5 Modelo k-means
Objetivos del capítulo
Al finalizar este capítulo, el lector estará en capacidad de:
- Explicar en sus propias palabras la lógica detrás de la construcción de un clúster empleando el algoritmo k-means.
- Construir en R clústeres empleando el algoritmo k-means.
5.1 Introducción
Como se discutió en el Capítulo 1, los algoritmos de clústering particionado construyen grupos en los que cada individuo pertenece a solo uno de ellos y el número de clústeres es solo uno. Esto difiere de los algoritmos jerárquicos que estudiamos en el Capítulo 3. Sin importar si se trata de un HCA AGNES o DIANA, cada individuo puede pertenecer a múltiples grupos, dependiendo del punto de la construcción del algoritmo; en este caso los clústeres se sobreponen. En los algoritmos jerárquicos, el número de conglomerados cambia a medida que se construye el árbol jerárquico y se debe seleccionar el número de clústeres óptimo.
En este capítulo nos concentraremos en desarrollar un tipo de clústering particionado, que es intuitivo y computacionalmente no muy costoso. Como se mencionó en el Capítulo 1, el clústering particionado es una forma de conformar los grupos que son mutuamente excluyentes; es decir, subconjuntos de individuos que no se sobreponen, como se presenta en la Figura 5.1.
Figura 5.1: Representación de un algoritmo de clústering empleando k-means

En este capítulo estudiaremos el algoritmo k-means, que es un algoritmo de aprendizaje de máquina (machine learning)58. Con seguridad, este es uno de los algoritmos más populares y, a su vez, sencillo.
5.2 La intuición
Como cualquier otra técnica de clústering, la idea principal detrás del algoritmo de k-means es dividir los individuos en k grupos de tal manera que los puntos dentro de cada grupo sean lo más similares posible entre sí y lo más diferentes posible de los puntos de otros grupos. La peculiaridad de esta aproximación es que va construyendo iterativamente los grupos al minimizar la suma de las distancias al cuadrado de cada punto al centroide más cercano. Intuitivamente, el centroide es un punto medio de todos los individuos que pertenecen a un grupo (Ver Figura 5.1).
Para entender la intuición de este algoritmo, veamos los pasos para realizar un clústering particionado, usando el algoritmo k-means para un determinado número de clústeres \(k\):
Elegir aleatoriamente \(k\) centroides a partir de los datos disponibles.
Calcular las distancias de cada observación a los centroides.
Agrupar individuos al centroide más cercano.
Recalcular el centroide usando la media aritmética59.
Agrupar de nuevo al centroide más cercano.
Repetir los pasos 4 y 5 hasta que no se produzca ningún cambio en la asignación de las individuos a los clústeres o se alcance un número máximo de iteraciones.
El algoritmo k-means, al igual que los jerárquicos estudiados hasta ahora, solo funciona para variables (features) cuantitativas. Y cómo ya lo vimos en el Capítulo 3, para no ver afectado el análisis de clústering por la escala de las variables, se emplean variables estandarizadas.
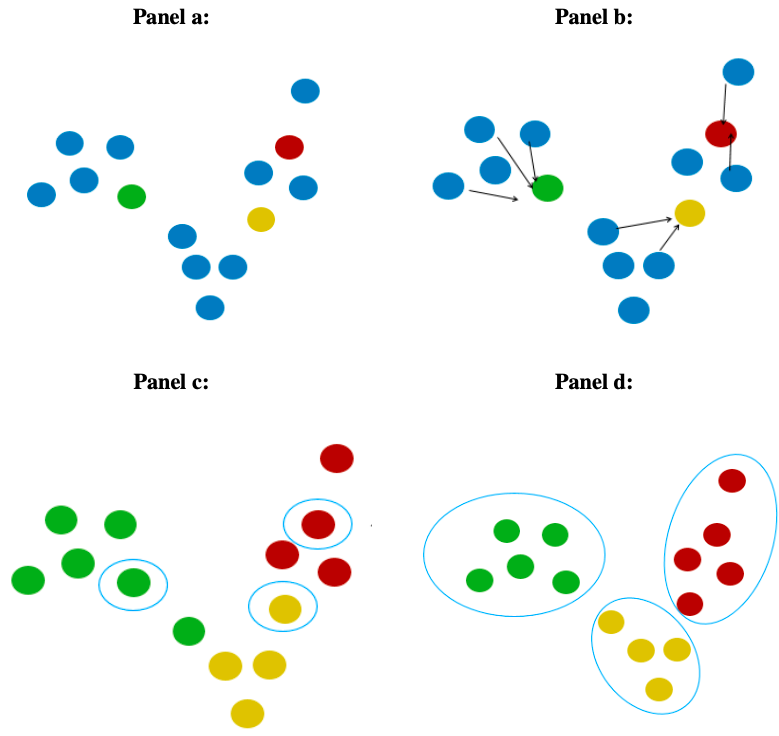
El algoritmo de k-means inicia seleccionando \(k\) centroides al azar, donde \(k\) 60 es el número de grupos que queremos conformar, algo como el panel a de la Figura 5.2. Cada color es un centroide elegido al azar.
Luego se calcula la distancia de cada individuo a los centroides (panel b de la Figura 5.2) y se asigna al centroide más cercano, conformando los clústeres (panel c de la Figura 5.2).
A continuación, se calcula la media aritmética al interior de cada clúster, siendo esta media el nuevo centroide. Se repite el respectivo cálculo de distancia al nuevo centroide, así como la asignación de cada observación al grupo.
Esto se desarrolla de manera iterativa hasta que ya no se cambien de grupo los individuos o hasta cierto número de iteraciones que se definan arbitrariamente. Al final, el objetivo es llegar a algo como lo que se presenta en el panel d de la Figura 5.2.
Figura 5.2: Algoritmo k-means
5.3 Detalle técnico del algoritmo k-means
Matemáticamente, para asignar cada individuo a su centroide más cercano se quiere minimizar la suma de las distancias cuadráticas a las medias. Formalmente,
\[\begin{equation} \min_{s} \sum_{i=1}^k \sum_{x_j \in S_i} ||x_j-\bar x_i||^2 \end{equation}\]
donde \((x_1,x_2,x_3...x_n)\) son las observaciones de \(d\) dimensiones, \(k\) es el número de grupos a formar y \(S= {S_1,S_2,..,S_k}\) es la suma de los cuadrados dentro de cada grupo. Para actualizar el centroide en la siguiente iteración (\(t+1\)) se emplea la siguiente expresión:
\[\begin{equation} \bar x_i^{(t+1)}= \frac{1}{|S_i^{(t)}|} \sum_{x_j \in S_i^{(t)}} x_j \end{equation}\]
El algoritmo termina cuando los individuos no cambian de clúster entre iteraciones. En la siguiente sección, desarrollaremos un ejemplo de clústering particionado usando k-means en R.
5.4 k-means en R
Para implementar el algoritmo de k-means en R, emplearemos los mismos paquetes que hemos empleado hasta ahora. Es decir,
- factoextra (Kassambara & Mundt, 2020)
- cluster (Maechler et al., 2022)
- NbClust (Charrad et al., 2014)
Carguemos nuevamente los paquetes.
Para realizar el ejemplo práctico, continuaremos con la base de datos de clientes de tarjeta de crédito que empleamos en el Capítulo 4. (Ver detalles de cada uno de los pasos para construir la base de datos en el Capítulo 4). Carga el working space que guardaste en el Capítulo 4.
Nuestro objetivo continua siendo emplear los datos para responder la pregunta de negocio: Con el fin de mejorar la satisfacción del cliente, brindar una atención más personalizada a los clientes y optimizar el gasto en mercadeo, ¿cómo segmentamos a nuestros clientes?
De pronto te estarás preguntando ¿por qué tendremos que construir clústeres con el algoritmo k-means si ya lo hicimos con el algoritmo jerárquico? La razón es muy sencilla. No sabemos si este algoritmo puede proveer “mejores” agrupaciones. Así, el científico de datos siempre está en la obligación de probar la mayor cantidad de aproximaciones y usar métricas para determinar cuál aproximación se ajusta a los datos empleados. En otras palabras, hasta no crear conglomerados con este método no podremos saber si era “mejor” emplear la aproximación jerárquica.
En la práctica, el algoritmo k-means se emplea para diferentes valores de \(k\) y después se selecciona el número óptimo de clústeres \(q\) comparando el comportamiento de las agrupaciones para cada uno de los posibles \(k\) considerados. Es decir, en este caso corremos el algoritmo para diferentes valores de \(k\) y luego seleccionamos entre las diferentes corridas del modelo (uno para cada \(k\)). En el caso de los modelos jerárquicos existe una diferencia grande que puede parecer sutil. En los modelos jerárquicos, el algoritmo se corre una sola vez (una sola vez para DIANA o para AGNES con el respectivo método aglomerativo) y al interior del árbol que se generó escogemos dónde cortar el árbol. En la práctica, tanto en el HCA como en el algoritmo k-means tendremos que seleccionar el “mejor” número de grupos, aún cuando la naturaleza de la selección es algo diferente.
Es decir, la tarea de seleccionar el número óptimo de clústeres \(q\) implica correr el algoritmo de k-means para diferentes \(k\) (número de clústeres) y comparar esas aproximaciones. Como lo discutimos en la Sección 2.4, podemos tener varias aplicaciones. De manera similar al Capítulo 4, emplearemos dos aproximaciones: una batería de métricas y la silueta promedio. A continuación, miraremos ambas aproximaciones.
5.4.1 Empleando batería de métricas
Evaluaremos entre 2 y 10 clústeres formados por el algoritmo k-means, usando 26 indicadores61 que empleamos en el Capítulo 4. De manera similar a lo realizado en el Capítulo anterior, esto lo podemos realizar con el paquete NbClust (Charrad et al., 2014) empleando la función NbClust().
La diferencia, en este caso, con respecto a los algoritmos de clústering jerárquicos que empleamos en el Capítulo 4, es que el argumento method debe establecerse como “kmeans”. La función calcula los pasos mencionados en la sección anterior, es decir, asigna al azar los centroides, calcula distancias, agrupa y repite iterativamente hasta conformar los grupos finales.
Adicionalmente, empleemos la distancia euclidiana, pero recuerden que existen otras distancias. Empleando los datos estandarizados (objeto datos_est), el siguiente código permitirá escoger el número óptimo de clústeres con los 26 indicadores62:
# Crear una semilla para que los centroides
# aleatorios siempre sean los mismos
# intenten diferentes semillas
set.seed(12345)
res_kmeans<-NbClust(datos_est, distance = "euclidean",
min.nc = 2, max.nc = 10,
method = "kmeans", index = "all") Veamos cuál es el mejor número de clústeres según las 26 métricas empleando la función fviz_nbclust() del paquete factoextra(Kassambara & Mundt, 2020) que empleamos en el capítulo anterior. Recuerda que si obtienes un mensaje de error, puedes emplear la función nueva_fviz_nbclust(). Procedamos a visualizar los resultados con el siguiente código (Ver Figura 5.3):
# cargamos el paquete
library(factoextra)
# visualizando las métricas
fviz_nbclust(res_kmeans) + theme_minimal()
# nueva_fviz_nbclust(res_kmeans) + theme_minimal()
## Entre todos los índices:
## ===================
## * 2 proponen 0 como el mejor número de clústeres
## * 1 proponen 1 como el mejor número de clústeres
## * 1 proponen 2 como el mejor número de clústeres
## * 20 proponen 3 como el mejor número de clústeres
## * 1 proponen 6 como el mejor número de clústeres
## * 1 proponen 10 como el mejor número de clústeres
##
## Conclusión
## =========================
## * De acuerdo con la mayoría, el mejor número de clústeres es is 3 .Figura 5.3: Votación de la batería de métricas por el número óptimo de clústeres para el algoritmo k-means y distancia euclidiana
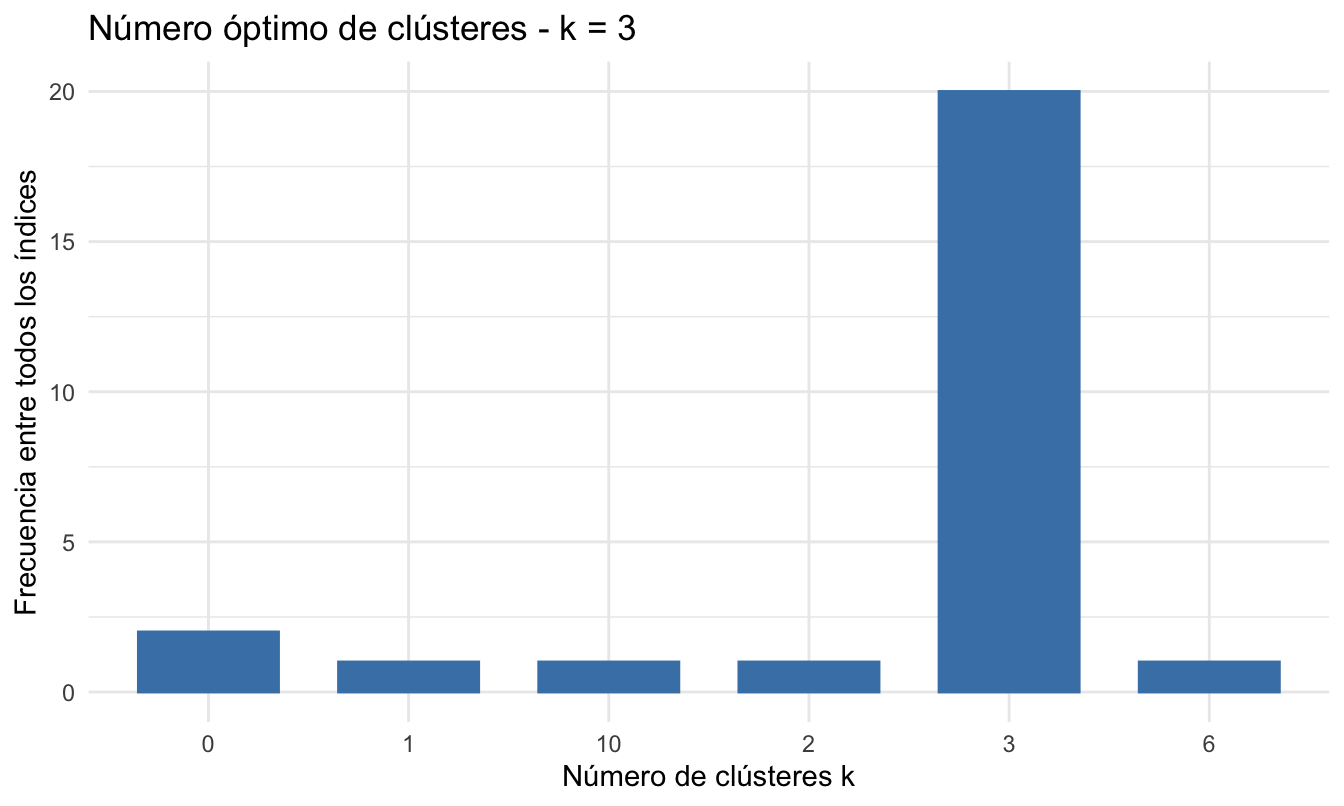
De acuerdo con los resultados de la Figura 5.3, 20 de los 26 métodos sugieren 3 clústeres, mientras que 2 índices sugieren no usar grupos.
5.4.2 Empleando Silueta promedio
Ahora usemos el coeficiente de silueta promedio para comparar los resultados del clústering. Al igual que en el Capítulo 4, podemos emplear la función NbClust() con el argumento index = “silhouette” (recuerda emplear la misma semilla nuevamente para asegurarte de tener el mismo resultado). También podrías extraer el resultado del número de clústeres óptimo que ya está en el objeto res_kmeans.
Otra opción, que no habíamos explorado es emplear la función fviz_nbclust() del paquete factoextra para visualizar la silueta promedio para diferentes \(k\) que ya se encuentran en el objeto res_kmeans. Por ejemplo, el siguiente código genera la Figura 5.4:
set.seed(12345)
fviz_nbclust(datos_est, kmeans, method = "silhouette", k.max = 10) +
theme_minimal() + ggtitle("Coeficiente de silueta")
## Entre todos los índices:
## ===================
## * 2 proponen 0 como el mejor número de clústeres
## * 1 proponen 1 como el mejor número de clústeres
## * 1 proponen 2 como el mejor número de clústeres
## * 20 proponen 3 como el mejor número de clústeres
## * 1 proponen 6 como el mejor número de clústeres
## * 1 proponen 10 como el mejor número de clústeres
##
## Conclusión
## =========================
## * De acuerdo con la mayoría, el mejor número de clústeres es is 3 .Figura 5.4: Silueta promedio para diferente número de clústeres para el algoritmo k-means y distancia euclidiana
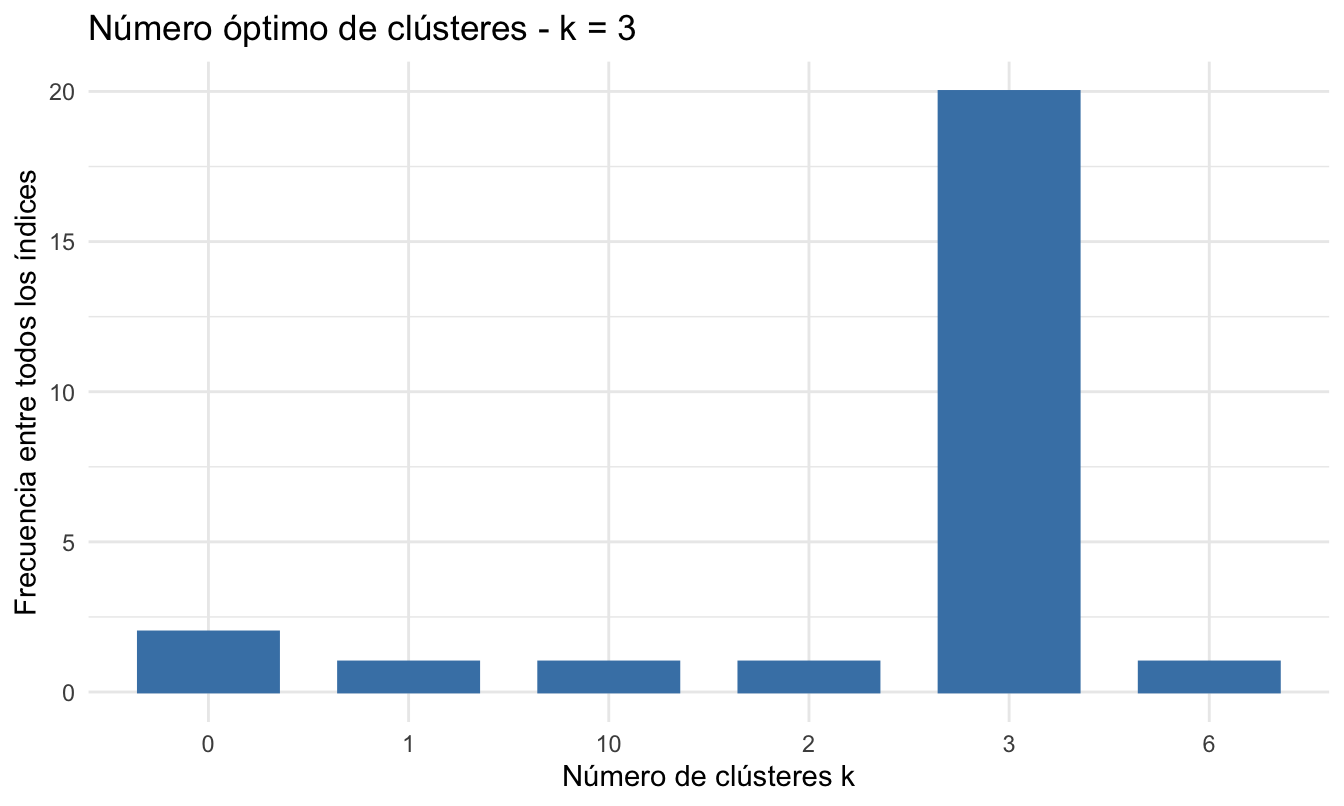
No importa la aproximación que sigamos, encontramos que el número de grupos sugeridos por la silueta promedio es 3 con una silueta promedio de 0.5157.
| Método de aglomeración | Silueta promedio | Número óptimo de clústeres |
|---|---|---|
| Enlace único | 0.3758 | 3 |
| Enlace completo | 0.5703 | 2 |
| Enlace promedio | 0.5703 | 2 |
| Enlace mediano | 0.3022 | 6 |
| Centroide | 0.5703 | 2 |
| Ward.D | 0.5157 | 3 |
| Ward.D2 | 0.5148 | 3 |
| McQuitty | 0.5703 | 2 |
| k-means | 0.5157 | 3 |
| Fuente: cálculos propios. |
Noten que la silueta promedio del método de k-means no es la más grande (Ver Cuadro 5.1). El mejor modelo sigue siendo el de centroide, cuyos resultados son iguales a los de enlace completo, enlace promedio y McQuitty. No obstante este resultado, por razones pedagógicas, continuaremos ilustrando cómo se pueden extraer las membrecías a los grupos si se emplea el algoritmo de k-means.
Antes de continuar, guarda tu espacio de trabajo. Lo emplearemos en los siguientes capítulos.
5.4.3 Siluetas individuales y membrecía para el algoritmo k-means
Después de conocer el número óptimo de clústeres, podemos aplicar el algoritmo k-means para continuar con nuestro análisis, similar a lo que presentamos en la Sección 4.7. La función que usaremos para implementar el algoritmo es kmeans() de la base de R. Esta función requiere, en su forma más simple, un objeto de clase data.frame con los datos (x) y el número de clústeres que queremos formar (centers). Es decir, el código será
# fijamos la semilla aleatoria
set.seed(12345)
# calculamos los clústeres para k = 3
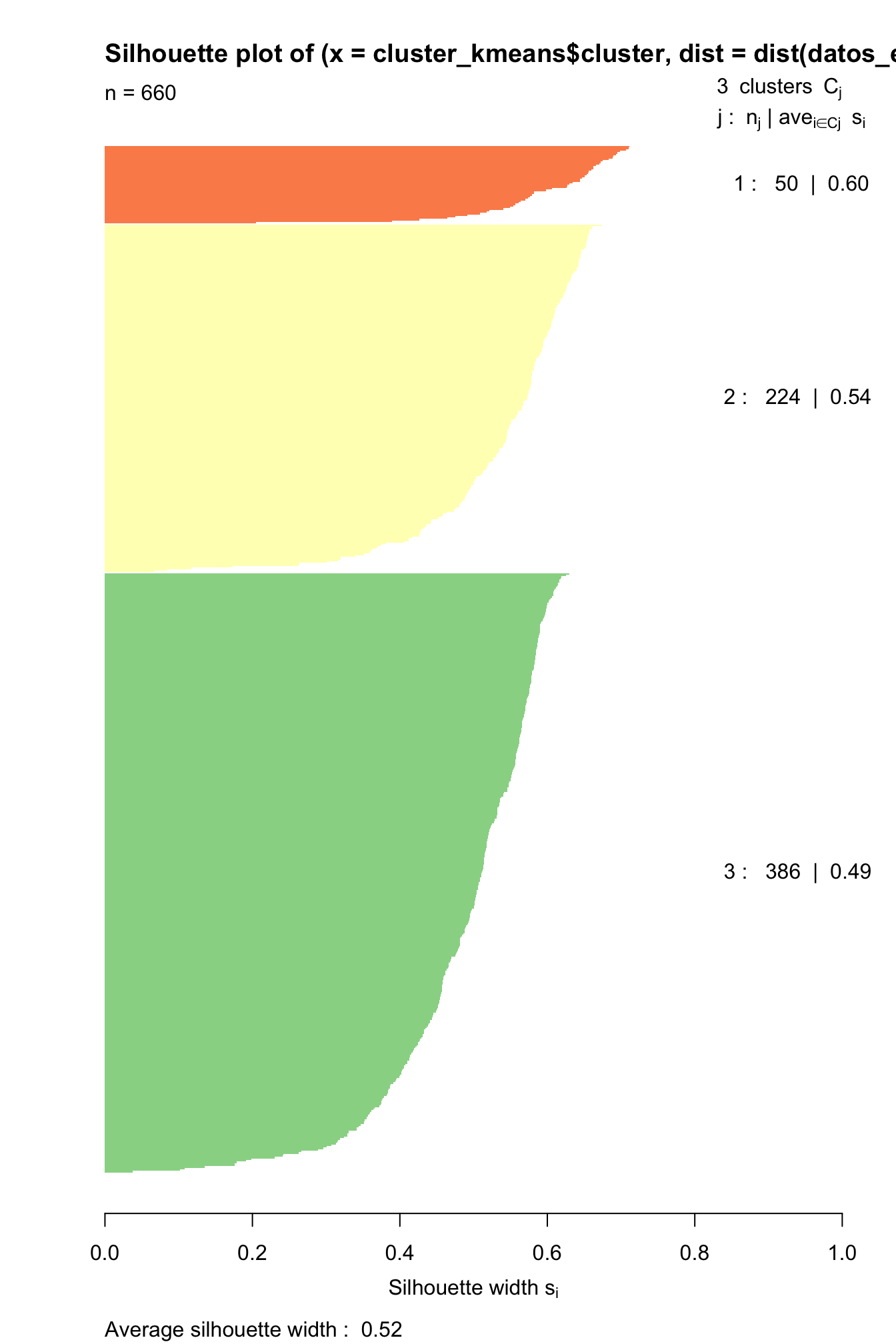
cluster_kmeans <- kmeans(x = datos_est, centers = 3)
# Mirar todos los comportamientos del objeto creado
attributes(cluster_kmeans)## $names
## [1] "cluster" "centers" "totss" "withinss" "tot.withinss"
## [6] "betweenss" "size" "iter" "ifault"
##
## $class
## [1] "kmeans"El objeto que creamos con el algoritmo k-means (en este caso cluster_kmeans) tiene varios compartimientos (slots) entre los cuales podemos destacar:
- cluster: Un vector con números enteros (de 1 a \(k\)) que corresponde a la membrecía de cada observación. Es decir, el clúster al que se asigna cada dato.
- centers: Una matriz con los centros de cada clúster.
- size: El número de observaciones en cada clúster.
Por ejemplo, podemos saber el número de clientes en cada uno de los dos clústeres de la siguiente manera:
## [1] 50 224 386Es decir, en el primer clúster tenemos 50 clientes. Las membrecías de todos los clientes las podemos extraer fácilmente de la siguiente manera:
Empleemos este resultado para construir las siluetas individuales. Recuerda que en la Figura 5.4 se presenta la silueta promedio para cada \(k\). Si queremos visualizar el gráfico de siluetas individuales para tres clústeres conformados por el algoritmo de k-means, podemos emplear las membrecías que encontramos anteriormente y la función silhouette() del paquete cluster (Maechler et al., 2022):
Figura 5.5: Silueta para tres clústeres emplendo k-means y distancia euclidiana
Continuando con el análisis de resultados, como en el Capítulo 4, guardemos las membrecías de todos los clientes en el objeto grupos_kmeans con el siguiente código:
Rápidamente, comparemos las agrupaciones que produce el algoritmo k-means con la obtenida en el HCA con el método del centroide.
## grupos_HCA_aglo
## grupos_kmeans 1 2
## 1 0 50
## 2 224 0
## 3 386 0Nota que este método está manteniendo a los mismos clientes en un clúster (clúster 2 en la aproximación jerárquica y clúster 3 en el de k-means), la diferencia se presenta en el clúster 1 del método jerárquico que es dividido en dos clústeres (clúster 1 y clúster 2) en el método de k-means. Ya discutimos que parece más adecuada la clasificación encontrada en por el HCA. Recuerda que esto cambiará dependiendo de los datos que se empleen.
5.5 k-means++
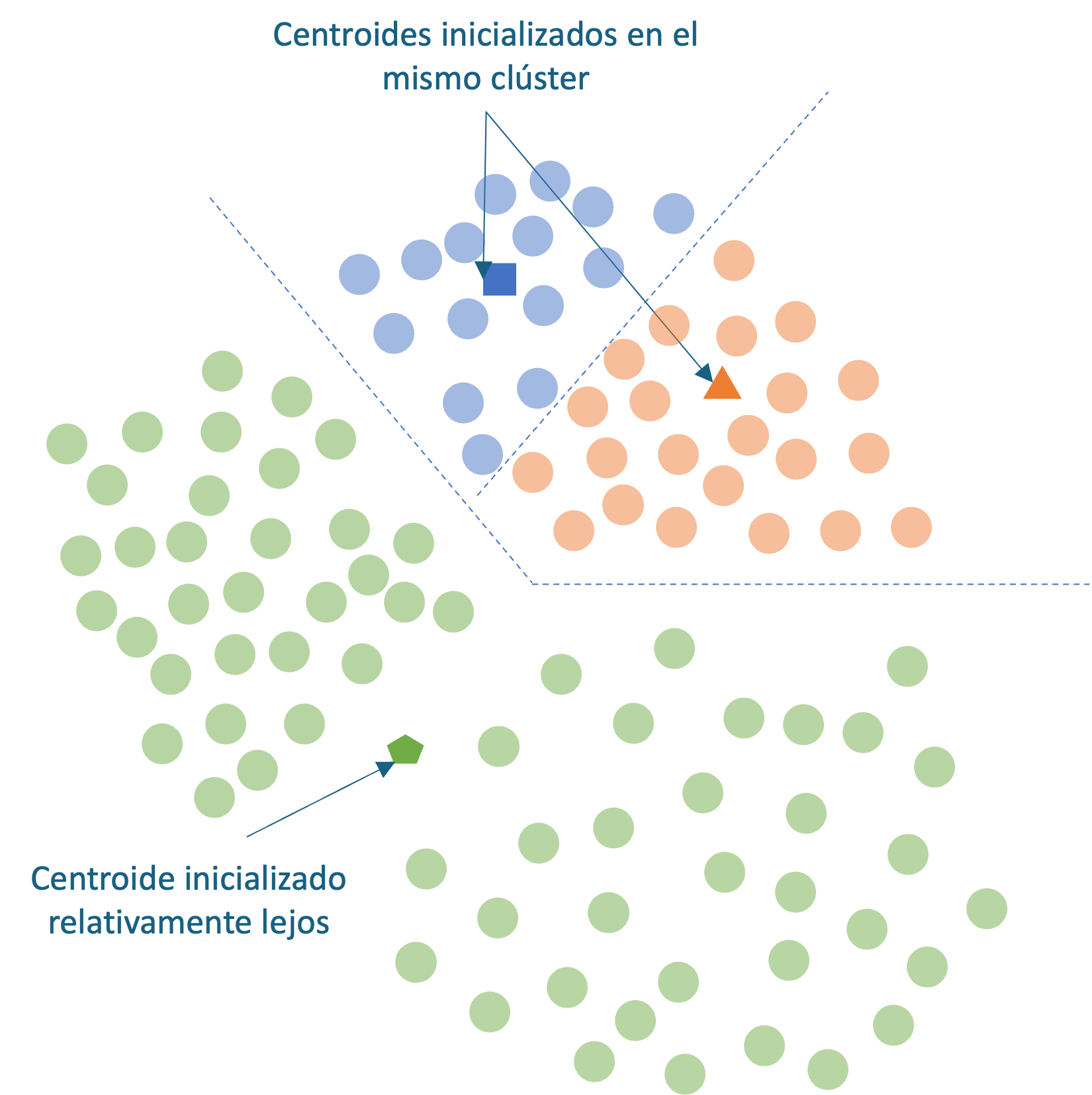
Antes de estudiar estos otros métodos, es importante reconocer que una desventaja del algoritmo k-means es que es sensible a la “inicialización” de los centroides. Es decir, de la elección aleatoria original de los centroides. Si aletaoriamente se selecciona como centroide un punto relativamente “lejano”, puede acabar sin puntos asociados a él y, al mismo tiempo, más de un clúster puede acabar vinculado a un único centroide. Del mismo modo, más de un centroide podría inicializarse en el mismo clúster, lo que daría lugar a una agrupación deficiente (Ver grupos Figura 5.6).
De esta manera, por una mala inicialización de los centroides (al azar), obtenemos como resultado una partición inadecuada de los datos (compara la mala partición de las Figuras 5.6 con la presentada en la Figura 5.1).
Figura 5.6: Centroides inicializados incorrectamente (al azar)
Arthur et al. (2007) proponen una solución para este problema que se conoce con el nombre de k-means++. La propuesta es inicializar de manera “más inteligente” el algoritmo k-means.
Este algoritmo inicia, como el k-means, seleccionando aleatoriamente \(k\) centroides de los datos. Posteriormente, para cada individuo se calcula su distancia al centroide más cercano. En el siguiente paso se encuentra la diferencia entre los dos algoritmos. El siguiente paso será seleccionar el siguiente centroide, de tal forma que la probabilidad de elegir un punto como centroide sea directamente proporcional a su distancia al centroide más cercano elegido anteriormente. Es decir, el punto que se encuentra a la máxima distancia del centroide más cercano tiene más probabilidades de ser seleccionado como centroide. Una vez se establece este nuevo conjunto de centroides, se asignan de nuevo los individuos a cada centroide y se recalculan otros centroides siguiendo la metodología para el paso anterior. Y se continúa el algoritmo hasta que los grupos se estabilicen.
Noten que en esta aproximación se escogen centroides que están lejos unos de otros. Esto aumenta las posibilidades de arrancar con centroides que se encuentran en diferentes clústeres.
En últimas, el algoritmo k-means++ es el mismo algoritmo k-means combinado con una inicialización más inteligente de los centroides. Este algoritmo es más lento que el k-means y es más sensible a datos con una separación poco clara63.
Este algoritmo se puede emplear en R empleando la función kmeanspp() del paquete maotai (You, 2023). Esta función solo necesita los datos estandarizados (argumento data) y establecer el número de clústeres (argumento k).
Puedes explorar esta función. Desacertadamente, no podemos emplear este algoritmo con la función NbClust() del paquete NbClust (Charrad et al., 2014) para automatizar la búsqueda del número óptimo de clústeres. Si decides emplear este algoritmo, tendremos que calcular la silueta promedio para cada número de clústeres a “mano”. En este libro no emplearemos esta aproximación.
5.6 Comentarios Finales
Por último, es importante mencionar que en este caso los dos algoritmos (el de este capítulo y el del capítulo anterior) no se pusieron de acuerdo en cuanto al número de clústeres. En algunos casos, los algoritmos se pueden poner de acuerdo con el número de clústeres, pero no la conformación de cada grupo. Una buena práctica es comparar por medio de métricas los resultados de uno y de otro tipo de algoritmos para elegir la mejor partición de los datos.
Adicionalmente, solo hemos empleado una medida de similitud (la distancia euclidiana). En la práctica es importante realizar el ejercicio con las diferentes distancias (que tengan sentido para la pregunta de negocio) y comparar los resultados empleando, por ejemplo, la silueta o las métricas estudiadas en la sección 2.4.
Por otro lado, no olvidemos que estas aplicaciones toman sentido para el negocio, en la medida en que obtenemos conclusiones de este tipo de análisis. Siempre podemos intentar asignarle nombres a cada clúster, que permiten un mejor entendimiento para luego tomar las decisiones necesarias con esta información.
En este caso, estudiamos una forma de clústering que es el particionado, y usando k-means. Sin embargo, hay otros algoritmos particionados que se aproximan de diferente manera a la construcción de los clústeres. En los próximos capítulos estudiaremos otros métodos de clústering particionado.
Referencias
Más específicamente, un algoritmo de aprendizaje no supervisado.↩︎
El nuevo centroide de un clúster se calcula como el promedio de las distancias de todos los individuos que pertenecen a ese clúster (distancias intra-clúster).↩︎
En los capítulos anteriores hemos denominado el número de clústeres óptimo con \(q\) y cualquier número de grupos con \(k\). Este algoritmo se conoce como k-means, dado que \(k\) es el número de clústeres.↩︎
En este ejemplo no emplearemos los indices GAP, Gamma, Gplus y Tau por demandar mucho tiempo su cálculo. Puedes probar que el resultado no cambia si incluyes estos cuatro indicadores. ↩︎
Es importante recordar que el algoritmo k-means tiene, en su primera iteración, un componente aleatorio. Es decir, se parte de unos centroides aleatorios. Para evitar que cada vez que se corra el algoritmo cambien los resultados, es importante usar la función set.seed() . En otras palabras, si queremos obtener los mismos resultados es importante fijar una semilla aleatoria.↩︎
En la jerga de los científicos de datos se le denomina a esta situación como datos con mucho ruido.↩︎