3 Clústering Jerárquico
Objetivos del capítulo
Al finalizar este capítulo, el lector estará en capacidad de:
- Explicar en sus propias palabras la lógica detrás de la construcción de un clúster jerárquico aglomerativo (AGNES).
- Explicar en sus propias palabras qué son los métodos de aglomeración.
- Explicar en sus propias palabras la lógica detrás de la construcción de un clúster jerárquico de división (DIANA).
3.1 Introducción
Los algoritmos jerárquicos para la construcción de clústeres tienen un origen en la estadística. Como se mencionó en el Capítulo 2, los algoritmos de clústering jerárquicos construyen subconjuntos de clústeres organizados jerárquicamente como un árbol (ver Figura 2.3), siguiendo un método o criterio de aglomeración33. Los grupos resultantes de un algoritmo jerárquico por construcción no son mutuamente excluyentes; es decir, se sobreponen.
Existen dos tipos de clústeres jerárquicos: aglomerativo y de división. El algoritmo de clústering jerárquico aglomerativo implica comenzar suponiendo que cada individuo es un clúster y se van formando (aglomerando) grupos según su proximidad. Estos algoritmos son conocidos por la sigla HAC (del inglés Hierarchical Agglomerative Clustering), la sigla AGNES (del inglés AGlomerative NESting) o también con el nombre de aproximación de abajo hacia arriba (bottom-up).
Por otro lado, el clústering jerárquico de división empieza suponiendo que todos los individuos hacen parte de un único grupo y el algoritmo empieza a dividir los clústeres según la disimilitud entre sus componentes. Estos últimos algoritmos son también conocidos como algoritmos top-down o por la sigla DIANA (del inglés DIvise ANAlysis). En la Sección 3.2 estudiaremos la intuición detrás del clústering jerárquico aglomerativo, que es de los más empleados en la práctica. Posteriormente, en la Sección 3.4 discutiremos la intuición del clústering jerárquico de división. En el Capítulo 4 estudiaremos cómo aplicar estos conceptos en R.
Antes de continuar, recordemos que en el capítulo pasado habíamos discutido que para agrupar individuos, el proceso de clústering implica:
- Seleccionar una medida de similitud para determinar qué tan parecidos son los individuos al interior de los grupos y qué tan diferentes entre grupos.
- Un algoritmo para formar los clústeres.
- Un criterio para determinar el número óptimo de clústeres.
En este Capítulo nos concentraremos en algoritmos de clústering jerárquico (aglomerativo y de división). Las medidas de similitud fueron discutidas en la Sección 2.2. Así mismo, emplearemos los diferentes criterios para determinar el número de clústeres fueron discutidos en la Sección 2.4.
3.2 La intuición de los métodos aglomerativos
Para los métodos de clústering aglomerativos, no solo es necesario seleccionar una medida de similitud y un criterio para determinar el número óptimo de clústeres. Adicionalmente, será necesario escoger un criterio o método de aglomeración. Esto se discutirá en la sección 3.3.
En general, después de seleccionar una medida de similitud y un método de aglomeración, los pasos para construir conglomerados jerárquicos son:
- Calcular una matriz de proximidad (o distancias).
- Iniciar con cada individuo siendo un clúster.
- Unir los dos clústeres más cercanos.
- Actualizar la matriz de proximidad.
- Repetir 3 y 4 hasta que solo quede un clúster.
Para entender el funcionamiento del algoritmo de construcción de clústeres jerárquicos empleemos un ejemplo. Supongamos que contamos con cinco clientes y tenemos sus compras del año pasado en millones de dólares. La pregunta de negocio que queremos responder es: ¿cuántos tipos de clientes podemos identificar en los datos de tal manera que podamos segmentarlos y focalizar nuestras actividades de mercadeo? Es decir, nuestra tarea es construir grupos de clientes para hacer una segmentación. Para hacer el ejemplo más sencillo, supongamos que solo contamos con una variable (característica) de los consumidores: el valor de sus compras el año pasado. En el Cuadro 3.1 se presentan los datos.
| Individuo (\(i\)) | Compras (Millones de pesos) (\(x_{1,i}\)) |
|---|---|
| 1 | 10 |
| 2 | 7 |
| 3 | 28 |
| 4 | 20 |
| 5 | 35 |
| Fuente: datos ficticios. |
El primer paso para la construcción de este tipo de clústeres es calcular una matriz de proximidad (o distancias). Esta matriz contiene la distancia entre cada uno de los puntos de los casos (observaciones). Por tanto, es una matriz cuadrada (igual número de filas que de columnas) y simétrica, donde cada fila representa a cada una de las observaciones al igual que cada columna representa una observación. Para construir esta matriz de distancias es importante seleccionar una medida de distancia. Como se discutió en el Capítulo 2, existen diferentes medidas de similitud. Por simplicidad, supongamos que empleamos la distancia euclidiana. Recuerda que por simplicidad hemos supuesto que solo contamos con una variable para realizar la tarea de clusterización. Es decir, \[\begin{equation} x=\begin{bmatrix} x_1 \end{bmatrix} \tag{3.1} \end{equation}\] y la distancia euclidiana entre los individuos \(i\) y \(j\) estará dada por: \[\begin{equation} d(x_i, x_j)= \sqrt{\left ( x_{1,i}- x_{1,j} \right )^2} \tag{3.2} \end{equation}\]
Ahora, procedamos con el primer paso. Calculemos la correspondiente matriz de proximidad34. Por ejemplo, en la primera fila segunda columna tendremos la distancia entre las ventas del cliente 1 y el 2 que se calcula de la siguiente manera: \[\begin{equation*} d(x_1, x_2)= \sqrt {(10- 7)^2}=3 \end{equation*}\] De manera similar obtenemos la matriz de proximidad35 reportada en el Cuadro 3.2.
| i | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 1 | 0 | 3 | 18 | 10 | 25 |
| 2 | 3 | 0 | 21 | 13 | 28 |
| 3 | 18 | 21 | 0 | 8 | 7 |
| 4 | 10 | 13 | 8 | 0 | 15 |
| 5 | 25 | 28 | 7 | 15 | 0 |
| Fuente: cálculos propios. |
En el algoritmo, el segundo paso es iniciar con cada individuo como un clúster. El tercer paso es unir los puntos más “cercanos”.
En este caso, según las distancias reportadas en el Cuadro 3.2, la mínima distancia corresponde a los individuos 1 y 2 (resaltado en rojo). Es decir, estos individuos corresponden al primer clúster. Esto lo podemos visualizar en un gráfico conocido como dendrograma (Ver Figura 3.1). Típicamente, en el eje horizontal de un dendrograma se muestran las etiquetas de las observaciones que se están agrupando y en el eje horizontal la distancia (disimilitud) entre las observaciones o grupos. Esta visualización tiene forma de árbol, dada la naturaleza jerárquica del algoritmo. En el árbol, cada nodo representa los “puntos” en que se unen dos grupos y las ramas muestran la relación entre los clústeres.
Figura 3.1: Dendrograma para el clúster aglomerativo- Paso 1
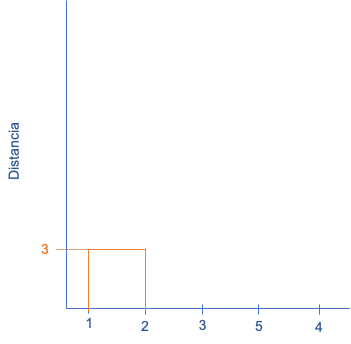
El cuarto paso es actualizar la matriz de proximidad. Para esto tenemos que considerar el clúster formado por el individuo 1 y 2 como si fuera una sola observación. En otras palabras, estos dos puntos representan un conglomerado. Para esto necesitamos un criterio de construcción de los conglomerados (Criterio de aglomeración), más explícito que el que habíamos usado hasta ahora. Es decir, cómo tratar los grupos que se van formando36. Por ejemplo, empleemos el valor mínimo de los individuos que componen el nuevo clúster como el valor del clúster en la matriz de valores originales37. La tabla actualizada para las compras de los clientes será como se reporta en el Cuadro 3.3.
| Individuo (\(i\)) | Compras (Millones de pesos) (\(x_{1,i}\)) |
|---|---|
| 1-2 | 7 |
| 3 | 28 |
| 4 | 20 |
| 5 | 35 |
| Fuente: datos ficticios. |
La nueva matriz de proximidad se reporta en el Cuadro 3.4.
| i | 1-2 | 3 | 4 | 5 |
|---|---|---|---|---|
| 1-2 | 3 | 0 | 21 | 13 |
| 3 | 21 | 0 | 8 | 7 |
| 4 | 13 | 8 | 0 | 15 |
| 5 | 28 | 7 | 15 | 0 |
| Fuente: cálculos propios. |
Los dos clústeres38 más cercanos son los individuos 3 y 5. Esto lo podemos visualizar con un dendrograma (ver Figura 3.2).
Figura 3.2: Dendrograma para el clúster aglomerativo- Paso 2
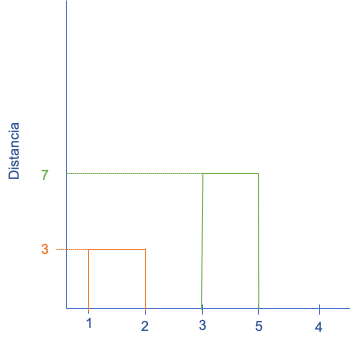
Procedamos a actualizar las compras de los clientes (Cuadro 3.5) y la matriz de proximidad (Cuadro 3.6).
| Individuo (\(i\)) | Compras (Millones de pesos) (\(x_{1,i}\)) |
|---|---|
| 1-2 | 7 |
| 3-5 | 28 |
| 4 | 20 |
| Fuente: datos ficticios. |
| i | 1-2 | 3-5 | 4 |
|---|---|---|---|
| 1-2 | 0 | 21 | 13 |
| 3-5 | 21 | 0 | 8 |
| 4 | 13 | 8 | 0 |
| Fuente: cálculos propios. |
Ahora, los dos conglomerados más cercanos son el conformado por los individuos 3 - 5 y el individuo 4. Esto lo podemos representar en el dendrograma (ver Figura 3.3).
Figura 3.3: Dendrograma para el clúster aglomerativo- Paso 3
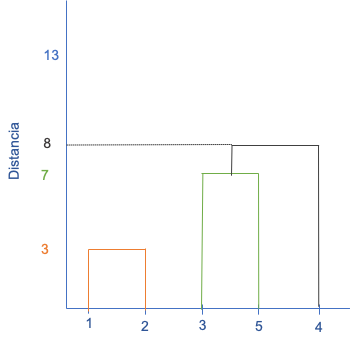
Actualicemos nuevamente las compras de los clientes (Cuadro 3.7) y la matriz de proximidad (Cuadro 3.8).
| Individuo (\(i\)) | Compras (Millones de pesos) (\(x_{1,i}\)) |
|---|---|
| 1-2 | 7 |
| 3-5-4 | 20 |
| Fuente: datos ficticios. |
| i | 1-2 | 3-5-4 |
|---|---|---|
| 1-2 | 0 | 13 |
| 3-5-4 | 13 | 0 |
| Fuente: cálculos propios. |
Ahora, los dos clústeres más cercanos conformarían el grupo padre con todas las observaciones. Esto permite completar nuestro dendrograma (Ver Figura 3.4). Recuerda que la altura del nodo nos muestra la distancia entre los clústeres que se fusionan en ese punto y la longitud de la rama indica la similitud entre los conglomerados que se fusionan. De esta manera, el dendrograma (completo) es un buen resumen de los pasos de este algoritmo aglomerativo.
Figura 3.4: Dendrograma para el clúster aglomerativo- Paso 4
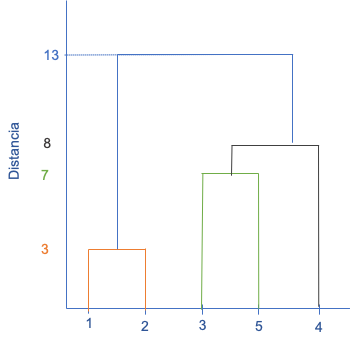
Finalmente, se debe emplear algún criterio para determinar el número de conglomerados. Normalmente, los dendrogramas sugieren el número de clústeres en cada paso, pero ¿dónde cortar?
Existen dos opciones. Emplear un procedimiento heurístico39 que implica que los árboles son cortados por inspección subjetiva en diferentes niveles. Como el proceso es exploratorio, en algunos casos no existirá mucho problema si esta elección se hace de manera subjetiva. La otra opción es empleando métricas o siluetas como se discutió en el capítulo anterior.
En el Capítulo 4 veremos cómo realizar un proceso de clústering jerárquico aglomerativo en R (R Core Team, 2023). Antes de continuar, veamos las diferentes maneras en que podemos aglomerar las observaciones en este tipo de algoritmos jerárquicos.
3.3 Métodos de aglomeración
Los métodos de agregación (o aglomeración) corresponden a las formas como el algoritmo jerárquico de agrupamiento va incluyendo a cada individuo en un grupo de manera iterativa.
Una idea natural (la que seguimos en nuestro ejemplo intuitivo) es emplear la distancia más pequeña entre las observaciones de los clústeres. Este criterio de aglomeración es conocido como enlace único (Single linkage en inglés). En este caso, la distancia40 entre dos clústeres \(C_{i}\) y \(C_ {j}\) (la denominaremos \(D_{i,j}\)) será la distancia más pequeña encontrada entre un individuo del grupo \(i\) y otro del clúster \(j\). Es decir, si definimos a \(x\) como un vector que contiene las \(d\) características (variables que se incluyen para las construcciones de los conglomerados) de un individuo del clúster \(i\) (\(x \in C_{i}\)) y \(y\) como uno del clúster \(C_{j}\) (\(y \in C_j\)), entonces este criterio implica: \[\begin{equation} D_ {i,j} = \min_{x \in C_{i}, y \in C_ {j}} d(x, y) \tag{3.3} \end{equation}\] En el panel a de la Figura 3.5 se presenta una representación de esta aproximación.
Figura 3.5: Representación esquemática de los métodos de aglomeración
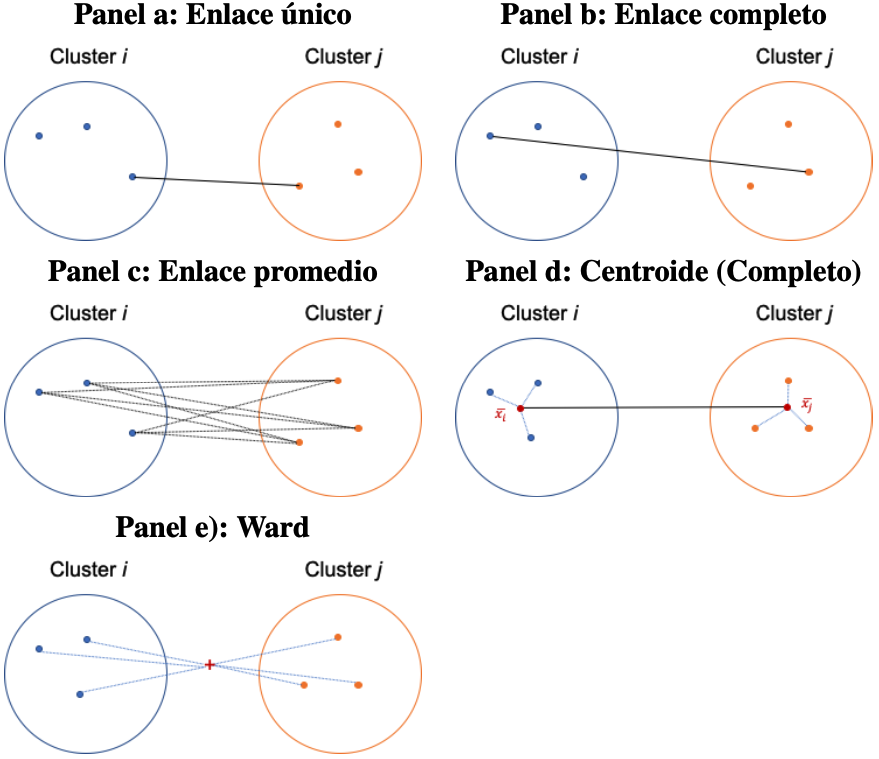
Un inconveniente de este método es que los grupos tienden a no diferenciarse mucho (a juntarse), debido a que los elementos individuales están cerca unos de otros, aunque muchos de los elementos de cada clúster pueden estar muy distantes entre sí. A este fenómeno se le conoce en la literatura como el fenómeno de encadenamiento.
Este problema lleva a pensar que una solución es emplear la distancia máxima y no la mínima. Este método se conoce como enlace completo (Complete linkage en inglés) (Ver panel b de la Figura 3.5). En otras palabras, \[\begin{equation} D_{i.j} = max_{x \in C_{i}, y \in C_ {j}} d(x, y) \tag{3.4} \end{equation}\]
Una alternativa a los dos métodos anteriores es emplear la distancia promedio (método de enlace promedio ) (Ver panel c de la Figura 3.5). Formalmente, \[\begin{equation} D_{i.j} = \frac{\sum_{\forall x \in C_{i}, \forall y \in C_ {j}} d(x, y)}{n_i \cdot n_j} \tag{3.5} \end{equation}\] donde \(n_ {i}\) y \(n_ {j}\) representan el número de elementos en el clúster \(i\) (\(C_ {i}\)) y clúster \(j\) (\(C_ {j}\)).
Este método tiene la tendencia a formar grupos con la misma varianza y típicamente varianzas pequeñas. Otro método similar a este es emplear la mediana en vez de la media. Este es el método de enlace mediano.
El método del centroide define la distancia entre dos clústeres como el cuadrado de la distancia euclidiana entre los centros de gravedad de los dos grupos; es decir, entre los vectores que contienen las medias de los dos grupos (\(\bar{x_{i}}\) y \(\bar{x_j}\)) (Ver panel d de la Figura 3.5). En otras palabras, \[\begin{equation} D_{i,j} = \left \| \bar{x_{i}} - \bar{x_j} \right \|^2 \tag{3.6} \end{equation}\] Una ventaja de este método es su robustez frente a la presencia de individuos (observaciones) atípicos.
Un criterio que se aparta un poco de los anteriores es el de Ward (Ward Jr, 1963) . Este criterio tiene como premisa minimizar la varianza total dentro del grupo. En cada paso se fusionan el par de clústeres con una distancia mínima de grupos (Ver panel e de la Figura 3.5).
Murtagh & Legendre (2014) proponen una modificación del criterio de Ward Jr (1963) que implica elevar al cuadrado la diferencia encontrada antes de la actualización del grupo. A este método lo llamaremos Ward.D2 y al de Ward Jr (1963) WarddD.
Otro método es el conocido como McQuitty, que implica emplear una media ponderada de las diferencias al interior de los conglomerados (intraclúster). Es decir, \[\begin{equation} D_{i,j} = \frac{D_i,k + D_i,l} {2} \tag{3.7} \end{equation}\] donde el clúster \(C_ {j}\) se forma a partir de la agregación de los clústeres \(C_{k}\) y \(C_{l}\).
En la práctica, es imposible saber cuál de estos cinco métodos de aglomeración generará grupos más plausibles para unos datos determinados. Por eso es común que se intenten diferentes métodos de aglomeración en combinación con diferentes distancias para determinar, por medio de métricas o de las siluetas, el mejor número de conglomerados.
3.4 La intuición de los métodos de división
A diferencia de los algoritmos aglomerativos, que inician considerando a cada uno de los individuos como un posible clúster, este algoritmo se inicia con un único conglomerado que contiene todas las observaciones. El algoritmo implica generar divisiones sucesivas hasta que cada observación forma un grupo independiente. En otras palabras, a diferencia de los métodos aglomerativos que construyen conglomerados de manera ascendente (bottom-up), DIANA sigue un enfoque descendente (top-down).
En el algoritmo DIANA, en cada iteración se selecciona el grupo con mayor diámetro. El diámetro de un clúster se define como la distancia más grande entre dos puntos dentro del clúster (distancia intraclúster). Nota que la distancia puede ser cualquiera de las definidas en la Sección 2.2. Una vez seleccionado el conglomerado de mayor diámetro, se identifica la observación más dispar, que es aquella con mayor distancia promedio respecto al resto de observaciones que forman el clúster. Esta observación inicia el nuevo grupo. Se reasignan las observaciones en función de si están más próximas al nuevo grupo o al resto de la partición, dividiendo así el clúster seleccionado en dos nuevos clústeres.
A diferencia del clústering aglomerativo, en el que hay que elegir un tipo de distancia y un método de aglomeración (linkage), en DIANA solo hay que elegir la distancia, no hay método de aglomeración .
Regresemos a nuestro ejemplo. Partamos de la matriz de proximidad que se presenta en el Cuadro 3.1. Recuerda que, en ese caso, tenemos solo una variable y estamos empleando la distancia euclidiana.
El primer paso del algoritmo DIANA es identificar la observación más dispar. En nuestro ejemplo, la disparidad de cada cliente corresponde a la distancia promedio entre las compras de dos clientes dentro del clúster inicial conformado por todas las observaciones (\(C_0\)). Noten que para cada cliente tenemos que la disparidad promedio es:
- Cliente 1: (3 + 18 + 10 + 25)/4 = 14
- Cliente 2: (3 + 21 + 13 + 28)/4 = 16.25
- Cliente 3: (18 + 21 + 8 + 7)/4 = 13.5
- Cliente 4: (10 + 13 + 8 + 15)/4 = 11.5
- Cliente 5: (25 + 28 + 7 + 15)/4 = 18.75
En este caso la máxima disparidad corresponde al cliente 5, quien será seleccionado para “liderar” el nuevo clúster. Hasta ahora tendríamos un clúster con el cliente 5 y otro con los clientes de 1 a 4. Para encontrar otro cliente que se unirá al cliente 5 en un grupo, calculamos para cada cliente su disparidad promedio al interior del grupo grande (el conformado por los clientes de 1 a 4) y lo comparamos con la distancia de cada uno de esos clientes con respecto al otro clúster (en este caso el cliente 5 únicamente).
Es decir, tendremos:
- Cliente 1: La disparidad promedio es igual a (3 + 18 + 10)/3 = 10.33. Y la diferencia de la disparidad promedio y la distancia al cliente del otro grupo es de: 10.33 - 25 = -14.67.
- Cliente 2: La disparidad promedio es igual a (3 + 21 + 13 )/3 = 12.33. Y la diferencia de la disparidad promedio y la distancia al cliente del otro grupo es de: 12.33 - 28 = -15.67.
- Cliente 3: La disparidad promedio es igual a (18 + 21 + 8 )/3 = 15.67. Y la diferencia de la disparidad promedio y la distancia al cliente del otro grupo es de: 15.67 - 7 = 8.67.
- Cliente 4: La disparidad promedio es igual a (10 + 13 + 8 )/3 = 10.33. Y la diferencia de la disparidad promedio y la distancia al cliente del otro grupo es de: 10.33 - 15 = -4.67.
En promedio, el cliente 3 es el que más alejado está de los otros clientes de este grupo, al tener una diferencia en la disparidad promedio y la distancia al cliente del otro grupo positiva y más grande (8.67). Así crearemos en este paso inicial dos clústeres, \(C_1\) y \(C_2\). El \(C_1\) formado por los clientes 5 y 3 y otro clúster \(C_2\) con los clientes 1, 2 y 4.
Noten que ahora podemos repetir los cálculos realizados anteriormente para los clientes del grupo \(C_2\) para ver si podemos mover más clientes al grupo \(C_1\). Los resultados se presentan en el Cuadro 3.9.
| i | Disparidad promedio en el clúster | Disparidad promedio al otro clúster | Diferencia |
|---|---|---|---|
| 1 | (3 + 10)/2 = 6.5 | (18 + 25)/2 = 21.5 | -15 |
| 2 | (3 + 13)/2 = 8 | (21 + 28)/2 = 24.5 | -16.5 |
| 4 | (18 + 21)/2 = 19.5 | (8 + 15)/2 = 11.5 | 8 |
| Fuente: cálculos propios. |
En este caso aún tenemos un cliente (el Cliente 4) que es muy diferente a su grupo (diferencia positiva y grande). Así que podemos mover al Cliente 4 al clúster \(C_1\). Y repetimos el procedimiento con los clientes que quedan en el grupo \(C_2\).
| i | Disparidad promedio en el clúster | Disparidad promedio al otro clúster | Diferencia |
|---|---|---|---|
| 1 | 3 | (18 + 10 + 25)/3 = 17.67 | -14.67 |
| 2 | 3 | (21 + 13 + 28)/3 = 20.67 | -17.67 |
| Fuente: cálculos propios. |
Ahora, todos los clientes del \(C_2\) tienen una diferencia negativa con el clúster \(C_1\). Es decir, se parecen más al conglomerado 2 que al 1. Por tanto, no necesitamos mover a más clientes entre grupos. Ahora podemos pasar a la siguiente iteración.
Trabajemos ahora con el clúster \(C1\) que es el del diámetro más grande (diámetro de 15 frente a 3 del \(C_2\)). En los Cuadros 3.11 y 3.12 se presentan las matrices de proximidad para los dos clústeres que tenemos hasta ahora.
| i | 3 | 4 | 5 |
|---|---|---|---|
| 3 | 0 | 8 | 7 |
| 4 | 8 | 0 | 15 |
| 5 | 7 | 15 | 0 |
| Fuente: cálculos propios. |
| i | 1 | 2 |
|---|---|---|
| 1 | 0 | 3 |
| 2 | 3 | 0 |
| Fuente: cálculos propios. |
Ahora repliquemos el procedimiento anterior al \(C_1\). Primero busquemos el cliente más diferente al interior de este clúster empleando la disparidad promedio más grande (Ver Cuadro 3.13).
| Cliente | Disparidad promedio en el clúster |
|---|---|
| 3 | (8 + 7)/2 =7.5 |
| 4 | (8 + 15)/2 =11.5 |
| 5 | (7 + 15)/2 =11 |
| Fuente: cálculos propios. |
De acuerdo con estos resultados, el cliente 4 puede conformar el nuevo clúster (\(C_3\)). Ahora miremos cuál otro cliente se le puede unir en el nuevo clúster. En el Cuadro 3.14 vemos que todas las diferencias son negativas.
| Cliente | Disparidad promedio en el clúster | Disparidad promedio al otro clúster | Diferencia |
|---|---|---|---|
| 3 | 7 | 8 | -1 |
| 5 | 7 | 15 | -8 |
| Fuente: cálculos propios. |
Así, podemos dar por terminado este paso. Es decir, por ahora tenemos tres clústeres:
- \(C_1\): Clientes 3 y 5.
- \(C_2\): Clientes 1 y 2.
- \(C_3\) Cliente 4.
En la siguiente iteración buscaremos el grupo con el diámetro más grande (el \(C_1\)) y en la tercera iteración estaríamos trabajando con el \(C_2\), hasta que terminamos con clústeres de un solo elemento.
Este ejemplo te permite entender la intuición detrás del algoritmo jerárquico de división. Si deseas conocer el detalle técnico detrás de DIANA puedes consultar el capítulo 6 de Kaufman & Rousseeuw (2009).
3.5 Comentarios finales
En este Capítulo, hemos discutido dos tipos de algoritmos para construir grupos de carácter jerárquicos. Los algoritmos aglomerativos que parten de suponer que cada uno de los individuos es un clúster y empleando un método aglomerativo41 y una medida de distancia42, se empiezan a conformar conglomerados de individuos.
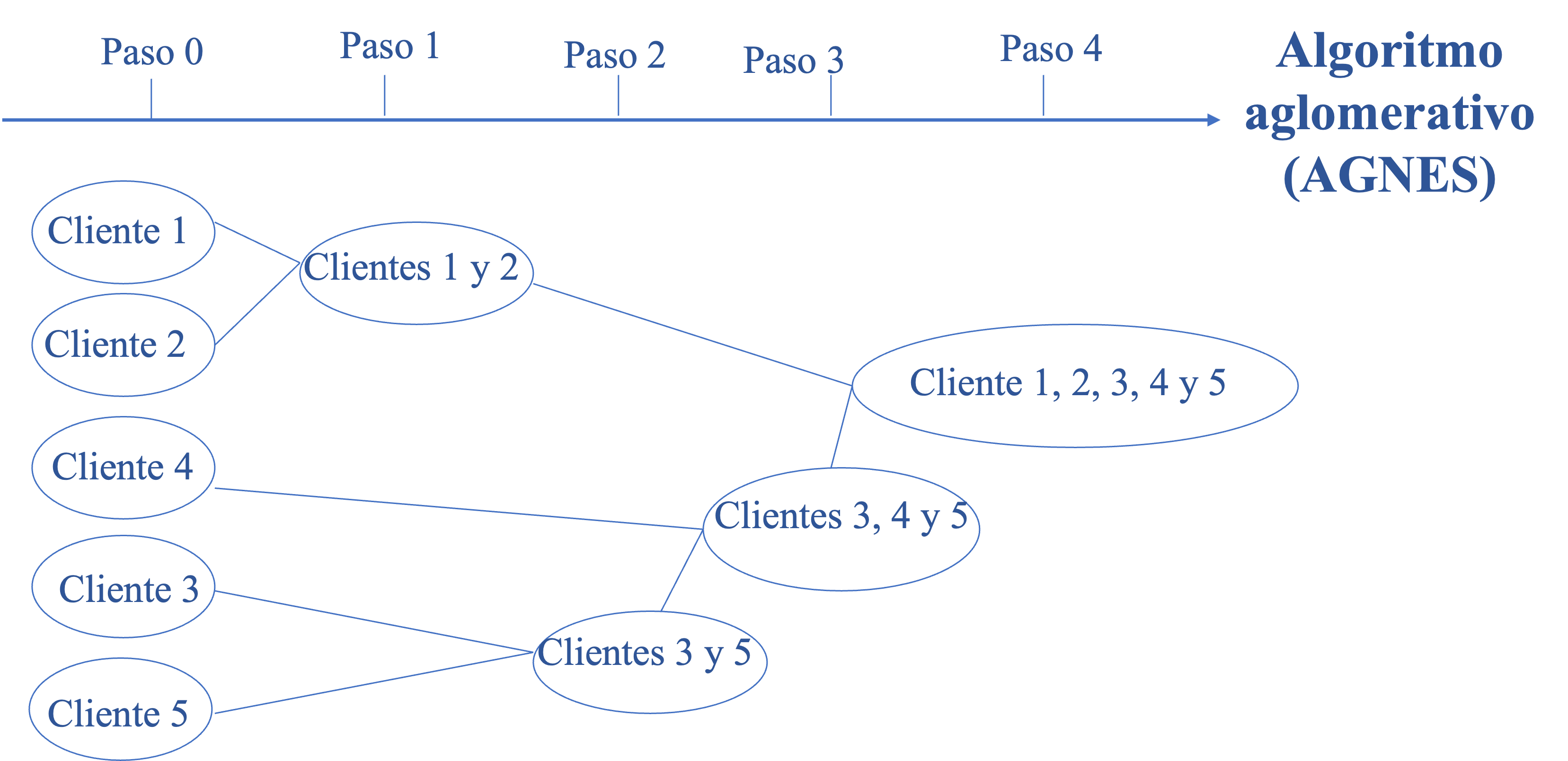
Para ilustrar los algoritmos jerárquicos aglomerativos (AGNES), empleamos un ejemplo en el que usamos el método de aglomeración de enlace único (Single linkage) y la distancia euclidiana. En la Figura 3.6 se presentan los pasos que realizamos en nuestro ejemplo para construir los clústeres.
Figura 3.6: Pasos del ejemplo empleando el algoritmo aglomerativo (AGNES)
En general, es importante recordar que en los AGNES debemos escoger uno de los siguientes 8 métodos de aglomeración:
- Enlace único (Single linkage),
- Enlace completo (Complete linkage),
- Enlace promedio,
- Enlace mediano,
- Centroide,
- Ward.D,
- Ward.D2, y
- McQuitty.
Adicionalmente, es importante escoger una medida de distancia de las siguientes:
- Distancia euclidiana
- Mahalanobis
- Manhattan
- Minkowski
Es decir, en la práctica podremos comparar diferentes AGNES que empleen diferentes algoritmos de aglomeración y medidas de similitud.
En este Capítulo también consideramos los algoritmos jerárquicos de división (DIANA). En este caso, no es necesario escoger un método de aglomeración pero si una medida de distancia. Los DIANA parten de un clúster con todos los individuos y van dividiendo a los individuos en grupos, hasta llegar al punto en que todos los individuos representan un clúster aparte.
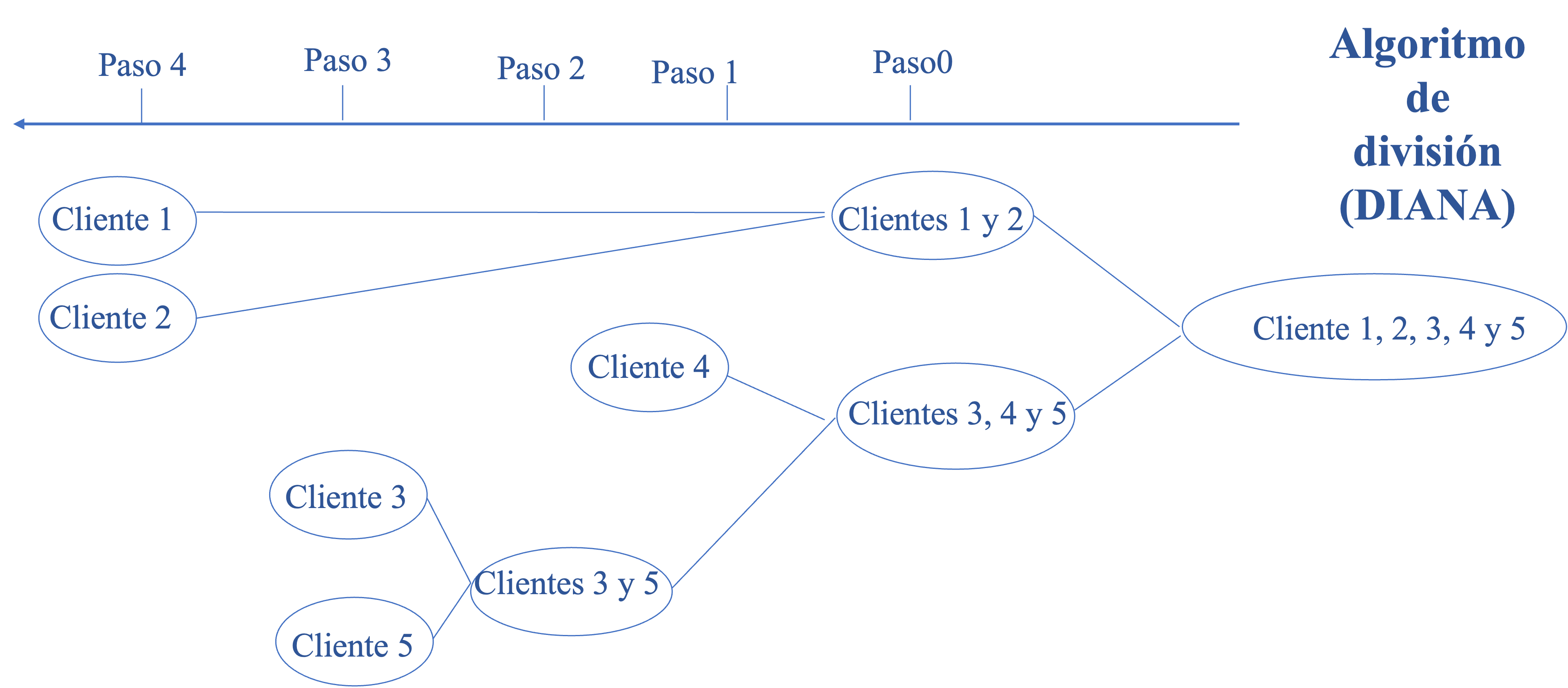
En nuestro ejemplo, empleamos la distancia euclidiana para construir los clústeres de manera jerárquica, como se representa en la Figura 3.7.
Figura 3.7: Pasos del ejemplo empleando el algoritmo de división (DIANA)
En nuestros dos ejemplos (AGNES y DIANA) construimos todos los clústeres posibles. Recuerden que en la práctica debemos escoger el número óptimo de grupos (como lo discutimos en el Capítulo 2). En este Capítulo no nos encargamos de ese paso esencial, pues enfatizamos en cómo funciona cada una de estas filosofías de métodos jerárquicos de clústering. En el Capítulo 4 estudiaremos la forma de implementar estos algoritmos en R (R Core Team, 2023) y cómo escoger el número óptimo de conglomerados.
Antes de continuar al siguiente capítulo es importante mencionar que el análisis de clúster empleando métodos jerárquicos también es conocido con la sigla HCA del inglés Hierarchical Cluster Analysis.
Referencias
Es decir, una forma de ir agrupando los individuos a los clústeres.↩︎
Noten que no estamos estandarizando los datos, esto lo haremos porque solo contamos con una variable. Pero en la práctica es indispensable hacer la estandarización si se emplea más de una variable.↩︎
La matriz de proximidad es una matriz cuadrada con tantas filas (y columnas) como observaciones se tengan. Cada celda de la matriz de proximidad tendrá el calculo de la correspondiente distancia de los individuos de la columna \(i\) y fila \(j\) (\(d(x_i, x_j)\)).↩︎
En la sección 3.3 se discuten los diferentes métodos de aglomeración.↩︎
Podríamos haber empleado otros criterios como el máximo, la mediana u otro. En la sección 3.3 se discuten los diferentes métodos de aglomeración.↩︎
Recuerden que en el primer paso establecimos que cada observación individual sería un clúster.↩︎
En la ciencia de datos el término heurístico se emplea en el mismo sentido que en la ingeniería. Es decir, una heurística es una aproximación que emplea la experiencia como ayuda para resolver un problema.↩︎
Esta distancia puede ser cualquiera de las discutidas en la sección 2.2.↩︎
Los métodos considerados fueron: enlace único (Single linkage), enlace completo (Complete linkage), enlace promedio, enlace mediano, centroide, Ward, y McQuitty. ↩︎
Las medidas de distancia que estudiamos fueron: distancia euclidiana, Mahalanobis, Manhattan, y Minkowski. ↩︎