4 Implementando los algoritmos de clústering jerárquico en R
Objetivos del capítulo
Al finalizar este capítulo, el lector estará en capacidad de:
- Implementar algoritmos jerárquicos aglomerativos (AGNES) en R.
- Implementar algoritmos jerárquicos de división (DIANA) en R.
- Seleccionar el número óptimo de clústeres para una aproximación empleando R.
- Construir dendrogramas en R.
4.1 Introducción
Como se mencionó en el Capítulo 3, los algoritmos jerárquicos para la construcción de clústeres tienen un origen en la estadística. En dicho capítulo discutimos como el HCA (por sus siglas en inglés: Hierarchical Cluster Analysis) construye una jerarquía de grupos a partir de los elementos individuales. Existen dos estrategias principales para realizar HCA:
- HCA Aglomerativo: También conocida como AGNES o método “bottom-up”, comienza con cada observación en su propio clúster y va fusionando iterativamente clústeres más similares, hasta llegar a un único grupo con todos los individuos en la muestra.
- HCA de división: Conocido como método DIANA o “top-down”, parte de un clúster que contiene todas las observaciones y lo va dividiendo de forma recursiva en conglomerados más pequeños en cada paso.
En este Capítulo nos concentraremos en cómo implementar en R un HCA. Primero nos concentraremos en la aproximación aglomerativa, cómo construir dendrogramas y cómo seleccionar el número óptimo de agrupaciones empleando los métodos estudiados en la Sección 2.4. Posteriormente, concentraremos la atención al HCA de división (DIANA).
4.2 Los datos y la pregunta de negocio
Para desarrollar este ejemplo emplearemos datos provistos por Shah (2021)43. Los datos corresponden a 660 clientes de una tarjeta de crédito. Los datos están disponibles en el archivo Credit_Card_Customer_Data.csv44. Esta base de datos contiene los siguientes 7 features (variables o características):
Sl_No: Número de cliente (sirve como índice de cada cliente en la base de datos).Customer.Key: Número de identificación del cliente.Avg_Credit_Limit: Límite de crédito promedio (no se especifica la moneda, supondremos que está en dólares).Total_Credit_Cards: Número total de tarjetas de crédito que tiene el cliente.Total_visits_bank: Total de visitas del cliente a la sucursal del banco (físicamente) emisor de la tarjeta de crédito.Total_visits_online: Total de visitas a la sucursal virtual (la plataforma electrónica) del banco emisor de la tarjeta de crédito.Total_calls_made: Total de llamadas realizadas por el cliente a la banca telefónica del banco emisor de la tarjeta de crédito.
Nuestro objetivo es emplear los datos para responder la pregunta de negocio: “Con el fin de mejorar la satisfacción del cliente, brindar una atención más personalizada a los clientes y optimizar el gasto en mercadeo, ¿cómo segmentamos a nuestros clientes?” Nuestra tarea, entonces, es crear clústeres de clientes para focalizar las acciones de mercadeo de la sucursal bancaria.
4.3 Exploración y preparación de los datos
Carguemos los datos y exploremos su clase.
# carga de archivo
datos_originales <- read.csv("Credit_Card_Customer_Data.csv")
# estructura de los datos cargados
str(datos_originales)Noten que las dos primeras variables no son útiles para nuestro análisis: Sl_No (número de cliente) y Customer.Key (número de identificación del cliente). Removamos estas variables para iniciar nuestro análisis.
Recuerda que siempre es necesario realizar una exploración de los datos. Puedes constatar que no tenemos datos perdidos. Exploremos rápidamente los datos empleando los paquetes ggplot245 (Wickham, 2016) y GGally (Schloerke et al., 2023) para tener una visualización más agradable como la que se presenta en la Figura 4.1.
# Cargar paquetes
library(ggplot2)
library(GGally)
# Graficar todas las variables de la base
ggpairs(datos) +
theme_minimal()Figura 4.1: Relación entre todas las variables de la base de datos
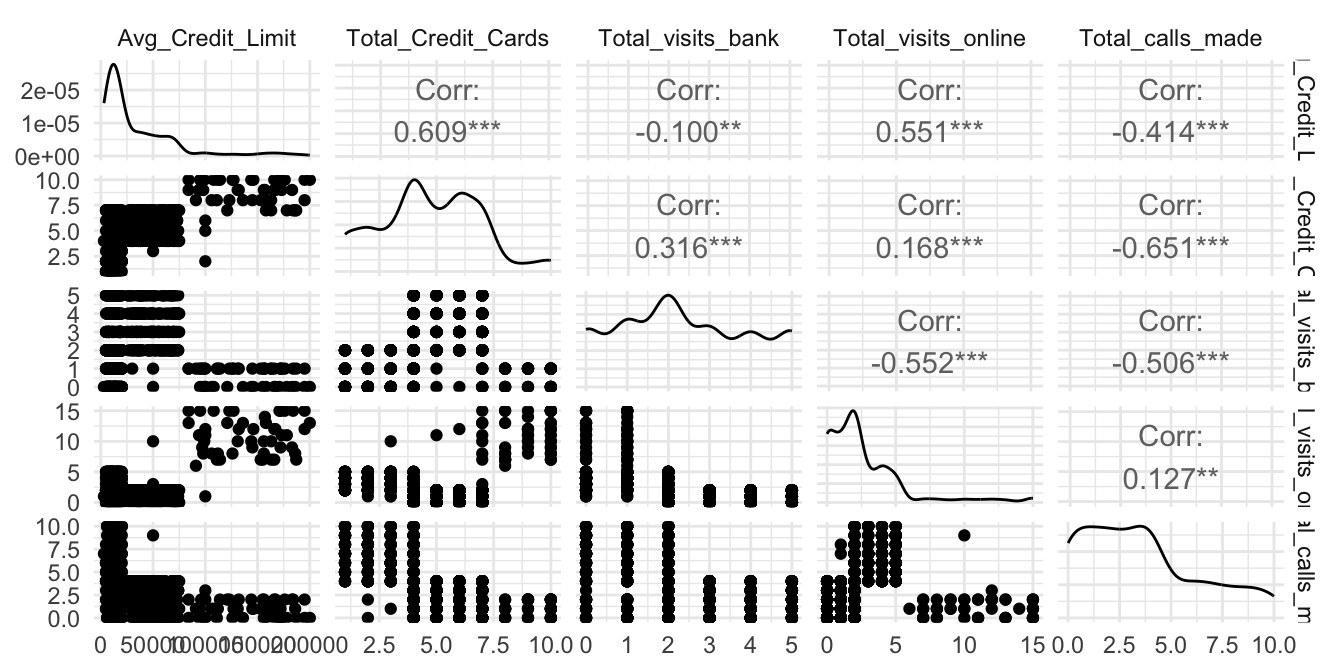
La Figura 4.1 no revela mucho; los datos no presentan una forma natural de organizarse en grupos. Esto es lo más común en la práctica, al ojo no es fácil encontrar los grupos de individuos. Podríamos trabajar un poco más con las visualizaciones pero no llegaremos muy lejos. Procedamos a construir los clústeres jerárquicos, pero antes tendremos que estandarizar los datos.
Noten que las variables tienen rangos diferentes. Por eso es importante centrarlas y, además, unificar la volatilidad de los datos. Es decir, debemos estandarizar todas las variables46 quitándoles la respectiva media (la media de la respectiva columna) y dividirla por la desviación estándar.
Para estandarizar nuestro objeto de clase data.frame podemos emplear la función scale() que está en el paquete base de R. Esta función típicamente incluye los siguientes argumentos:
donde:
- x: Es un objeto de clase matrix o data.frame.
- center: Un valor lógico que establece si las columnas de la matriz o data.frame deben centrarse o no. Es decir, si se debe restar la media o no. El valor por defecto es center = TRUE. En otras palabras, la función centra las columnas a menos que se le indique lo contrario.
- scale: Un valor lógico que establece si las columnas de la matriz deben “escalarse” o no. Es decir, si se debe dividir cada valor centrado por la desviación estándar de la correspondiente columna. El valor por defecto es scale = TRUE. Así, la función escala las columnas a menos que se le indique lo contrario.
Esta función produce los datos estandarizados en clase matrix.
Entonces, estandaricemos el objeto data.frame datos con la función scale() y convirtamos de nuevo el resultado a un objeto de clase data.frame.
# Estandarizar los datos
datos_est<- as.data.frame(scale(datos))
# Chequear clase de las variables
library(dplyr)
glimpse(datos_est)## Rows: 660
## Columns: 5
## $ Avg_Credit_Limit <dbl> 1.7388680, 0.4099816, 0.4099816, -0.1215730, 1.738…
## $ Total_Credit_Cards <dbl> -1.2482780, -0.7869883, 1.0581707, 0.1355912, 0.59…
## $ Total_visits_bank <dbl> -0.8597985, -1.4726139, -0.8597985, -0.8597985, -1…
## $ Total_visits_online <dbl> -0.5470748, 2.5186084, 0.1341882, -0.5470748, 3.19…
## $ Total_calls_made <dbl> -1.2505889, 1.8904250, 0.1454173, 0.1454173, -0.20…El siguiente paso, antes de emplear los algoritmos jerárquicos de clústering, es calcular la matriz de proximidad como lo realizamos en el Capítulo 3. Esto implicaría crear un objeto con las distancias.
Esto se puede hacer empleando la función dist() que está en el paquete central de R. El argumento method determina el tipo de medida de distancia que se quiere emplear (Ver Sección 2.2). Las opciones para este argumento son: “euclidean”, “maximum”, “manhattan”, “canberra”, “binary” o “minkowski”. Por defecto, method = “euclidean”. Así mismo, está el argumento p para establecer la potencia que se desea emplear para la distancia de Minkowski, por defecto p = 2.
Esta función creará una matriz que tiene 660 filas y columnas que contiene todas las distancias entre los individuos teniendo en cuenta las 5 variables, Es decir, empleando la notación que usamos en los capítulos anteriores tenemos que:
\[\begin{equation} x=\begin{bmatrix} x_1 & x_2 & x_3 & x_4 & x_5 \end{bmatrix} \tag{4.1} \end{equation}\] y cada celda de la matriz de proximidad tendrá el cálculo de la correspondiente distancia de los individuos de la columna \(i\) y fila \(j\) (\(d(x_i, x_j)\))47.
Noten que la matriz de distancias (proximidad) puede llegar a ser muy grande si tenemos muchas observaciones, lo que puede implicar un uso no eficiente de la memoria RAM, al almacenar un objeto tan grande. Una opción más común en la práctica de los científicos de datos, es emplear la posibilidad de calcular la matriz de distancias desde la misma función que se emplee para hacer el algoritmo de clústering. Esto puede hacer más eficiente nuestro uso de la memoria, en especial cuando estemos trabajando con millones de individuos. En este libro adoptaremos esta segunda aproximación siempre que sea posible; es decir, siempre que la función lo permita.
Empleemos por ahora la función dist() para calcular la matriz de proximidad de nuestros datos empleando la distancia euclidiana.
4.4 Construcción de clústeres jerárquicos aglomerativos y dendrograma
El siguiente paso implica emplear el algoritmo para la creación de los clústeres jerárquicos aglomerativos y visualizarlos con un dendrograma. Recordemos que esto implica seleccionar un método de aglomeración y una medida de similitud (tipo de distancia), para la construcción de los conglomerados.
La función hclust() de la base de R permite emplear los diferentes métodos o criterios de aglomeración discutidos en la sección 3.3. Esta función típicamente incluye los siguientes argumentos:
donde:
- d: Es una matriz de distancias de clase dist.
- method: El método de aglomeración que se desea emplear (Ver Sección 3.3). Las opciones son: “ward.D” (Ward Jr, 1963) , “ward.D2” (Murtagh & Legendre, 2014), “single” (enlace único), “complete” (enlace completo), “average” (enlace medio), “mcquitty”, “median” (enlace mediano) o “centroid”. Por defecto, method = “complete”.
Construyamos el clúster jerárquico empleando el método de agregación del centroide (y la distancia euclidiana). Y guardemos los resultados en el objeto HCA_centroide.
# construcción de clústeres jerárquicos
# con método de aglomeración centroide
# y distancia euclidiana
HCA_centroide <- hclust(datos_dist, method = "centroid")
# Imprimir el objeto
HCA_centroide##
## Call:
## hclust(d = datos_dist, method = "centroid")
##
## Cluster method : centroid
## Distance : euclidean
## Number of objects: 660## [1] "hclust"Antes de discutir la visualización de los resultados, recuerda que podemos emplear otros métodos de aglomeración cambiando el argumento method de la función hclust() . Por ejemplo, para emplear el método aglomeración del enlace promedio podemos emplear el siguiente código.
# construcción de clústeres jerárquicos
# con método de aglomeración enlace
# promedio y distancia euclidiana
HCA_promedio <- hclust(datos_dist, method = "average")Regresando a nuestra HAC con el método de aglomeración centroide, hemos creado un objeto de clase HCA_centroide que tiene toda la información necesaria para construir el dendrograma. Podemos visualizar los pasos del algoritmo jerárquico empleando la función plot() de la base de R.
Figura 4.2: Dedrograma para el HCA emplendo el método de aglomeración de centroide y distancia euclidiana
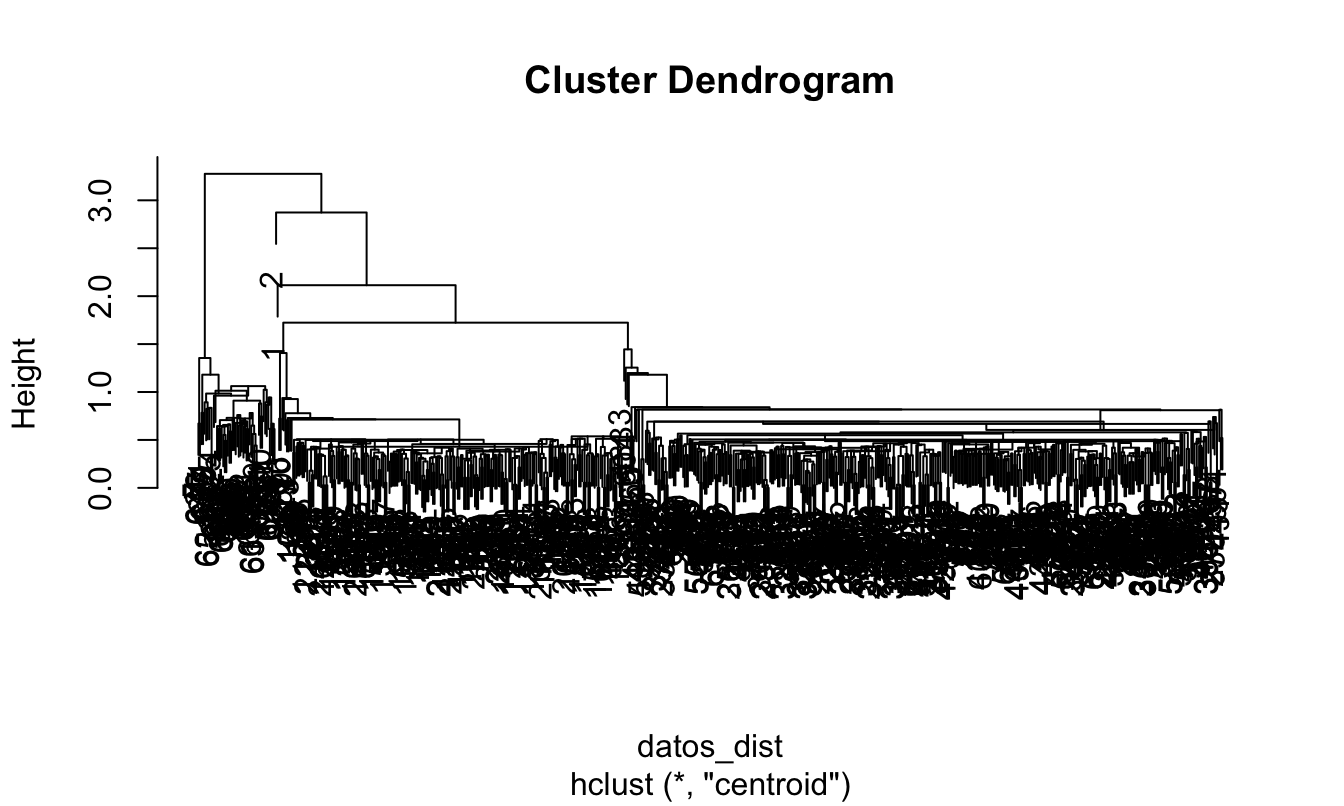
Como lo estudiamos en el Capítulo 3, un dendrograma es una representación gráfica en forma de árbol que muestra cómo el algoritmo jerárquico (en este caso aglomerativo) fue agrupando las observaciones paso a paso. La altura de las ramas representa la medida de similitud entre los elementos o grupos; ramas más largas indican mayor diferencia o distancia, mientras que ramas más cortas indican mayor similitud o proximidad.
La visualización que reportamos en la Figura 4.2 no es muy estética. Podemos jugar un poco con esta poniendo todos los nombres de las observaciones al mismo nivel empleando el argumento hang de la función plot().
Y sigamos jugando con esta visualización cambiando el tamaño de las etiquetas de los individuos (argumento cex) y poniendo títulos (argumento main).
plot(HCA_centroide, main = 'Dendrograma método centroide',
hang = -1, cex = 0.2, ylab = "Distancia")De pronto tenemos muchas observaciones como para ponerle las etiquetas a todas. Podemos omitir las etiquetas con el argumento labels = FALSE (Ver Figura 4.3)48.
Figura 4.3: Otra versión del dedrograma para el HCA emplendo el método de aglomeración de centroide y distancia euclidiana
También podríamos visualizar el dendrograma horizontalmente con el argumento horiz = TRUE
plot( as.dendrogram(HCA_centroide),main = 'Dendrograma método centroide',
type = "rectangle", horiz = TRUE, cex = 0.2, xlab = "Distancia")Por ahora no exploraremos más visualizaciones. Más adelante lo haremos, si te sientes más cómodo con visualizaciones siguiendo la lógica del paquete ggplot2 (Wickham, 2016) , puedes explorar el paquete ggdendro, (de Vries & Ripley, 2024) que agrega una geometría para poder emplear toda la estructura de ggplot2 para construir visualizaciones por capas.
4.5 Escogiendo el número óptimo de clústeres
Hasta ahora hemos agrupado de manera jerárquica los clientes del banco. El AGNES, empleando el centroide como método de aglomeración, nos ha permitido ir agrupando a los clientes de manera iterativa. Ahora la pregunta es: ¿en cuántos clústeres sería conveniente agrupar los individuos? Es decir, ¿cuál es el número de conglomerados que permiten crear los grupos que sean más diferentes entre grupos y que al interior del grupo los individuos sean lo más parecidos (de acuerdo con los 5 features que tenemos)? O visto de otra manera, ¿por dónde deberíamos podar el dendrograma?.
En la Sección 2.4 discutimos cómo responder esta pregunta empleando una batería de indicadores o solo la silueta promedio. A continuación, veremos cómo implementar en R estos métodos para escoger el número óptimo de clústeres.
4.5.1 Empleando batería de métricas
Como se mencionó en la sección 2.4, una forma de determinar el número de clústeres es emplear los 30 indicadores de uso más común. Estos se encuentran disponibles en el paquete NbClust, (Charrad et al., 2014) empleando la función NbClust(). Esta función típicamente incluye los siguientes argumentos:
donde:
data: Es un objeto de clase matriz o data.frame.
diss: El tipo de medida de distancia que se quiere emplear (ver Sección 2.2). Las opciones son: “euclidean”, “maximum”, “manhattan”, “canberra”, “binary” o “minkowski”. Por defecto, distance = “euclidean”.
min.nc: El número mínimo de clústeres que se desea evaluar. Por defecto, min.nc = 2.
max.nc: El número máximo de clústeres que se desea evaluar. Por defecto, max.nc = 15.
method: Los métodos de aglomeración que se desea emplear (ver Sección 3.3). Las opciones son: “ward.D” (Ward Jr, 1963)). , “ward.D2” (Murtagh & Legendre, 2014), “single” (enlace único), “complete” (enlace completo), “average” (enlace medio), “mcquitty”, “median” (enlace mediano) o “centroid”.
index: El índice que se desea calcular. Las opciones son: “kl”, “ch”, “hartigan”, “ccc”, “scott”, “marriot”, “trcovw”, “tracew”, “friedman”, “rubin”, “cindex”, “db”, “silhouette”, “duda”, “pseudot2”, “beale”, “ratkowsky”, “ball”, “ptbiserial”, “gap”, “frey”, “mcclain”, “gamma”, “gplus”, “tau”, “dunn”, “hubert”, “sdindex”, “dindex”, “sdbw”, “all” (todos los índices excepto GAP, Gamma, Gplus y Tau), “alllong” (todos los índices incluido Gap, Gamma, Gplus y Tau) (Ver Sección 2.4.4). Por defecto, index = “all”.
Empleemos esta función para evaluar el número de clústeres para nuestro problema usando 26 indicadores49. Recuerden que en este caso hemos escogido emplear la distancia euclidiana y como método de aglomeración el centroide y el enlace promedio. En este caso emplearemos los datos estandarizados y no la matriz de proximidad; es decir, emplearemos el objeto datos_est.
# Instalar el paquete si no se tiene
# install.packages("NbClust")
# Cargar el paquete
library(NbClust)
# calculamos las 30 métricas
res_centroid <- NbClust(datos_est, distance = "euclidean", min.nc = 2, max.nc = 10, method = "centroid", index = "all")
# Ver todos los compartimientos del objeto construido
attributes(res_centroid)En el compartimiento All.index del objeto res_centroid puedes encontrar el valor de los 26 índices para los números de clústeres de 2 a 10. En el compartimiento Best.nc se encuentra el número de grupos óptimo según cada uno de los indicadores. Para nuestro caso:
# Ver todos los indicadores por número de clúster
res_centroid$All.index
# Ver el número de clústeres óptimo según cada uno de los indicadores
res_centroid$Best.ncAdemás, podemos graficar los resultados empleando la función fviz_nbclust() del paquete factoextra (Kassambara & Mundt, 2020) . Esta función emplea el paquete ggplot2 (Wickham, 2016) para realizar las gráficas50.
Procedamos a visualizar los resultados.
# Instalar el paquete si se necesita
# install.packages("factoextra")
# cargar el paquete
library(factoextra)
# visualizando las métricas (sigue leyendo si te sale un mensaje de error)
fviz_nbclust(res_centroid) + theme_minimal()
Si estás empleando una versión de R superior a 4.2, tendrás un mensaje de error. La función fviz_nbclust() tiene un problema que está bien documentado en la comunidad de R51 y a la fecha de la publicación de este libro aún no ha sido solucionado. Para resolver el problema puedes emplear la siguiente función52:
nueva_fviz_nbclust <- function(x, print.summary = TRUE,
barfill = "steelblue",
barcolor = "steelblue"){
best_nc <- x$Best.nc
best_nc <- as.data.frame(t(best_nc), stringsAsFactors = TRUE)
best_nc$Number_clusters <- as.factor(best_nc$Number_clusters)
ss <- summary(best_nc$Number_clusters)
cat("Entre todos los índices: \n===================\n")
for (i in 1:length(ss)) {
cat("*", ss[i], "proponen ", names(ss)[i],
"como el mejor número de clústeres\n")
}
cat("\nConclusión\n=========================\n")
cat("* De acuerdo con la mayoría, el mejor número de clústeres es is ",
names(which.max(ss)), ".\n\n")
df <- data.frame(Number_clusters = names(ss),
freq = ss,
stringsAsFactors = TRUE)
p <- ggpubr::ggbarplot(df, x = "Number_clusters", y = "freq",
fill = "steelblue", color = "steelblue") +
ggplot2::labs(x = "Número de clústeres k",
y = "Frecuencia entre todos los índices",
title = paste0("Número óptimo de clústeres - k = ",
names(which.max(ss))))
p
}## Entre todos los índices:
## ===================
## * 2 proponen 0 como el mejor número de clústeres
## * 6 proponen 2 como el mejor número de clústeres
## * 2 proponen 3 como el mejor número de clústeres
## * 1 proponen 4 como el mejor número de clústeres
## * 12 proponen 5 como el mejor número de clústeres
## * 2 proponen 10 como el mejor número de clústeres
## * 1 proponen NA's como el mejor número de clústeres
##
## Conclusión
## =========================
## * De acuerdo con la mayoría, el mejor número de clústeres es is 5 .Figura 4.4: Votación de la batería de métricas por el número óptimo de clústeres para el HCA empleando el método de aglomeración de centroide y distancia euclidiana
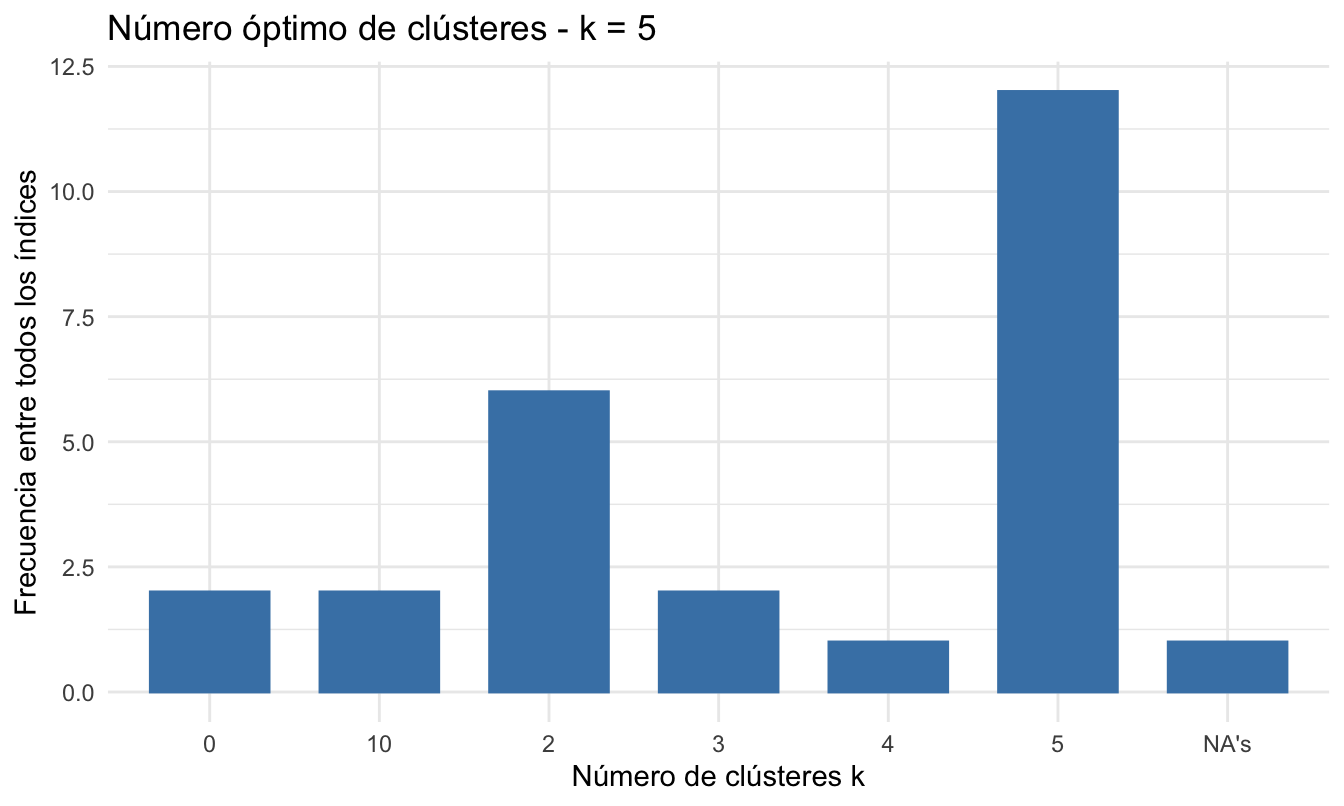
De acuerdo con los resultados reportados en la Figura 4.4, 12 de los 30 métodos sugieren 5 clústeres, mientras que 6 índices sugieren 2 conglomerados.
Ustedes pueden replicar el resultado para los otros métodos de aglomeración. Por ejemplo, para el método del enlace promedio el código sería:
# calculamos las 30 métricas
res_media<-NbClust(datos_est, distance = "euclidean", min.nc = 2,
max.nc = 10, method = "average", index = "all")Si inspeccionas los resultados, encontrarás que, para el método del enlace promedio, el resultado es algo diferente. En este caso, 16 indicadores sugieren 3 clústeres y otras 4 métricas sugieren 2 clústeres. Esta contradicción en las votaciones de los indicadores, hace que, en la práctica, algunos científicos de datos prefieran emplear solo un criterio, como por ejemplo la silueta promedio por su fácil interpretación.
4.5.2 Empleando la silueta promedio
Otra aproximación complementaria para determinar el número de clústeres es emplear la silueta promedio (Ver Sección 2.4.3 para una definición de la silueta y cómo se interpreta.) . Esto se puede hacer rápidamente empleando la función NbClust() que empleamos en la sección anterior. Solo necesitamos fijar el argumento index igual a “silhouette”. Es decir:
#detectar el número de clúster óptimo empleando la silueta promedio
res_centroid_Sil <- NbClust(datos_est, distance = "euclidean", min.nc = 2, max.nc = 10, method = "centroid", index = "silhouette")
# mirar el resultado óptimo
res_centroid_Sil$Best.ncNoten que el número de clústeres que maximiza la silueta es 253. La silueta promedio para 2 clústeres es 0.57. Esta silueta implica que la estructura de clasificación encontrada es aceptable, pues está entre 0.51 y 0.7 (Ver Capitulo @ref{Metricas}).
También puede ser interesante ver las siluetas individuales por medio de un gráfico de siluetas (Silhoutte Plots en inglés). Este gráfico muestra qué tan bien se ajusta cada observación al clúster que ha sido asignado comparando qué tan cerca se encuentra de las demás en su conglomerado, dado un número determinado de conglomerados. Como se discutió en la Sección 2.4.3, una silueta cercana a uno significa que la observación está bien ubicada en su grupo, mientras que cerca a cero o menor implica que es posible que el individuo fue mal clasificado en su clúster.
La función silhouette() del paquete cluster (Maechler et al., 2022) permite calcular las siluetas para todas las observaciones. Esta función típicamente incluye los siguientes argumentos:
donde:
- x: Es un objeto de clase matriz o data.frame.
- dist: Una matriz de distancias de clase dist.
- dmatrixc: Una matriz simétrica de distancias.
Para aplicar esta función, además tendremos que especificar el número de clústeres que deseamos evaluar. Para esto podemos emplear la función cutree() del paquete base de R. Esta función corta un árbol (dendrograma) resultado de aplicar la función hclust() al nivel (número de clústeres) que se desee. Es decir, para incluir 2 clústeres (\(q=2\)) o 5 (\(q=5\)). Esta función típicamente incluye los siguientes argumentos:
donde:
- tree: Un dendrograma (árbol) de clase hclust.
- k: El número de clústeres54.
Para el HCA con método de aglomeración centroide, distancia euclidiana y para \(q=2\) (de acuerdo con los resultados encontrados anteriormente), podemos emplear las siguientes líneas de código.
# instalamos el paquete si se
# necesita
# install.packages("cluster")
# cargamos el paquete
library(cluster)
# comprobamos la clase del objeto
class(HCA_centroide)
# graficamos las siluetas
plot(silhouette(cutree(HCA_centroide,2),
datos_dist ),border=NA)En la Figura 4.5 podemos observar que 50 clientes fueron clasificados en el clúster 2 y los restantes 610 en el grupo 1. Los clientes del conglomerado 2 tienen una silueta promedio de 0.62, más alta que el promedio del clúster 1 (0.57). En el clúster 2 no encontramos clientes con silueta individual por debajo de 0.5; mientras que en el clúster 1 sí encontramos clientes con siluetas inferiores a 0.5, pero superiores a 0.4. Recuerda que cuando la silueta por debajo de 0.5 (pero superiores a 0.25) indica que la estructura de clasificación encontrada es débil y puede ser artificial.
Figura 4.5: Silueta para el HCA con dos clústeres emplendo el método de aglomeración de centroide y distancia euclidiana

Ahora empleemos el criterio de la silueta promedio para escoger el número de clústeres óptimo para los 5 métodos de aglomeración que nos faltaban. De tal manera que construiremos los siguientes objetos:
- Enlace único:
res_unico_Sil, (Single linkage) - Enlace completo:
res_completo_Sil, (Complete linkage) - Enlace promedio:
res_promedio_Sil, - Enlace mediano:
res_mediano_Sil, - Centroide:
res_centroide_Sil, - Ward.D:
res_ward_D_Sil, - Ward.D2:
res_ward_D2_Sil, y - McQuitty:
res_Mcquitty_Sil.
Tras realizar la búsqueda del número de clústeres óptimo con el criterio de la silueta, obtenemos los resultados que se presentan en el Cuadro 4.1. Intencionalmente no se presenta el código para producir este cuadro. ¡Intenta reproducirla empleando la función NbClust()!
| Método de aglomeración | Silueta promedio | Número óptimo de clústeres |
|---|---|---|
| Enlace único | 0.3758 | 3 |
| Enlace completo | 0.5703 | 2 |
| Enlace promedio | 0.5703 | 2 |
| Enlace mediano | 0.3022 | 6 |
| Centroide | 0.5703 | 2 |
| Ward.D | 0.5157 | 3 |
| Ward.D2 | 0.5148 | 3 |
| McQuitty | 0.5703 | 2 |
| Fuente: cálculos propios. |
En el Cuadro 4.1 podemos ver que los métodos de aglomeración de enlace completo, enlace promedio, centroide y McQuitty generan el mismo resultado, con la mayor silueta. Así, continuemos empleando los resultados del método de centroide que ya habíamos analizado anteriormente.
Miremos en más detalle los resultados que tenemos con el HCA, el método de aglomeración centroide, distancia euclidiana y dos clústeres.
Antes de continuar con el análisis de los resultados, veamos cómo realizar el HCA división (DIANA).
4.6 Construcción de clústeres jerárquicos de división
El algoritmo jerárquico de división (DIANA) puede implementarse fácilmente en R empleando la función diana() del paquete cluster (Maechler et al., 2022). Esta función típicamente incluye los siguientes argumentos:
donde:
- x: Es un objeto de clase matrix o data.frame que contiene los datos. También es posible entregar los datos a la función con una matriz de proximidad.
- metric: Especifica el tipo de distancia que se desea emplear para calcular la matriz de proximidad (o de disparidad). Solo hay dos opciones disponibles “euclidean” y “manhattan”. Si se quisiera emplear una medida de proximidad diferente, entonces se puede emplear en el argumento una matriz de proximidad calculada previamente, por ejemplo con la función dist() como lo vimos anteriormente.
- stand: Si este parámetro se establece igual a TRUE, los datos serán estandarizados. Nota que si x es una matriz de distancias, entonces este argumento será ignorado. El valor por defecto de este argumento es FALSE.
- keep.diss: Operador lógico que indica si la matriz de proximidad debe mantenerse en el resultado. Si se establece en FALSE, se pueden obtener objetos con menor tamaño y, por tanto, ahorrar tiempo de asignación de memoria RAM. Pero en algunos casos, como lo veremos pronto, será necesario guardar esta matriz.
Implementemos el algoritmo DIANA empleando la distancia euclidiana. Adicionalmente, empleemos los datos estandarizados (datos_est); por tanto, no es necesario volver a estandarizar los datos. Finalmente, guardemos la matriz de proximidad. El correspondiente código será:
Puedes visualizar el objeto HCA_DIANA como lo hicimos anteriormente con el HCA aglomerativo. Nota que en el compartimiento diss del objeto HCA_DIANA encontrarás la matriz de disparidad.
Ahora podemos visualizar las agrupaciones jerárquicas realizadas por el algoritmo DIANA con un dendrograma. Esto lo podríamos hacer con la función plot() como lo hicimos en el caso del algoritmo AGNES. Pero intentemos otra función para aprender algo diferente. Podemos emplear la función fviz_dend() del paquete factoextra (Kassambara & Mundt, 2020). Esta función permite visualizar dendrogramas en formato ggplot2.
Figura 4.6: Dedrograma para DIANA y distancia euclidiana
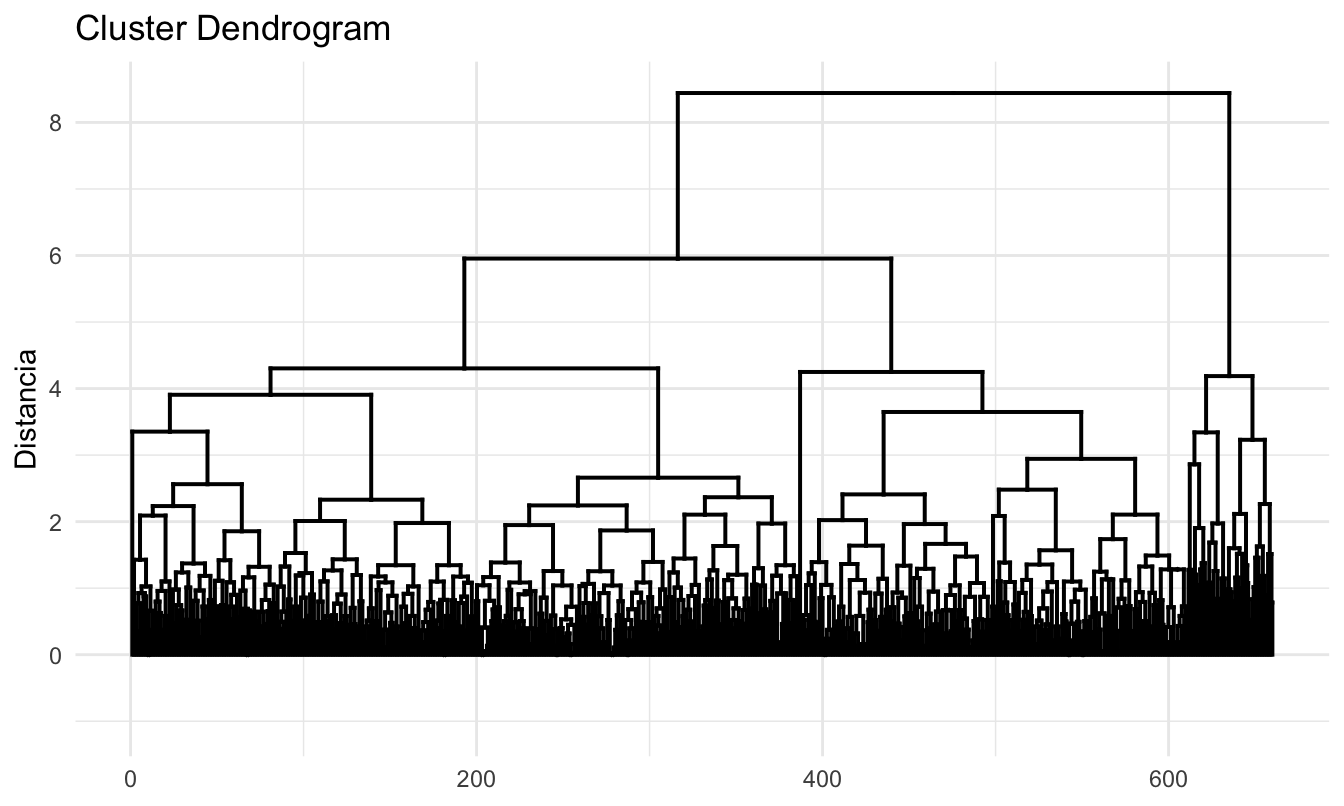
Este paquete provee gran versatilidad de dendrogramas. Por ejemplo, intenta jugar un poco con el siguiente código que genera la Figura 4.7.
Figura 4.7: Dedrograma circular para DIANA, distancia euclidiana y cortando el árbol en 3 clústeres
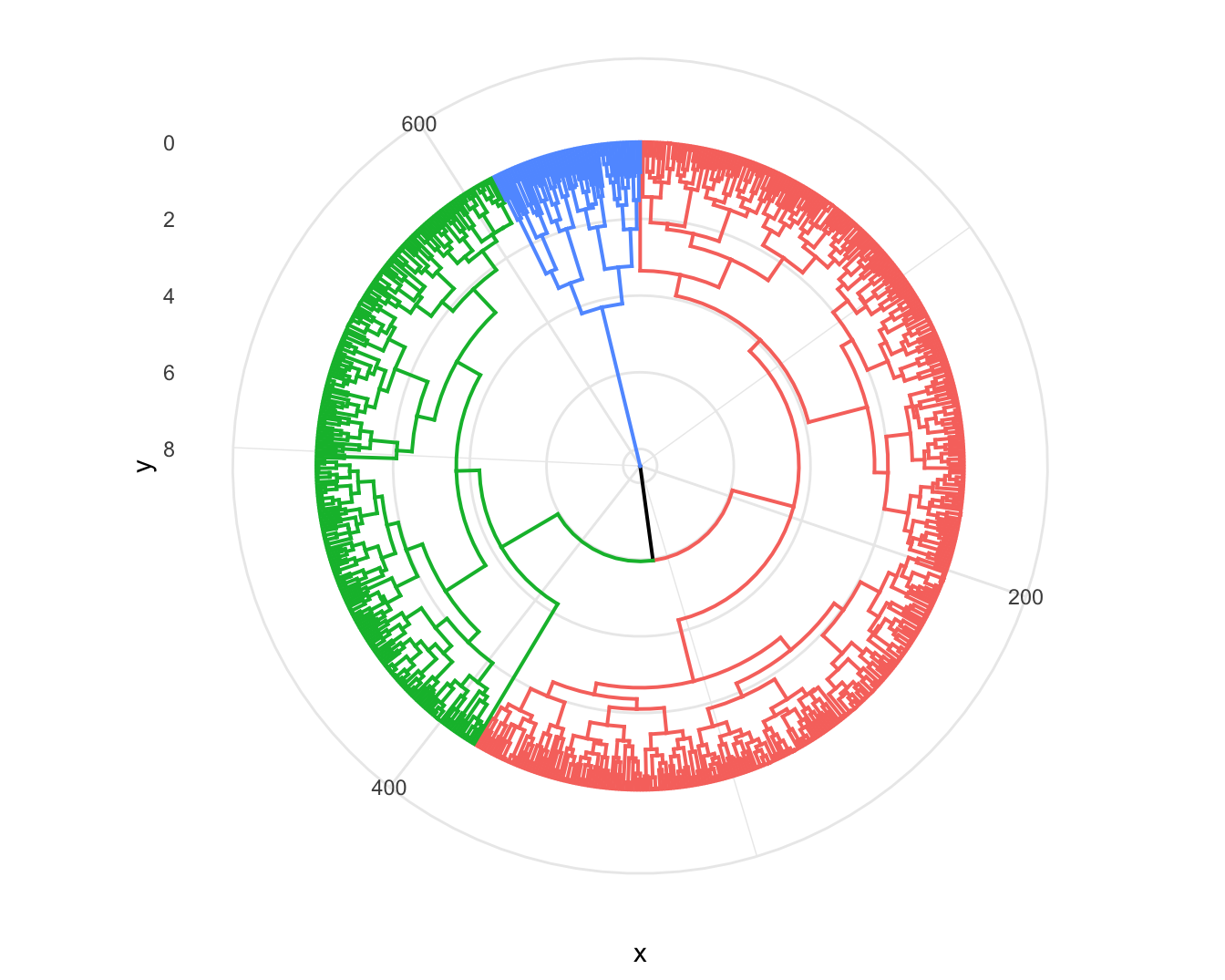
Continuemos con nuestro HCA. Recuerda que si bien hemos construido jerárquicamente todos los posibles clústeres, aún no sabemos cuál es el número de grupos óptimo (por donde cortar el árbol). De manera análoga a lo realizado en la sección anterior, podemos emplear la función NbClust(). Solo necesitamos hacer un truco para incluir DIANA a las posibilidades que nos brinda esta función, pues recuerda que DIANA no es una de las opciones del argumento method. El truco es: no alimentar la función con datos estandarizados, sino con la matriz de disparidad y en el argumento method emplear la opción “single”. Nota que el método de aglomeración simple es similar a los pasos que realizamos en el algoritmo DIANA55. Así, el código para encontrar el número óptimo de clústeres por medio de la silueta promedio es el siguiente:
library(NbClust)
res_DIANA_Sil <- NbClust(data = NULL, diss = HCA_DIANA$diss,
distance = NULL, min.nc = 2, max.nc = 10,
method= "single", index = "silhouette")## Number_clusters Value_Index
## 3.0000 0.3758Nota que, en este caso, el número óptimo de clústeres sería de 3 y la silueta promedio es de 0.3758. Esta silueta es sustancialmente menor que la que encontramos con la aproximación aglomerativa (Ver Cuadro 4.1). Así, en este caso en particular, es mejor el método jerárquico aglomerativo con método de aglomeración centroide y 2 clústeres. Continuemos el análisis de los resultados.
4.7 Visualización y analisis de resultados
Ya hemos detectado el mejor método jerárquico para agrupar los datos, empleando la distancia euclidiana,56 y un algoritmo aglomerativo con el método de centroide y 2 clústeres.
Ahora, concentrémonos en los resultados del ejercicio de clústering. Con la misma función cutree() del paquete base de R que ya habíamos empleado, podemos obtener los resultados del algoritmo de clústering para el número de conglomerados deseados. En este contexto, por resultados del algoritmo de clustering se entiende como el respectivo clúster al que se asigna cada observación, también conocida como la membrecía de cada individuo a un conglomerado.
Veamos la membrecía de los primeros 10 clientes.
## [1] 1 1 1 1 2 1 2 1 1 1Esto implica que los primeros cuatro clientes pertenecen al clúster 1 y el quinto cliente y el séptimo hacen parte del clúster 2. Ahora podemos incluir esta variable de membrecía (variable cualitativa) a los datos originales.
datos_con_segmentacion <- cbind(datos_originales, (as.factor(grupos_HCA_aglo)))
names(datos_con_segmentacion)[8] <- "cluster"
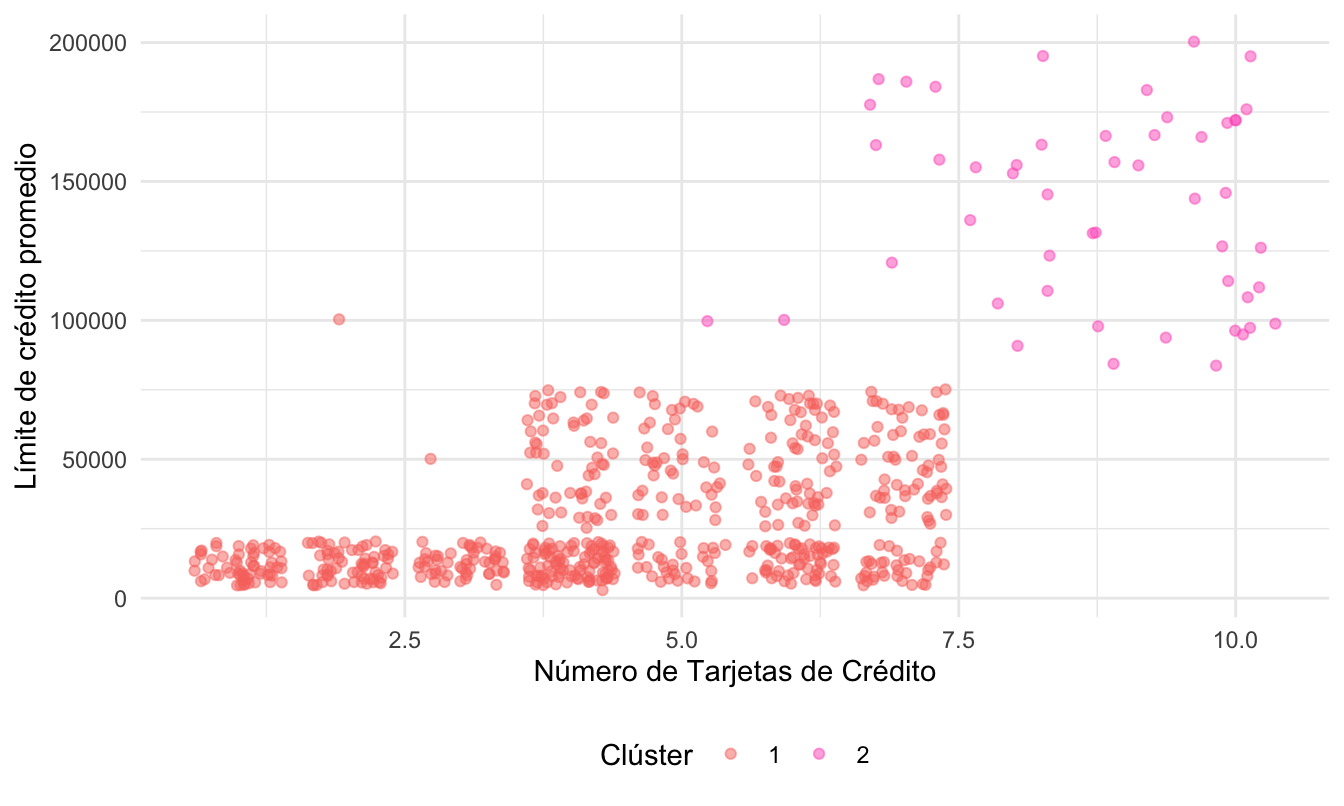
# str(datos_con_segmentacion)Una tarea que, típicamente, se realiza tras construir los clústeres es examinar el comportamiento de diferentes variables en cada uno de los grupos. Exploremos un poco cómo se agrupan los datos. Por ejemplo, la Figura 4.8 muestra cómo se separan de manera relativamente clara los datos en los dos clústeres si consideramos el límite de crédito promedio y el número de tarjetas de crédito (el código que genera esta visualización se presenta en el Anexo 1 de este Capítulo (sección 4.9.1)).
Figura 4.8: Relación entre el límite de crédito promedio y el número de tarjetas de crédito por clúster
Otra forma muy común de visualizar cada variable para los diferentes clústeres es emplear boxplots. En la Figura 4.9 se observa la distribución por clúster de todas las variables empleadas para construir las agrupaciones (el código que genera esta visualización se presenta en el Anexo 1 de este Capítulo (Sección 4.9.1)).
Figura 4.9: Distribución de las variables empleadas para construir las agrupaciones por clúster
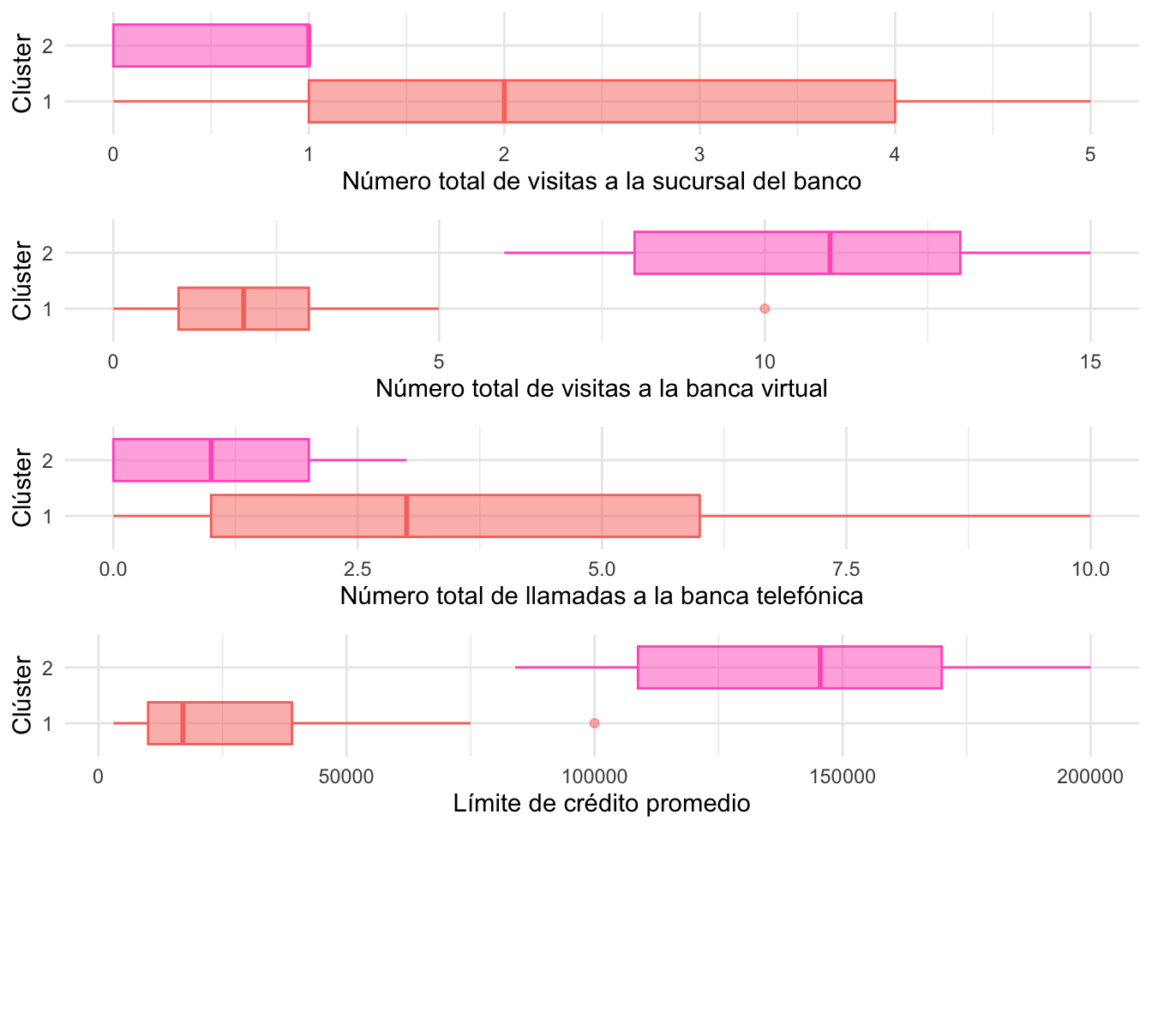
La Figura 4.9 permite ver que el clúster 1 está conformado por los clientes con un monto de límite de crédito aprobado relativamente bajo, que visitan poco la banca virtual y emplean con frecuencia relativamente alta el Banco y la Banca telefónica. Por otro lado, en el clúster dos se encuentran los clientes con un mayor cupo promedio de crédito aprobado. Este segundo clúster se caracteriza porque sus miembros usan relativamente mucho más la banca virtual (en comparación al clúster uno) y no usan con tanta frecuencia las visitas al banco o las llamadas a la banca telefónica.
El segundo clúster lo podríamos llamar: el clúster de clientes premium. Noten que esto ya le permitiría a la sucursal bancaria generar diferentes estrategias de mercadeo y de servicio al cliente para los dos clústeres.
En el Anexo 2 de este Capítulo (Sección 4.9.2) se presenta un análisis estadístico complementario para determinar si los clústeres presentan medias diferentes. Ese tipo de análisis puede ser muy útil para entender las características de los conglomerados construidos. Pero no se debe emplear para validar si los clústeres quedaron bien conformados o no, pues los algoritmos de construcción no necesariamente tienen como lógica hacer que las medias sean diferentes entre los grupos.
Ahora visualicemos los resultados de diferentes maneras. Por ejemplo, en algunas ocasiones puede ser deseable resaltar los conglomerados seleccionados directamente en el dendrograma (Ver Figura 4.10).
plot(HCA_centroide, main = "Dendrograma método del centroide",
hang = -1, cex = 0.1, ylab = "Distancia")
rect.hclust(HCA_centroide, k = 2, border = 2:5 )
Figura 4.10: Dendrograma método del centroide
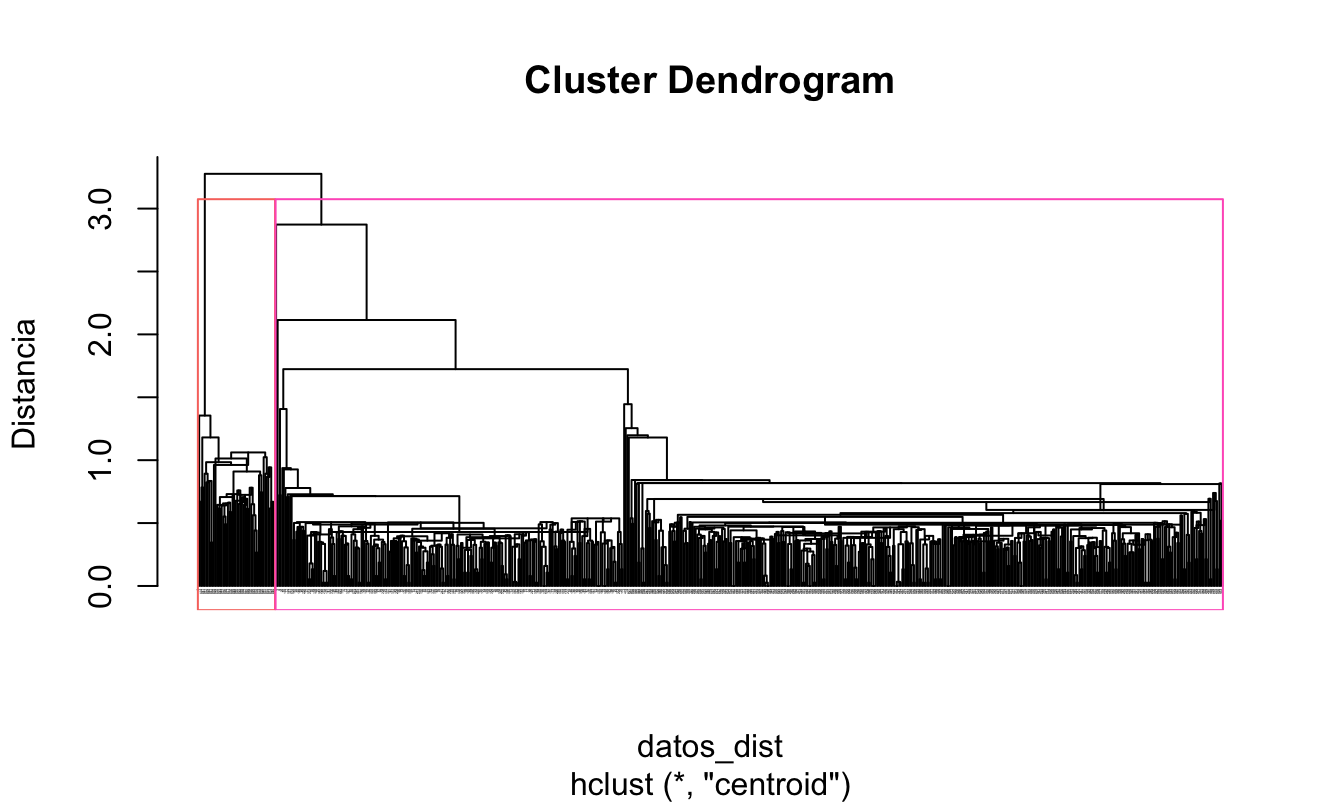
Esta forma de visualización permite acentuar los resultados y muestra los dos grupos seleccionados.
Si queremos variar la estética, podemos emplear el paquete ape (R Core Team, 2020). Ese paquete tiene la función plot.phylo() que grafica dendrogramas. Esta función incluye los siguientes argumentos:
donde:
- x: Es un objeto de clase phylo que contiene el dendrograma. Se puede emplear la función as.phylo() para convertir un objeto de clase hclust a clase phylo.
- type: Determina el tipo de dendrograma. Las opciones son: “phylogram”, “cladogram”, “fan”, “unrooted” y “radial”. Más adelante ilustraremos cada uno de esos tipos con un ejemplo. Por defecto type = “phylogram”.
- show.tip.label: Permite mostrar o no las etiquetas de cada individuo. Por defecto se muestran las etiquetas (show.tip.label = TRUE).
- edge.color: Permite escoger los colores de las ramas. Por defecto se emplea el negro (edge.color = “black”).
- edge.width: Un número que especifica el ancho de las ramas. Por defecto edge.width = 1.
- tip.color = “black”: El color de la etiqueta. El valor por defecto es tip.color = “black”.
A continuación, se presentan diferentes visualizaciones empleando esta función.
# instalamos el paquete si se
# necesita
# install.packages("ape")
# cargamos el paquete
library(ape)
plot.phylo(as.phylo(HCA_centroide), cex = 0.4, label.offset = 0.5,
edge.lty = 6)
Figura 4.11: Dendrograma método del centroide con el paquete ape

colores <- c("#F8766D","#FF61C3")
plot(as.phylo(HCA_centroide), cex = 0.2, label.offset = 0.5,
tip.color = colores[grupos_HCA_aglo])
Figura 4.12: Dendrograma método del centroide con colores en las etiquetas
plot(as.phylo(HCA_centroide), cex = 0.2, label.offset = 0.5,
tip.color = colores[grupos_HCA_aglo], type = "cladogram")
Figura 4.13: Dendrograma método del centroide tipo ucladogram
plot(as.phylo(HCA_centroide), cex = 0.2, label.offset = 0.5,
tip.color = colores[grupos_HCA_aglo], type = "unrooted")
Figura 4.14: Dendrograma método del centroide tipo unrooted
plot(as.phylo(HCA_centroide), cex = 0.2, label.offset = 0.5,
tip.color = colores[grupos_HCA_aglo], type = "fan")
Figura 4.15: Dendrograma método del centroide tipo fan
plot(as.phylo(HCA_centroide), cex = 0.2, label.offset = 0.5,
tip.color = colores[grupos_HCA_aglo], edge.color = "steelblue",
edge.width = 2, edge.lty = 2)
Figura 4.16: Dendrograma método del centroide horizontal

Otra opción es emplear el paquete ggdendro (de Vries & Ripley, 2024), que permite hacer dendrogramas con la lógica del paquete ggplot2. En este caso, la función que emplearemos es ggdendrogram(). A continuación se presentan unos ejemplos.
# instalamos el paquete si se
# necesita
# install.packages("ggdendro")
# cargamos el paquete
library(ggdendro)
ggdendrogram(HCA_centroide)
ggdendrogram(HCA_centroide, rotate = TRUE)
ggdendrogram(HCA_centroide, rotate = TRUE,
theme_dendro = FALSE) +
labs(title="Dendrograma con ggplot2")+
theme_minimal()
Finalmente, regresemos al paquete factoextra (Kassambara & Mundt, 2020) que usamos anteriormente. Como se discutió antes, este paquete emplea ggplot2 para realizar las visualizaciones. La función fviz_dend() de este paquete tiene los siguientes argumentos:
donde:
- x: Es un objeto de clase hclust, agnes, diana, hcut, hkmeans o HCPC.
- k: El número de clústeres57.
- cex: El tamaño de la etiquetas. Por defecto cex = 0.8 de distancias.
- color_labels_by_k: Si se desea que se coloree los grupos o no.
- rect: Si se desea adicionar un rectángulo para acentuar los conglomerados. Por defecto, rect = FALSE.
Veamos un ejemplo.
Figura 4.17: Dendrograma método del centroide
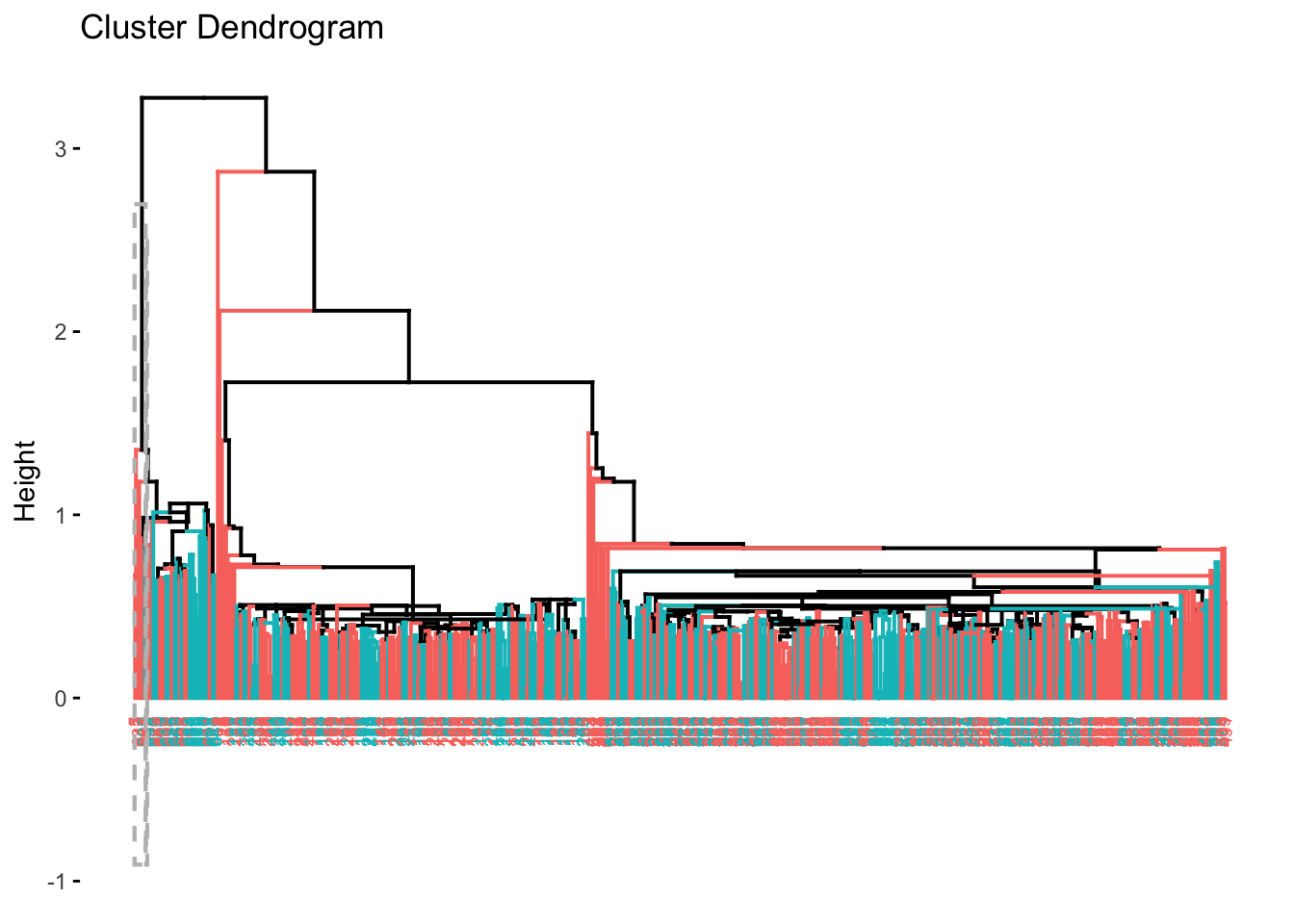
En el mismo paquete está una función que permite encontrar los primeros dos Componentes Principales (para una discusión de esta técnica ver Alonso C. (2020)) y. en ese espacio, visualizar los clústeres construidos. Esa función es fviz_cluster(). Esta función requiere que la alimentemos con los datos (estandarizados) para calcular los dos primeros componentes principales y un objeto que tenga la membrecía de cada uno de los individuos. Es decir,
fviz_cluster(list(data = datos_est, cluster = grupos_HCA_aglo))+
theme_minimal() + scale_colour_manual(values = c("#F8766D","#FF61C3")) +
scale_fill_manual(values = c("#F8766D","#FF61C3"))
Figura 4.18: Dendrograma método del centroide
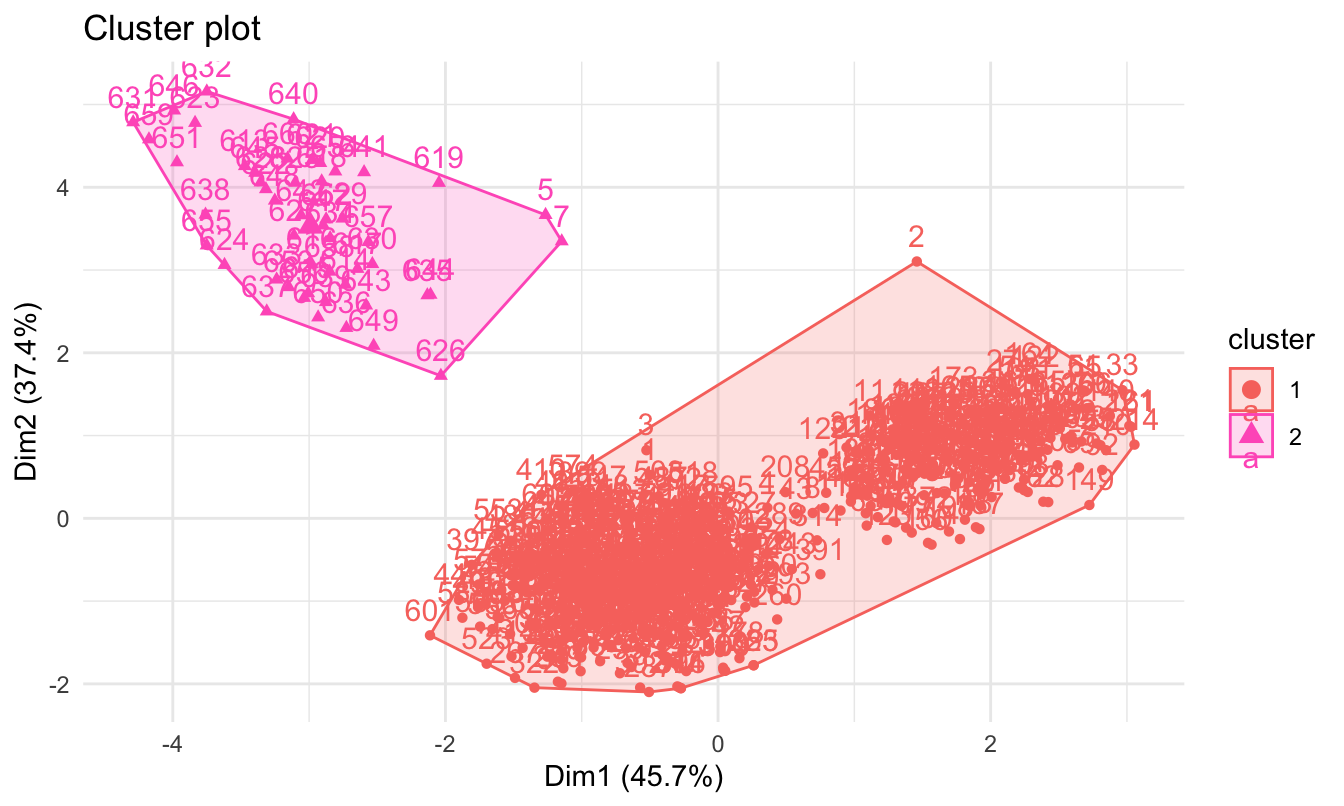
La Figura 4.18 nos muestra que los dos componentes principales que resumen las variables empleadas en el clústering explican el 83.1% de la variación de estas. Esto es relativamente alto. Por otro lado, y más importante para nuestro estudio, cuando mapeamos a ese espacio (espacio que representa el 83.1% de la variación de las variables originales) los individuos, observamos cómo el algoritmo de clasificación pudo separar los datos de una manera aparentemente acertada.
Por último, guarda el espacio de trabajo para ser empleado en los siguientes capítulos.
4.8 Comentarios finales
Finalmente, es importante anotar que una tarea prioritaria es tratar de caracterizar cada uno de los clústeres. En la práctica es común que las organizaciones quieran ponerles nombres a los conglomerados. Por ejemplo, si estamos hablando de clústeres de clientes, el área de mercadeo deseará “bautizar” los segmentos encontrados. El grupo de clientes “premium”, los “gold”, etc. Esta tarea no es fácil, pero se puede realizar entendiendo de manera muy detallada las características de los individuos al interior de los conglomerados. En el siguiente capítulo estudiaremos otro tipo de algoritmo de clústering.
4.9 Anexos
4.9.1 Anexo 1. Código para generar visualizaciones de las variables en los clústeres
A continuación se presenta el código que generó la Figura 4.8.
library(ggplot2)
ggplot(datos_con_segmentacion, aes(x = Total_Credit_Cards,
y = Avg_Credit_Limit, col = cluster)) +
geom_jitter( size = 1.5, alpha = 0.5) +
scale_color_manual(values = c(`1` = "#F8766D", `2` = "#FF61C3"
)) +
labs(x = "Número de Tarjetas de Crédito",
y = "Límite de crédito promedio",
color = "Clúster") +
theme_minimal() +
theme(legend.position = "bottom")El siguiente código generó la Figura 4.9.
p2 <- ggplot(datos_con_segmentacion, aes(y= cluster,
x= Total_visits_bank,
col= cluster, fill = cluster)) +
geom_boxplot(alpha = 0.5) +
scale_color_manual(aesthetics = c("fill", "colour"),
values = c(`1` = "#F8766D", `2` = "#FF61C3")) +
labs(x = "Número total de visitas a la sucursal del banco",
y = "Clúster") +
theme_minimal() +
theme(legend.position = "none")
p3 <- ggplot(datos_con_segmentacion, aes(y= cluster,
x= Total_visits_online,
col= cluster, fill = cluster)) +
geom_boxplot(alpha = 0.5) +
scale_color_manual(aesthetics = c("fill", "colour"),
values = c(`1` = "#F8766D", `2` = "#FF61C3")) +
labs(x = "Número total de visitas a la banca virtual",
y = "Clúster") +
theme_minimal() +
theme(legend.position = "none")
p4 <- ggplot(datos_con_segmentacion, aes(y= cluster,
x= Total_calls_made,
col= cluster, fill = cluster)) +
geom_boxplot(alpha = 0.5) +
scale_color_manual(aesthetics = c("fill", "colour"),
values = c(`1` = "#F8766D", `2` = "#FF61C3")) +
labs(x = "Número total de llamadas a la banca telefónica",
y = "Clúster") +
theme_minimal() +
theme(legend.position = "none")
p5 <- ggplot(datos_con_segmentacion, aes(y= cluster,
x= Avg_Credit_Limit,
col= cluster, fill = cluster)) +
geom_boxplot(alpha = 0.5) +
scale_color_manual(aesthetics = c("fill", "colour"),
values = c(`1` = "#F8766D", `2` = "#FF61C3")) +
labs(x = "Límite de crédito promedio", y = "Clúster") +
theme_minimal() +
theme(legend.position = "none")
library(gridExtra)
grid.arrange(p2, p3, p4, p5, nrow = 5)4.9.2 Anexo 2. Empleando modelos ANOVA para comparar las medias en los clústeres construidos
Podemos hacer un análisis estadístico complementario para determinar si los grupos que se formaron tienen un comportamiento diferente en su media. Para eso comparemos las medias de los grupos.
## Group.1 Avg_Credit_Limit Total_Credit_Cards Total_visits_bank
## 1 1 25847.54 4.37541 2.55082
## 2 2 141040.00 8.74000 0.60000
## Total_visits_online Total_calls_made
## 1 1.92623 3.788525
## 2 10.90000 1.080000Veamos si realmente existe una diferencia en las medias entre los grupos empleando un modelo ANOVA. Esto se debe hacer para cada una de las variables. A manera de ejemplo, lo haremos solo para la variables Avg_Credit_Limit. Para esto empleemos la función aov() que se encuentra en el paquete base de R.
Esta función típicamente incluye los siguientes argumentos:
donde:
- formula: Es una fórmula que especifica el modelo a estimar. A mano derecha se expresa la variable continua dependiente, en vez del signo igual se emplea “\(\sim\)” y a la izquierda del signo se expresan las variables categóricas. En caso de existir más de una variable categórica se separan con un singo de “\(+\)”. Por ejemplo, si se quiere probar si la media de la variable cuantitativa \(y\) es diferente para las diferentes categorías de la variable cualitativa \(x\), entonces la fórmula será \(y \sim x\).
- data: Corresponde al data.frame que se empelará para estimar el modelo ANOVA.
Entonces las siguientes líneas presentan el cálculo del modelo ANOVA.
fit_credit_limit <- aov( Avg_Credit_Limit ~ cluster,
data = datos_con_segmentacion )
summary(fit_credit_limit)## Df Sum Sq Mean Sq F value Pr(>F)
## cluster 1 6.132e+11 6.132e+11 1262 <2e-16 ***
## Residuals 658 3.197e+11 4.859e+08
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Un mirada precipitada a estos resultados nos podrían llevar a concluir, con un 99% de confianza, que se puede rechazar la hipótesis nula de que las medias de los cupos promedios aprobados por cliente sean iguales entre los dos grupos. Pero recuerda que es necesario comprobar los supuestos del modelo para poder sacar conclusiones.
Entonces, procedamos a constatar el cumplimiento de los supuestos. Recuerden que los supuestos de un modelo ANOVA son: varianza constante, independencia entre las observaciones y normalidad de los residuales. La independencia entre las observaciones parece más fácil de argumentar que se cumple, pues no necesariamente el cupo aprobado de un cliente afecta al de otro cliente. Este supuesto lo dejaremos de lado.
Para constatar la varianza homogénea podemos emplear la prueba de Levene. Esta se puede implementar con la función leveneTest() del paquete car (Fox & Weisberg, 2019). Esta función solo requiere como argumento el objeto en el que está el modelo a ser evaluado.
library(car)
leveneTest(fit_credit_limit)En este caso, el valor p permite rechazar la nula de una varianza homogénea. Es decir, no se cumple el supuesto de varianza homogénea según esta prueba. Ahora constatemos este resultado con otras dos pruebas de varianza constante: la prueba de Bartlett y la de Figner-Killeen. Las dos pruebas están implementadas en el paquete base de R, y se puede acceder por medio de las funciones bartlett.test() y fligner.test(), respectivamente. Estas dos funciones emplean como argumentos los mismos que empleamos para la función aov().
##
## Bartlett test of homogeneity of variances
##
## data: Avg_Credit_Limit by cluster
## Bartlett's K-squared = 31.198, df = 1, p-value = 2.33e-08##
## Fligner-Killeen test of homogeneity of variances
##
## data: Avg_Credit_Limit by cluster
## Fligner-Killeen:med chi-squared = 33.817, df = 1, p-value = 6.055e-09Las dos pruebas ratifican la conclusión de del test de Levene: el supuesto de varianza homogénea es violado.
De hecho, existe una alternativa para cuando hay una varianza no homogénea: la prueba de Welch de una vía (Welch one-way test). Esta prueba supone normalidad en los diferentes grupos.
##
## One-way analysis of means (not assuming equal variances)
##
## data: Avg_Credit_Limit and cluster
## F = 542.69, num df = 1.000, denom df = 51.945, p-value < 2.2e-16De acuerdo con esta prueba, es posible rechazar la hipótesis nula de que las medias son iguales. Pero de nuevo, es necesario comprobar si el supuesto de la prueba se cumple o no. Esta prueba supone normalidad, el cumplimiento o no de este supuesto se puede chequear por medio de un gráfico conocido como el gráfico Q-Q. Este grafica los cuantiles de los residuos, versus los cuantiles de la distribución normal. Si estos son iguales, deberían estar sobre la línea de 45 grados que se incluye en el gráfico.
Figura 4.19: q-q plot
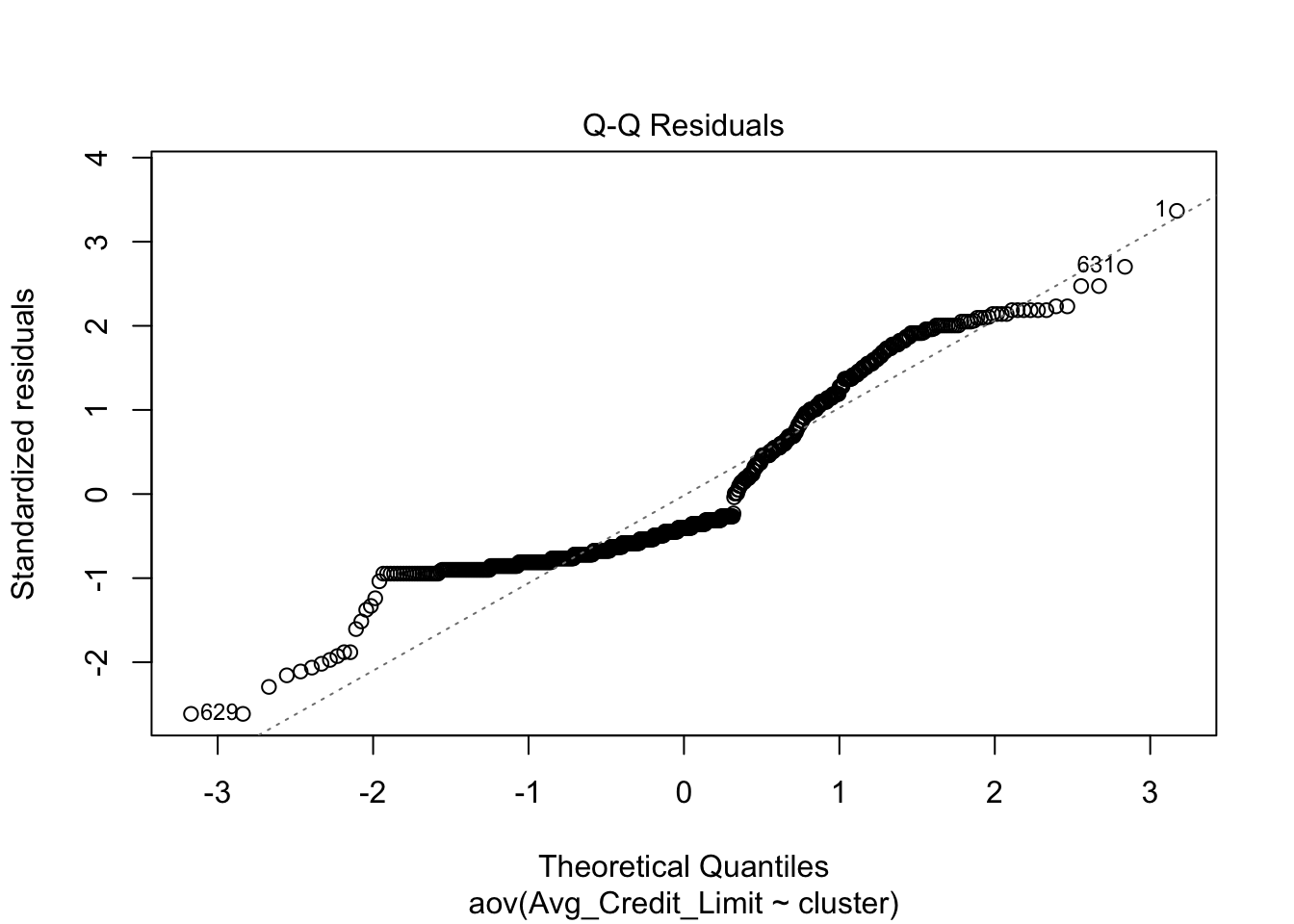
La Figura 4.19 muestra con puntos, para cada observación, el cuantil acumulado observado y el teórico si los datos provienen de una distribución normal. La observaciones están relativamente cerca de la línea punteada, lo cual es indicio de un comportamiento similar al de una distribución normal. Este gráfico muestra que los residuos no siguen una distribución normal. Las colas de la distribución de los residuos se alejan de la distribución normal. Pero la decisión final la deberíamos tomar con pruebas estadísticas. Empleemos la prueba de normalidad de Shapiro que se puede implementar con la función shapiro.test() del paquete base de R. Esta función requiere como único argumento los residuales del modelo.
##
## Shapiro-Wilk normality test
##
## data: fit_residuals
## W = 0.88844, p-value < 2.2e-16Esta prueba permite rechazar la hipótesis nula de normalidad. Así, las conclusiones no son válidas.
En estos casos existe una alternativa de prueba que no supone normalidad: la prueba de Kruskal-Wallis de suma de rangos (Kruskal-Wallis Rank Sum Test). La prueba de Kruskal-Wallis es un método no paramétrico que permite comprobar la hipótesis nula de que los datos de la muestra provienen de la misma población. Es decir, que no hay diferencia entre los grupos. Estrictamente hablando no es exactamente una comparación de medias, sino también una comparación de la distribución de origen. Esta prueba la podemos realizar con la función kruskal.test() de la base de R.
##
## Kruskal-Wallis rank sum test
##
## data: Avg_Credit_Limit by cluster
## Kruskal-Wallis chi-squared = 138.37, df = 1, p-value < 2.2e-16Esta prueba permite rechazar la hipótesis nula de que los datos de los dos clústeres vienen de la misma distribución.
Finalmente, otra opción es emplear una segunda prueba que no tiene supuestos. Se conoce como la prueba no paramétrica de Tukey. La prueba también es conocida como el método de Tukey (Tukey’s honest significance test, Tukey’s HSD (honest significant difference en inglés) test, o the Tukey-Kramer method). Esta prueba la podemos realizar con la función TukeyHSD() de la base de R.
## Tukey multiple comparisons of means
## 95% family-wise confidence level
##
## Fit: aov(formula = Avg_Credit_Limit ~ cluster, data = datos_con_segmentacion)
##
## $cluster
## diff lwr upr p adj
## 2-1 115192.5 108825.3 121559.6 0Esta prueba permite rechazar la hipótesis de que las medias son iguales.
En resumen, podemos concluir que el comportamiento del crédito aprobado para los dos clústeres es diferente. Las varianzas no son iguales, pero el uso de pruebas no paramétricas como la de Kruskal-Wallis permite concluir que las distribuciones no son iguales. La prueba no paramétrica de Tukey concluye que las medias son diferentes. Así, poniendo todos los resultados juntos, encontramos que las medias no son iguales.
Ustedes pueden realizar un ejercicio similar para las otras variables y encontrarán que, en efecto, el comportamiento de los dos clústeres construidos es diferente para cada una de las variables consideradas.
Referencias
La base de datos fue descargada del siguiente enlace: https://www.kaggle.com/datasets/aryashah2k/credit-card-customer-data?select=Credit+Card+Customer+Data.csv.↩︎
Los datos se pueden descargar de la página web del libro: http://www.icesi.edu.co/editorial/intro-clustering/. ↩︎
Para una introducción a este paquete se puede consultar Alonso & Largo (2023).↩︎
Algunos autores incorrectamente llaman a esto normalizar.↩︎
En la Sección 2.2 se discutieron todas las posibles formas que tomará la función \(d(x_i, x_j)\).↩︎
No se provee el código para esta visualización, ¡intenta reproducirla!↩︎
En este ejemplo no emplearemos los indices GAP, Gamma, Gplus y Tau por demandar mucho tiempo su cálculo. Puedes probar que el resultado cambian si incluyes estos 4 indicadores. ↩︎
En Alonso & Largo (2023) se puede encontrar una breve introducción a la creación de visualizaciones con el paquete ggplot2.↩︎
Por ejemplo, se puede ver la discusión en el siguiente enlace: https://community.rstudio.com/t/rstudio-error-with-fviz-nbclust-for-nbclust-results/176083/2.↩︎
Esta función tiene una pequeña modificación en el condicional para resolver el problema.↩︎
Este resultado lo podríamos también extraer del objeto
res_centroiden el compartimientoBest.nc.↩︎En nuestra notación \(q\).↩︎
Para una mayor detalle sobre este tema ver el capítulo 6 de Kaufman & Rousseeuw (2009). ↩︎
Un análisis completo debería incluir también un análisis para otras distancias y comparar las siluetas obtenidas.↩︎
En nuestra notación \(q\).↩︎