \(n = 4\). Así, el número de itemsets es de 16 y el número posible de reglas de asociación es de 50. ↩︎
Típicamente es una decisión que toma el analytics translator.↩︎
Recuerda que un algoritmo es un conjunto ordenado de operaciones sistemáticas que permite hacer un cálculo y hallar la solución de un problema determinado.↩︎
Existen otros algoritmos que se emplean para buscar reglas de asociación como AIS, SETM, FP-Growth, Eclat. Pero estos no los cubriremos en este libro. ↩︎
Nota que esta lógica también implica que, si un itemset con los elementos \(\left\{A,B\right\}\) es frecuente, entonces ambos subconjuntos \(\left\{A\right\}\) y \(\left\{B\right\}\) son frecuentes.↩︎
En la literatura se denomina súper regla a toda regla de asociación \({A}' \rightarrow {B}'\) tal que existe otra regla \(A \rightarrow B\) con \(A \subset {A}'\) y/o \(B \subset {B}'\); es decir, la súper regla amplía el antecedente (super antecedent rule) o el consecuente (super consequent rule) de una regla más general manteniendo la misma estructura de predicción. ↩︎
Esto suena raro, pero formalmente también es necesario definir qué es una regla no redundante. Formalmente una regla no redundante se define como aquella para la cual las otras reglas se consideran súper reglas y al mismo tiempo las otras reglas tiene una confianza mas baja. En otras palabras, una regla de asociación \(A \rightarrow B\) es no redundante cuando no existe otra regla \({A}' \rightarrow B\) (o \(A \rightarrow {B}'\)) tal que \({A}' \subset A\) (o \({B}' \subset B\)) y cuya confianza y soporte sean mayores o iguales a los de la primera.↩︎
Un producto ancla es aquel que facilita la visita de consumidores al punto de venta porque es algo básico en las necesidades de los consumidores en general y significa una compra de poco riesgo o desembolso bajo. Un producto ancla puede no ser el producto más vendido, pero sí es el que desencadena la visita o la compra de muchos otros.↩︎
Una marca propia es aquella que se distribuye bajo la etiqueta del canal minorista y no de un fabricante. Al funcionar como un producto genérico, en una determinada categoría, se ofrece a un menor precio pero con el respaldo de calidad dado por el distribuidor minorista↩︎