6 Modelos PAM y CLARA
Objetivos del capítulo
Al finalizar este capítulo, el lector estará en capacidad de:
- Explicar en sus propias palabras la lógica detrás de la construcción de un clúster empleando el algoritmo PAM.
- Construir en R clústeres empleando el algoritmo PAM.
- Explicar en sus propias palabras la lógica detrás de la construcción de un clúster empleando el algoritmo CLARA.
- Construir en R clústeres empleando el algoritmo CLARA.
6.1 Introducción
Los algoritmos de clústering se pueden clasificar en dos grandes tipos: los jerárquicos y los particionados (Ver Sección 2.3). Adicionalmente, los modelos de clústering particionados se pueden dividir en cinco categorías:
- Basados en centroides
- Basados en densidad
- Basados en la distribución
- Métodos que combinan o modifican los anteriores
- Otros tipos de algoritmos de clústering
En el Capítulo 5 estudiamos un algoritmo de clústering basado en centroides. Este modelo emplea el promedio de las distancias entre las observaciones del clúster como centroide (punto de gravedad del clúster). El algoritmo inicia eligiendo, al azar, los centroides y luego se recalculan empleando la media; de ahí el nombre de k-means.
Una de las desventajas de este algoritmo, al emplear la media, es que es sensible a datos extremos. Una mejora natural a este algoritmo es calcular de una manera diferente el centroide.
El centroide en un algoritmo de clústering actúa como un centro de gravedad alrededor del cuál se agrupan los individuos de un grupo. En el algoritmo k-means se emplea la distancia promedio de los individuos del clúster como centroide. Otra aproximación, para evitar el problema que pueden generar los datos atípicos en una medida de tendencia central como la media, es emplear la mediana. A este método se le conoce como k-medians64.
El modelo de k-medians65 ha sido generalizado con otros algoritmos particionados. En este Capítulo estudiaremos dos de estos algoritmos de clústering particionado basado en centroides: el modelo PAM (por su sigla en inglés del término Partitioning Around Medoids) y CLARA (Clustering Large Applications).
6.2 El modelo PAM
El modelo PAM (Partitioning Around Medoids) emplea como centro de gravedad para agrupar a los individuos un medoide. Por medoide se entiende un individuo (observación) dentro de un clúster cuya distancia (diferencia) promedio entre él, y todos los otros del mismo grupo, es la menor posible. En otras palabras, el medoide es el individuo “más central” del clúster y por lo tanto puede considerarse como el más representativo.
La intuición para preferir PAM frente al k-means (y k-medians) es que emplear medoids en lugar de centroides hace que PAM sea más robusto que k-means, viéndose menos afectado por datos atípicos o ruido.
De esta menera, en PAM cada clúster está “representado” por una observación presente en el clúster (el medoide), mientras que en k-means cada conglomerado está representado por el promedio de las distancias de todos los individuos de todas las observaciones del clúster (el centroide).
Para entender la intuición de este algoritmo, veamos los pasos para realizar un clústering particionado usando el algoritmo PAM, para un determinado número de clústeres \(k\):
1 Elegir aleatoriamente \(k\) individuos para ser el medoide de cada clúster.
2 Calcular las distancias de cada observación a los medoides.
3 Agrupar individuos al medoide más cercano.
4 Actualizar el medoide de cada clúster66.
5 Repetir los pasos 3 y 4 hasta que no se produzca ningún cambio en la asignación de los individuos a los clústeres o se alcance un número máximo de iteraciones.
6.3 El modelo CLARA
Como vimos, el modelo PAM emplea como centro de gravedad para cada clúster una observación. Uno de los problemas de PAM es que se vuelve muy lento cuando la muestra es relativamente grande (miles de observaciones). El algoritmo CLARA (Clustering Large Applications) fue diseñado por Rdusseeun & Kaufman (1987) para reducir el tiempo de cálculo y solucionar el problema de almacenamiento en la memoria RAM que implica desarrollar PAM. Para lograr esto, CLARA tiene una aproximación diferente para escoger los medoides iniciales que implica emplear muestreo.
CLARA selecciona, al azar, una submuestra de los datos originales y aplica el algoritmo PAM en esa submuestra. Como resultado, se obtiene un conjunto de medoides basado en dicha submuestra. Este proceso se repite varias veces, con el fin de minimizar cualquier sesgo inherente al muestreo.
Nuevamente, veamos los pasos del algoritmo para entenderlo mejor. Los pasos para realizar un clústering particionado usando el algoritmo CLARA, para un determinado número de clústeres \(k\), son:
1 Seleccionar una submuestra aleatoria, típicamente el tamaño de la submuestra es de \(40 + 2 * k\) individuos.
2 Ejecutar PAM sobre la submuestra y encontrar \(k\) medoides.
3 Asignar todos los individuos (no solo los de la submuestra) al medoide más cercano.
4 Calcular la calidad del clústering empleando la suma de las distancias cuadradas entre los individuos y sus medoides (distancias intra-clúster).
5 Repetir los pasos 1 a 4 un número de veces predeterminada. Típicamente, 5.
6 Seleccionar el mejor clústering (medoides y respectiva partición de los individuos) como aquel que tenga la mejor calidad (menor suma cuadrada de las distancias intra-clúster).
Noten que este algoritmo hace que CLARA sea menos sensible que el modelo PAM a la selección inicial de los medoides. Por otro lado, PAM puede ser más “preciso” para muestras pequeñas, pero CLARA es generalmente más rápido y eficiente en muestras grandes.
Habitualmente, la elección entre PAM y CLARA dependerá del tamaño de la muestra y la disponibilidad de recursos computacionales. Si bien es común que PAM sea recomendable para muestras pequeñas y CLARA para muestras grandes, en la práctica, cuando sea posible, emplearemos ambos algoritmos y los compararemos con alguna de las métricas que estudiamos en la Sección 2.2.
6.4 Implementación de PAM y CLARA en R
PAM y CLARA se pueden implementar en R empleando el paquete cluster (Maechler et al., 2022) con las funciones pam() y clara(), respectivamente.
Por otro lado, para estos dos algoritmos no podemos realizar la búsqueda automática del mejor número de clústeres empleando la función NbClust() del paquete NbClust. (Charrad et al., 2014) Existen otros dos paquetes que pueden hacer una búsqueda del número de grupos óptimo similar a lo realizado en los capítulos anteriores: clValid (Brock et al., 2008) y parameters (Lüdecke et al., 2020).
En este Capítulo, y en lo que resta de este libro, estaremos empleando el paquete parameters. Este paquete provee funciones que permiten integrar diferentes paquetes con algoritmos de clústering (como la base de R y el paquete cluster) y paquetes con métricas (como NbClust). Este paquete tiene la función n_clusters(), que permite, rápidamente, identificar el número de clúster óptimo empleando una métrica o una batería de métricas. Esta función tiene los siguientes argumentos:
donde:
x: Objeto con datos de clase data.frame.
standardize: Si es TRUE, se estandarizarán los datos. Este es el valor por defecto.
include_factors: Si es TRUE, las variables de clase factor se convierten en objetos numéricos para ser incluidos en los datos para determinar el número de clústeres. Por defecto, es igual a FALSE; es decir, se eliminan las variables que sean de clase factor. Esto se hace porque la mayoría de los métodos que determinan el número de conglomerados solo funciona con variables cuantitativas.
package: Paquete desde el que se llamarán las métricas para determinar el número óptimo de conglomerados. En nuestro caso, emplearemos el paquete NbClust; es decir, package = NbClust . Otras opciones para este argumento son: “all”, “easystats”, “mclust” y “M3C”.
fast: Si es igual a FALSE, se calcularán los 30 índices del paquete NbClust. Es equivalente a index = “allong” en el paquete NbClust. Por defecto, fast = TRUE
nbclust_method: El método de clústering. Puede ser, por ejemplo, cluster::diana para el algoritmo DIANA del paquete cluster. Este argumento permite decir el paquete de origen y el nombre de la función que queremos emplear.
n_max: Número máximo de clústeres a evaluar.
distance_method: El tipo de distancia a calcular. Este elemento es pasado a la función dist(). Por defecto, el método es “euclidean”; los otros posibles valores son “maximum”, “manhattan”, “canberra”, “binary” y “minkowski”.
hclust_method: El método de aglomeración para el clústering jerárquico. Este argumento solo se emplea cuando nbclust_method = “hclust” (Ver Sección 3.3). Las opciones son: “ward.D” (Ward Jr, 1963) , “ward.D2” (Murtagh & Legendre, 2014), “single” (enlace único), “complete” (enlace completo), “average” (enlace medio), “mcquitty”, “median” (enlace mediano) o “centroid”. Por defecto, method = “complete”.
Este paquete parameters también tiene un función que no calcula la batería de indicadores, sino solo la silueta promedio: n_clusters_silhouette(). Los argumentos de esta función son los mismos de la función n_clusters(). La única excepción es el argumento nbclust_method de la función n_clusters(), que cambia su nombre a clustering_function en la función n_clusters_silhouette().
Tambien existen las funciones n_clusters_elbow() y n_clusters_gap() si se desea solo emplear el método del codo o el índice GAP (Ver Sección 2.4 para una discusión de estos métodos), respectivamente.
Ahora, procedamos a emplear esta “infraestructura” que nos brinda el paquete parameters para emplear PAM y CLARA en los datos que hemos venido trabajando en los capítulos anteriores. Carga el espacio de trabajo que guardaste en el Capítulo 5.
Empleemos la función n_clusters_silhouette() para determinar el número óptimo de clústeres de acuerdo con la silueta promedio, empleando el algoritmo PAM (clustering_function= cluster::pam), la distancia euclidiana (distance_method = “euclidean”) y el objeto de datos que ya estaban estandarizados (datos_est). El código será:
# Instalar el paquete si es necesario
# install.packages("parameters")
# Cargar el paquete
library(parameters)
# Crear una semilla para que los medoides
# aleatorios siempre sean los mismos
# intenten diferentes semillas
set.seed(12345)
#
res_PAM_Sil <- n_clusters_silhouette(datos_est,
standardize = FALSE,
distance_method = "euclidean",
clustering_function= cluster::pam,
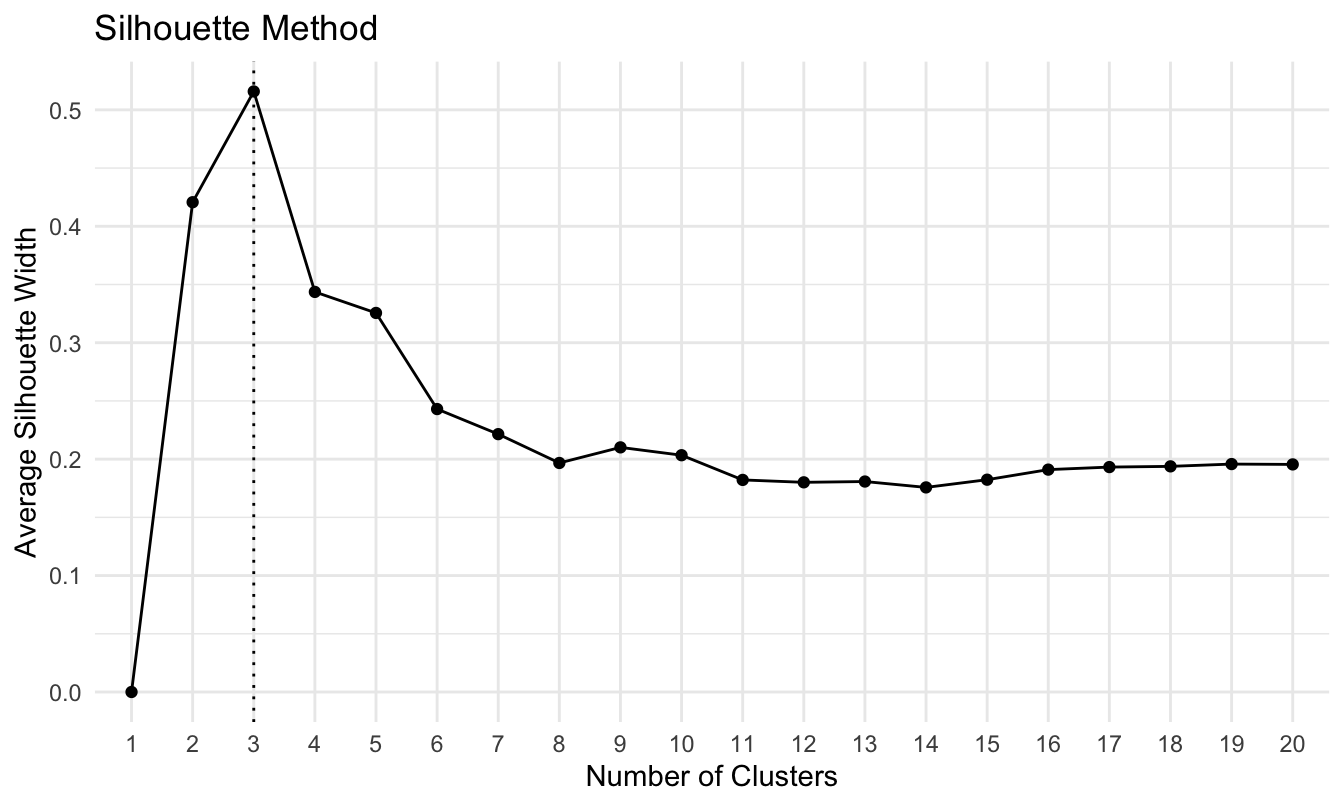
n_max = 20)Todos los resultados al emplear el algoritmo PAM para un número de clústeres de 1 a 20 (\(k=1,2..,20\)) y evaluar la silueta promedio para cada uno de esos casos, han quedado en el objeto res_PAM_Sil. Imprimamos ese objeto:
## The Silhouette method, based on the average quality of clustering, suggests that the optimal number of clusters is 3.El mensaje muestra que el número óptimo de clústeres es 3. En los compartimientos Silhouette y n_Clusters, podemos encontrar la silueta promedio y el número de clústeres, respectivamente. En este caso, podemos encontrar fácilmente que la silueta promedio (máxima) fue de 0.5158. El código es el siguiente:
## [1] 0.5157992## [1] 3
## Levels: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20También podemos graficar las siluetas para cada número de clústeres evaluados. El código que generó la Figura 6.1 es el siguiente:
Figura 6.1: Silueta promedio por número de clúster para el algoritmo PAM y distancia euclidiana
Ahora, hagamos lo mismo para el algoritmo CLARA. El código para seleccionar el número de clústeres óptimo es:
res_CLARA_Sil <- n_clusters_silhouette(datos_est,
standardize = FALSE,
distance_method = "euclidean",
clustering_function= cluster::clara,
n_max = 20)
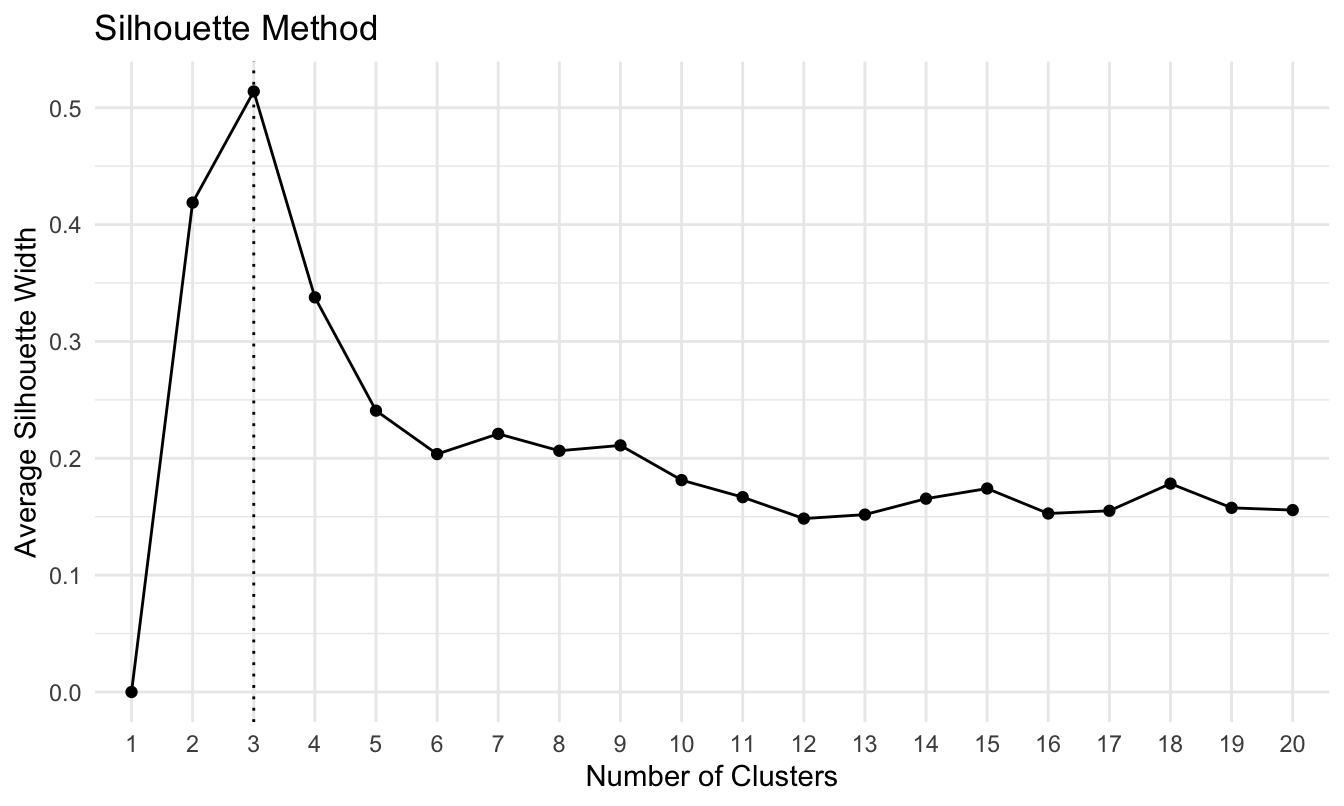
res_CLARA_Sil## The Silhouette method, based on the average quality of clustering, suggests that the optimal number of clusters is 3.En la Figura 6.2 se presentan las siluetas promedio para cada número de clústeres. En este caso, el número de clústeres óptimo es 3, que corresponde a una silueta promedio de 0.5139.
Figura 6.2: Silueta promedio por número de clúster para el algoritmo CLARA y distancia euclidiana
Los resultados hasta aquí los podemos resumir en el Cuadro 6.1.
| Método de aglomeración | Silueta promedio | Número óptimo de clústeres |
|---|---|---|
| Enlace único | 0.3758 | 3 |
| Enlace completo | 0.5703 | 2 |
| Enlace promedio | 0.5703 | 2 |
| Enlace mediano | 0.3022 | 6 |
| Centroide | 0.5703 | 2 |
| Ward.D | 0.5157 | 3 |
| Ward.D2 | 0.5148 | 3 |
| McQuitty | 0.5703 | 2 |
| k-means | 0.5157 | 3 |
| PAM | 0.5158 | 3 |
| CLARA | 0.5139 | 3 |
| Fuente: cálculos propios. |
6.5 Calculando siluetas individuales y membrecías para los algoritmos PAM y CLARA
Después de conocer el número óptimo de clústeres, podemos aplicar el respectivo algoritmo para continuar con nuestro análisis similar a lo que presentamos en las Secciones 4.7 y 5.4.3. Es importante recordar que esto solo se haría si alguno de estos métodos fueran la mejor forma de particionar los datos.
Por razones pedagógicas, en esta sección mostramos cómo calcular la silueta promedio y las membrecías para PAM y CLARA. No obstante, en nuestro caso específico no tendría sentido este análisis.
Para el caso de PAM, la función que usaremos para implementar el algoritmo es pam() del paquete cluster (Maechler et al., 2022). Esta función requiere en su forma más simple, un objeto de clase data.frame con los datos (x), el número de clústeres que queremos formar (k) y la medida de distancia (metric). Es decir, el código será
# fijamos la semilla aleatoria
set.seed(12345)
# calculamos los clústeres para k = 3
cluster_PAM<- pam(x = datos_est, k = 3,
stand = FALSE, metric = "euclidean")
# Mirar todos los comportamientos del objeto creado
attributes(cluster_PAM)## $names
## [1] "medoids" "id.med" "clustering" "objective" "isolation"
## [6] "clusinfo" "silinfo" "diss" "call" "data"
##
## $class
## [1] "pam" "partition"El objeto que creamos con el algoritmo PAM (cluster_PAM) tiene varios compartimientos (slots) entre los cuáles podemos destacar clustering que contiene las membrecías de cada uno de los clientes. Por ejemplo, las membrecías de todos los clientes las podemos extraer fácilmente de la siguiente manera:
Algo similar podemos hacer para el algoritmo CLARA empleando la función clara() del paquete cluster (Maechler et al., 2022). Esta función tiene argumentos similares a la función pam(). Sin embargo, hay dos argumentos que son diferentes:
sampsize: El tamaño de las submuestras que se emplearán. Por defecto sampsize = \(40 + 2 * k\). (Paso 1 del algoritmo CLARA)
samples: El número de veces que se repetirá el algoritmo. Es decir, el número de veces que se repetirá el algoritmo PAM, lo cuál implica el número de veces que se sacarán las muestras aleatorias (paso 5 del algoritmo CLARA). El valor por defecto es samples = 5.
En este caso, las membrecías se pueden calcular con el siguiente código:
# Fijar la semilla aleatoria
set.seed(12345)
# Calcular los clústeres para k = 3
cluster_CLARA<- clara(x = datos_est, k = 3,
stand = FALSE, metric = "euclidean")
# Mirar todos los comportamientos del objeto creado
attributes(cluster_CLARA)## $names
## [1] "sample" "medoids" "i.med" "clustering" "objective"
## [6] "clusinfo" "diss" "call" "silinfo" "data"
##
## $class
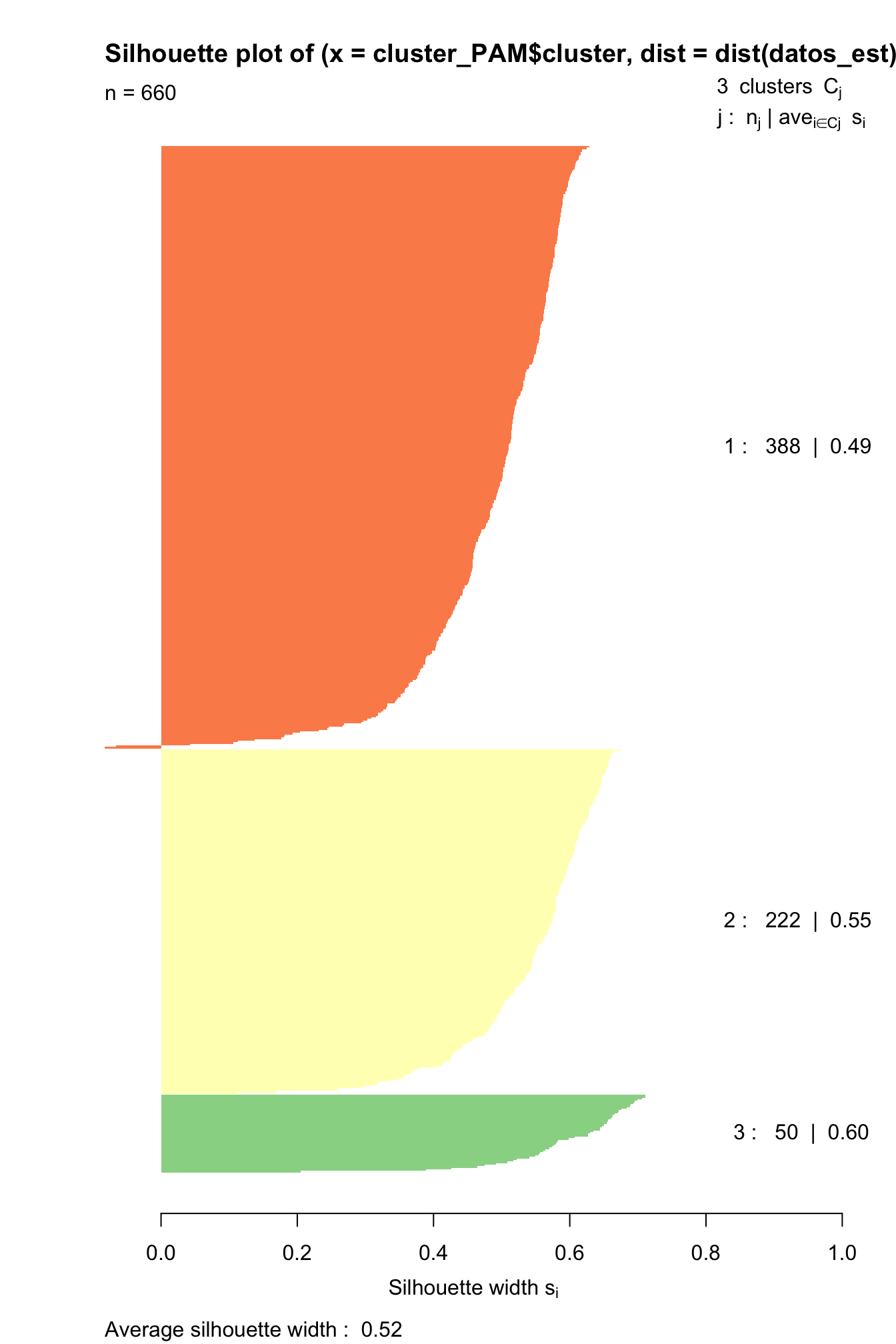
## [1] "clara" "partition"Las membrecías se pueden emplear para construir las siluetas individuales. Recuerden que esto lo podemos hacer empleando la función silhouette() del paquete cluster (Maechler et al., 2022). Intenta reproducir la Figura 6.3
Figura 6.3: Silueta para tres clústeres emplendo PAM y distancia euclidiana
6.6 Comentarios Finales
En este Capítulo estudiamos dos métodos de clústering particionado basados en centroides: PAM y CLARA. Estos dos algoritmos hacen parte de la caja de herramientas “estándar” para la tarea de hacer clústeres. Son relativamente comunes y se emplean como complemento al k-means.
En el método PAM se seleccionan observaciones como medoides iniciales y se actualizan iterativamente. Por otro lado, CLARA utiliza submuestras para manejar conjuntos de datos grandes y mejorar la eficiencia. Ambos métodos son útiles para agrupar datos en conjuntos homogéneos. Al combinarlos con k-means y los algoritmos jerárquicos (AGNES y DIANA), se pueden obtener un conjunto de algoritmos robustos para realizar el análisis de clústeres.
En los siguientes capítulos estudiaremos más métodos de clústering que te permitirán armar una caja de herramientas aún más robusta para responder a diversos problemas que impliquen armar conglomerados.
Referencias
Es muy común que el algoritmo k-medians se emplee con la distancia de Manhattan y no la euclidiana.↩︎
El modelo k-medians se puede implementar en R por medio la función Kmedians() del paquete Kmedians (Godichon-Baggioni & Surendran, 2023). ↩︎
El medoide se calcula para cada clúster como el individuo del grupo con la menor distancia total a las demás observaciones del mismo clúster.↩︎