8 Modelo GMM
Objetivos del capítulo
Al finalizar este capítulo, el lector estará en capacidad de:
- Explicar en sus propias palabras la lógica detrás de la construcción de un clúster empleando el algoritmo GMM.
- Construir en R clústeres empleando el algoritmo GMM.
8.1 Introducción
La tarea de hacer clústeres se puede responder con diferentes modelos. Ya hemos estudiado los algoritmos jerárquicos como AGNES y DIANA (Ver Capítulos 3 y 4 para una discusión de estos modelos). En el Capítulo 2 vimos que existe otra gran categoría de modelos de clústering: los algoritmos particionados. A su vez, hemos estudiado algoritmos de clústering particionados basados en centroides, como por ejemplo los modelos k-means (Ver Capítulo 5), k-means++ (Ver Capítulo 5), PAM (Ver Capítulo 6) y CLARA (Ver Capítulo 6). También hemos estudiado el algoritmo DBSCAN, que es un algoritmo particionado basado en densidad (Ver Capítulo 7).
Tanto los modelos de clústering jerárquico como los particionados estudiados hasta ahora emplean un enfoque heurístico70 para construir clústeres; es decir, no se basan en un modelo formal.
En este capítulo nos concentraremos en los modelos particionados basados en modelos (también conocidos como basados en la distribución). Los algoritmos de clústering basados en modelos asumen un modelo generador de datos que implica estimar unos parámetros, entre los cuales se encuentra el número de grupos.
Estos modelos parten de los datos y tienen como objetivo encontrar la mezcla de distribuciones normales que pudieron generar los datos (ver Figura 8.1). La tarea de este algoritmo es encontrar el número de clústeres y la media, varianza y covarianzas de cada distribución multivariada normal (gaussiana) que pudo generar los datos. Por ejemplo, en la Figura 8.1 cada uno de los conglomerados representados corresponden a una distribución normal bivariada (con una media para cada variable, una varianza para cada variable y las respectivas covarianzas); esto es lo que se representa con las elipses y círculos concéntricos. A medida que nos acercamos al centro es mucho más probable (colores más fuertes) que los individuos pertenezcan al clúster y a medida que se alejan del centro (la media) la probabilidad disminuye (color más tenue).
Figura 8.1: Representación de un algoritmo de clústering particionado basado en distribuciones

En la siguiente sección estudiaremos el modelo que se encuentra por detrás de este algoritmo y, posteriormente, estudiaremos cómo implementar este método en R.
8.2 Formalmente
Los modelos de mezclas gaussianas (GMM, por sus siglas en inglés) son una técnica de clústering que se basa en la idea de que los datos observados debieron ser fruto de una muestra aleatoria que proviene de una población, cuya función de probabilidad es una mezcla de varias distribuciones gaussianas. En otras palabras, supone que el proceso generador de los datos es una mezcla de distribuciones normales, donde cada una de estas distribuciones representa un clúster.
Formalmente, reconozcamos que los valores observados para cada unas de las \(d\) variables (feature) cuantitativas, observadas para cada uno de los \(n\) individuos (\(x= [ x_1 \quad x_2 \quad \cdots \quad x_d ]\)) son realizaciones de \(d\) variables aleatorias \(\mathbf{x} = [ \mathbf{x}_1 \quad \mathbf{x}_2 \quad \cdots \quad \mathbf{x}_d ]\) (por ahora, omitiremos el subíndice \(i\) para evitar confusiones). El modelo GMM supone que este vector de features provienen de una mezcla de distribuciones normales. Es decir, para cada individuo \(i\) tendremos:
\[\begin{equation} p(\mathbf{x}_i) = \sum_{k=1}^{q} \pi_k \mathcal{N}(\mathbf{x}_i | \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k ) \tag{8.1} \end{equation}\]
donde \(q\) es le número (óptimo en este caso) de conglomerados o componentes gaussianos, \(\pi_k\) es el peso del clúster \(k\). Además, estos pesos deben garantizar que \(\sum_{k=1}^{K} \pi_k=1\) . \(\mu_k\) es el vector de medias para el conglomerado \(k\), \(\Sigma_k\) es la matriz de varianzas y covarianza del clúster \(k\) y \(\mathcal{N}(\mathbf{x} | \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k )\) es la función de densidad de probabilidad gaussiana (normal) multivariada para el conglomerado \(k\).
El objetivo del GMM es encontrar los parámetros \(\theta_k = \{\boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k, \pi_k \}\) para \(k = 1, 2,...q\) y \(q\) que maximice la probabilidad de que los datos provengan de dicha mezcla de distribuciones normales. En otras palabras, este es un problema de estimación por el método de máxima verosimilitud en el que queremos resolver el siguiente problema:
\[\begin{equation} L(\mathbf{\theta} , q)= p(\mathbf{x}_1) \cdot p(\mathbf{x}_2)\cdots p(\mathbf{x}_n)=\prod\limits_{i=1}^n p(\mathbf{x}_i) \tag{8.2} \end{equation}\]
donde \(p(\mathbf{x}_i)\) está definida por (8.1) y \(\mathbf{\theta} = \{\theta_1, \theta_2, \dots \theta_q \}\). De esta manera el problema será
\[\begin{equation} \left ( \hat{\mathbf{\theta}} , \hat{q} \right )= arg \max_{\theta,q } L(\theta , q) \tag{8.3} \end{equation}\] sujeto a las siguientes restricciones:
- \(\sum_{k=1}^{K} \pi_k =1\)
- \(q >0\)
En otras palabras, el objetivo del GMM es encontrar los parámetros \(\mathbf{\theta}\) y \(q\) que maximizan la verosimilitud de los datos observados. Este problema se puede resolver empleando el algoritmo EM (Expectation-Maximization)71. En el paso de Expectation se calculan las probabilidades de pertenencia de cada individuo a cada grupo. Estas probabilidades se conocen como responsabilidades. Y en el paso Maximization se actualizan los parámetros del modelo, utilizando las responsabilidades calculadas en el paso Expectation. Estos pasos se repiten hasta que la verosimilitud converja; es decir, no cambie mucho de una iteración a otra. Al final, cada individuo se asigna al clúster con la mayor responsabilidad.
Los GMM tienen la ventaja de poder modelar conglomerados con diferentes formas y tamaños, así como proporcionar una asignación de clúster suave (Soft Clustering)72. Sin embargo, son sensibles a la inicialización y pueden ser computacionalmente costosos en conjuntos de datos grandes debido al ajuste de múltiples distribuciones gaussianas.
Es importante anotar que está bien documentado que el algoritmo k-means puede expresarse como un caso especial del modelo GMM. Al igual que con k-means, la estimación de un GMM por medio del algoritmo EM puede ser sensible a las condiciones iniciales.
8.3 Implementación del modelo GMM
El algoritmo GMM se puede implementar con la función Mclust() del paquete mclust (Scrucca et al., 2023). Antes de emplear la función, es importante reconocer que, en este caso, el número de clústeres óptimo (\(q\)) es seleccionado en el mismo proceso de maximización. En este orden de ideas, no tiene mucho sentido emplear la silueta promedio para escoger el número óptimo de grupos, procedimiento que sí tenía sentido para todos los modelos de clústering estudiados hasta el momento (excepto DBSCAN). Por otro lado, la silueta promedio sí es posible calcularla y puede emplearse para comparar esta aproximación con otros (realizar la validación del clúster).
En todo caso, será importante recordar que la silueta promedio casi siempre favorecerá modelos como los jerárquicos ( como k-means, PAM y CLARA), que a modelos como el DBSCAN o el GMM. Esto se debe a que la aproximación de DBSCAN y GMM permiten crear conglomerados “largos y delgados” y hasta “envolver otros conglomerados”; es decir, por construcción no intentan optimizar las distancias intra e inter conglomerados, que es lo que mide la silueta. Y, por ejemplo, k-means sí intenta más o menos optimizar estas dos cantidades.
Regresando a la función Mclust(), esta solo necesita como argumento los datos estandarizados. Por ejemplo:
Los resultados de la estimación del GMM por medio del algoritmo EM están en el objeto res_GGM. El número óptimo de clústeres lo podemos encontrar en el compartimiento G.
## [1] 6Así, según este algoritmo, el número óptimo de clústeres es 6. Así mismo, podemos visualizar los clústeres encontrados con el siguiente código (Ver Figura 8.2).
Figura 8.2: Clústeres encontrados con el algoritmo GMM
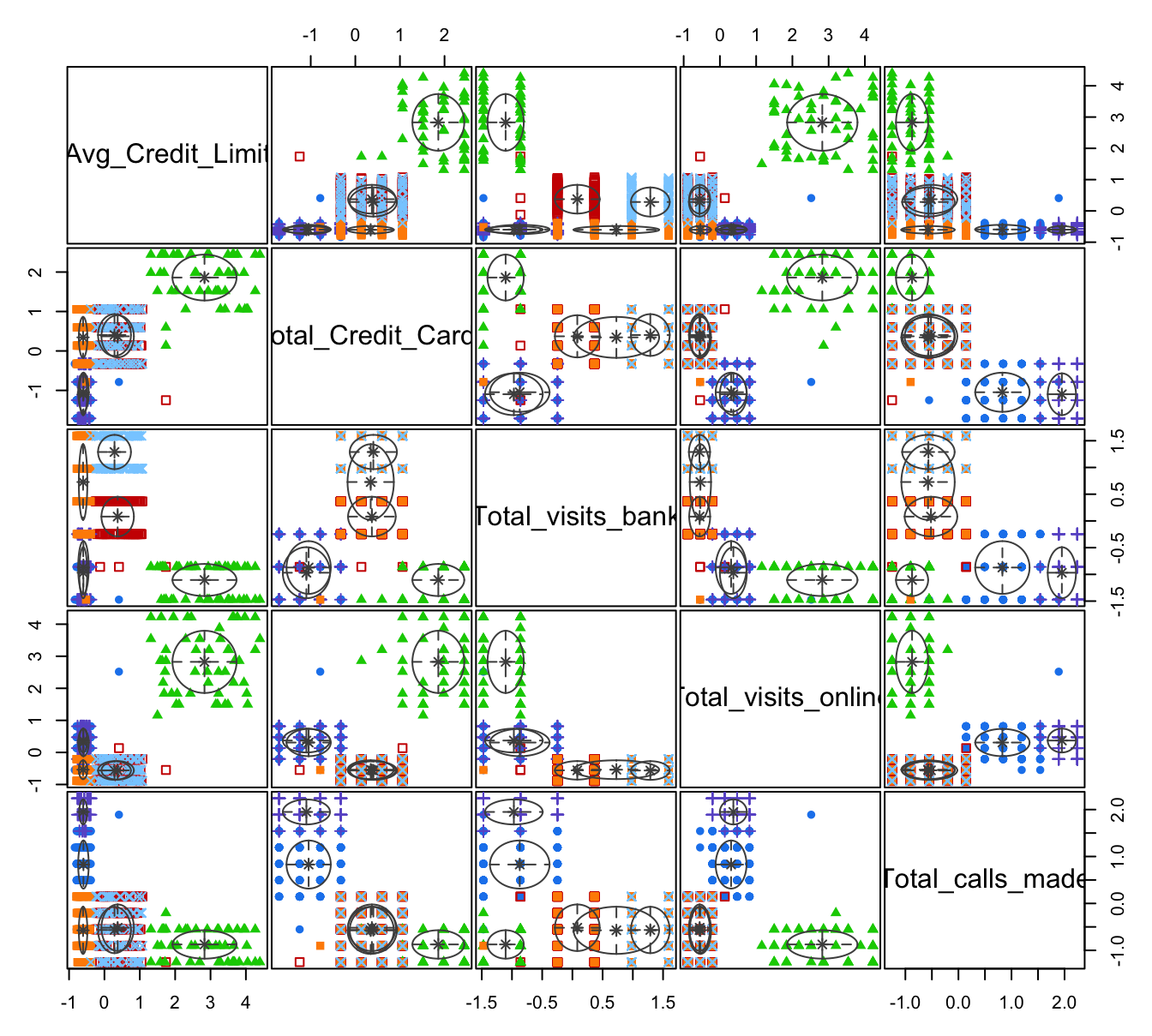
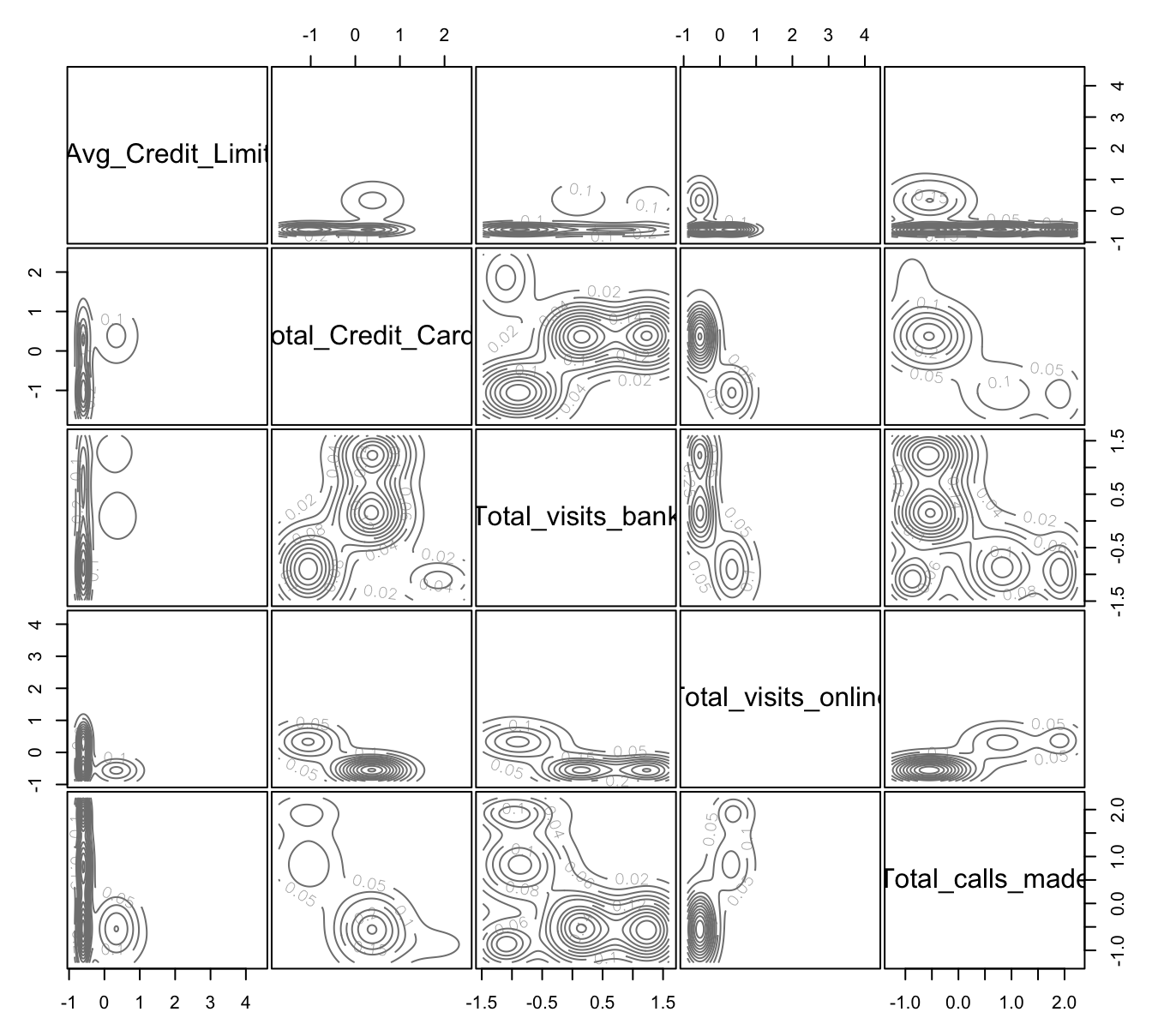
Figura 8.3: Distribuciones de probabilidad por clúster encontradas con el algoritmo GMM
Y las membrecías de cada individuo se pueden encontrar en el compartimiento classification del objeto res_GGM.
Y la siluetas se pueden calcular, para efectos de comparación con otras aproximaciones, con la función silhouette() del paquete cluster (Maechler et al., 2022).
# Calcular las siluetas individuales
sil_GMM <- silhouette(res_GGM$classification, dist(datos_est))
# Calcular la silueta promedio
mean(sil_GMM[,3])## [1] 0.2173319Noten que la silueta promedio es relativamente baja (0.2173), como se esperaba (Ver Cuadro 8.1).
| Método de aglomeración | Silueta promedio | Número óptimo de clústeres |
|---|---|---|
| Enlace único | 0.3758 | 3 |
| Enlace completo | 0.5703 | 2 |
| Enlace promedio | 0.5703 | 2 |
| Enlace mediano | 0.3022 | 6 |
| Centroide | 0.5703 | 2 |
| Ward.D | 0.5157 | 3 |
| Ward.D2 | 0.5148 | 3 |
| McQuitty | 0.5703 | 2 |
| k-means | 0.5157 | 3 |
| PAM | 0.5158 | 3 |
| CLARA | 0.5139 | 3 |
| DBSCAN | -0.0906 | 16 |
| GMM | 0.2173 | 6 |
| Fuente: cálculos propios. |
Ya hemos discutido cómo la silueta promedio no favorece los algoritmos que crean conglomerados “largos y delgados”, y “envuelven otros conglomerados”; como por ejemplo, el algoritmo DBSCAN y el GMM. Estos resultados confirman que la silueta promedio no es una métrica adecuada para evaluar la calidad de los clústeres creados por estos algoritmos.
Existen otras métricas que son más adecuadas para evaluar la calidad de los grupos creados por DBSCAN y GMM, como por ejemplo, el índice de Dunn (Ver Sección 2.6.27), el índice de Calinski-Harabasz y el índice de Davies-Bouldin. Es importante elegir la métrica adecuada para evaluar la calidad de los conglomerados en función de la aplicación específica. Por ejemplo, si es importante que los clústeres sean compactos y estén bien separados, entonces el índice de Dunn sería una buena opción.
8.4 Otro ejemplo
Siguiendo la misma lógica del Capítulo 7, para mostrar las bondades de este algoritmo continuemos el ejemplo con datos del paquete factoextra (Kassambara & Mundt, 2020).
Empecemos por estimar el GMM empleando el objeto donde tenemos los datos (multishapes) (Ver Sección 7.4):
## [1] 9En este caso encontramos 9 clústeres. En la Figura 8.4 se muestra cómo el algoritmo GMM particiona los datos.
Figura 8.4: Partición de los datos del ejemplo 2 empleando GMM
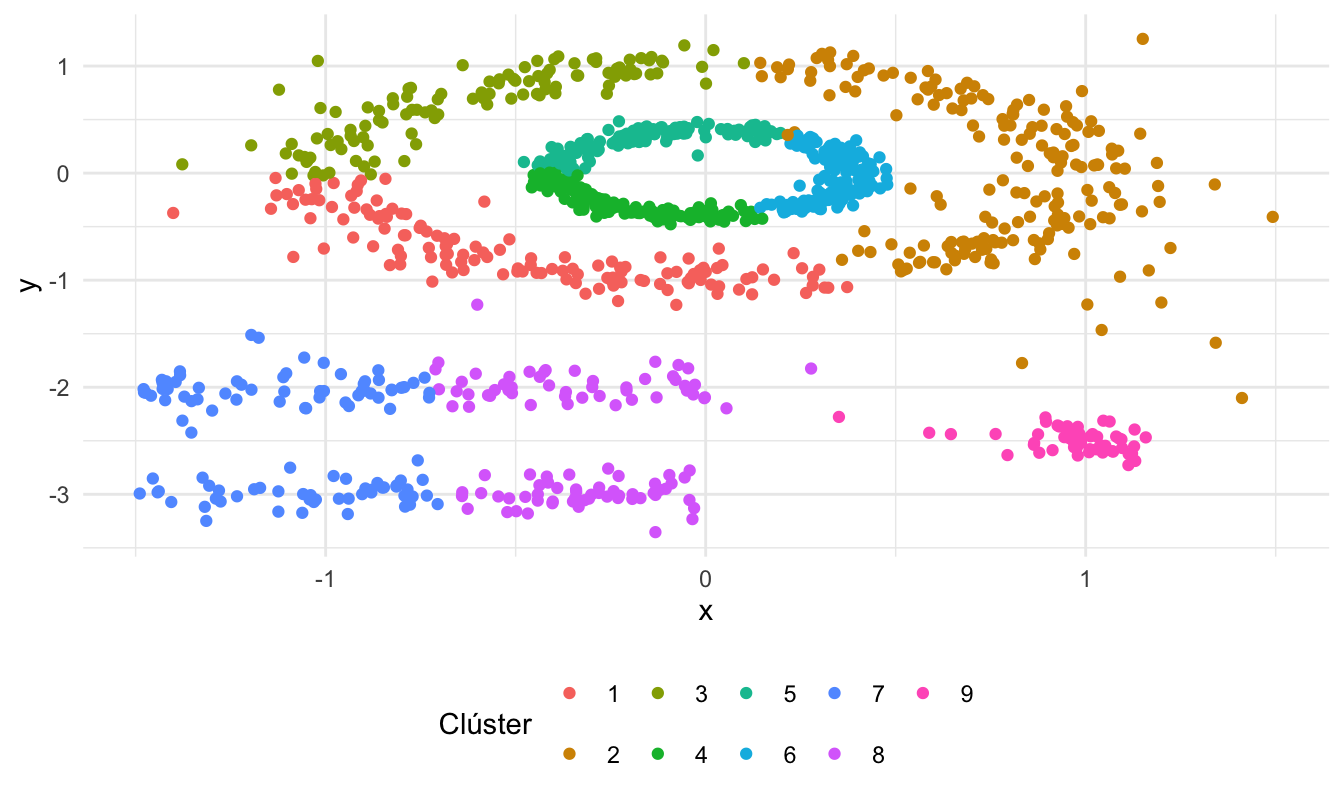
Nota que los datos parecen estar mejor particionados con el algoritmo GMM que con el algoritmo k-means (Ver Sección 7.4). Es discutible si el GMM produce una mejor partición que el modelo DBSCAN.
Recordemos que, al emplear la silueta para realizar la comparación de los algoritmos, encontraremos algo que no cuadra con lo que estamos observando. En este caso, la silueta promedio para la partición, empleando k-means, es de 0.418. Para el caso del agrupamiento generado por DBSCAN, la silueta promedio es de 0.307 y para la agrupación que genera GMM es de 0.307 (no se presenta el código intencionalmente, realiza este cálculo). Estos resultados ratifican la importancia de escoger una métrica adecuada para el problema de armar los conglomerados que enfrentemos.
8.5 Comentarios finales
En este capítulo estudiamos un método de clústering, que a diferencia de todos los estudiados hasta ahora, implica estimar el proceso generador de los datos. El modelo GMM asume que los datos son generados a partir de una mezcla de distribuciones normales multinomiales, para las cuales debemos estimar sus correspondientes medias, varianzas, covarianzas y el número de clústeres.
Como lo hemos venido mencionando, el GMM es otra de las herramientas que deberíamos tener en nuestra caja de herramientas para enfrentar las tareas de hacer clústeres. Y como toda herramienta, es importante reconocer en qué situación funcionará bien y en cuál no.
El GMM es especialmente útil cuando los datos en cada clúster se distribuyen aproximadamente de manera normal. Funciona bien en datos con clústeres de forma elipsoidales o con forma de “gota”, pero puede tener dificultades con clústeres de formas irregulares. Además, el GMM asume que los datos están distribuidos de manera similar en todas las dimensiones, por lo que puede no ser adecuado para datos con varianzas muy diferentes en cada dimensión.
Los GMM, a diferencia de todos los modelos estudiados hasta ahora, generan asignaciones de clúster suave (Soft Clustering) para los individuos. Este algoritmo permite asignar probabilidades a que los individuos pertenezcan a cada uno de los conglomerados, en lugar de asignarlos de manera estricta a un clúster. Sin embargo, son sensibles a la inicialización y pueden ser computacionalmente costosos en conjuntos de datos grandes, debido al ajuste de múltiples distribuciones gaussianas.
En el siguiente capítulo estudiaremos otra herramienta para realizar la tarea de armar clústeres que sigue una filosofía totalmente diferente.
Referencias
En la ciencia de datos, el término heurístico se emplea en el mismo sentido de la ingeniería. Es decir, una heurística es una aproximación que emplea la experiencia como ayuda para resolver un problema.↩︎
Para una discusión del algoritmo EM puedes consultar Alonso (2002).↩︎
El Soft Clustering se refiere a que este algoritmo permite asignar probabilidades a que los individuos pertenezcan a cada uno de los conglomerados, en lugar de asignarlos de manera estricta a un grupo, como lo hacen los algoritmos hasta aquí estudiados.↩︎