1 Introducción
Objetivos del capítulo
Al finalizar este capítulo, el lector estará en capacidad de:
- Explicar en sus propias palabras los elementos necesarios para construir clústeres.
- Explicar en sus propias palabras las distancias más comunes que se emplean en la construcción de clústeres.
1.1 Introducción
El Business Analitycs es el proceso científico de transformar datos en insights (conclusiones) con el propósito de tomar mejores decisiones. El Business Analitycs recoge un conjunto de herramientas de la estadística y de inteligencia artificial que nos permiten emplear datos para responder una pregunta de negocio planteada. Las técnicas se pueden clasificar de acuerdo con la finalidad de los cálculos que se realizan, en las siguientes tareas:
- Clasificar4.
- Estimar regresiones5.
- Detectar anomalías.
- Clusterizar (Agrupar).
- Encontrar reglas de asociación (o buscar coocurrencia de productos)6
- Pronosticar
- Resumir
- Visualizar7
La tarea de clusterizar (clústering o agrupar) implica encontrar grupos de elementos, lo más similares posibles, al mismo tiempo que los grupos son lo más diferente posibles entre ellos. La Figura 1.1 muestra de manera esquemática esta tarea. Partiendo de una muestra de individuos que no tienen ninguna “marca” (label en inglés) que los distinga o los asigne a un grupo, el modelo de clústering generará grupos de tal manera que los individuos al interior del grupo son muy parecidos, pero entre grupos muy diferentes.
Figura 1.1: Tarea de clústering
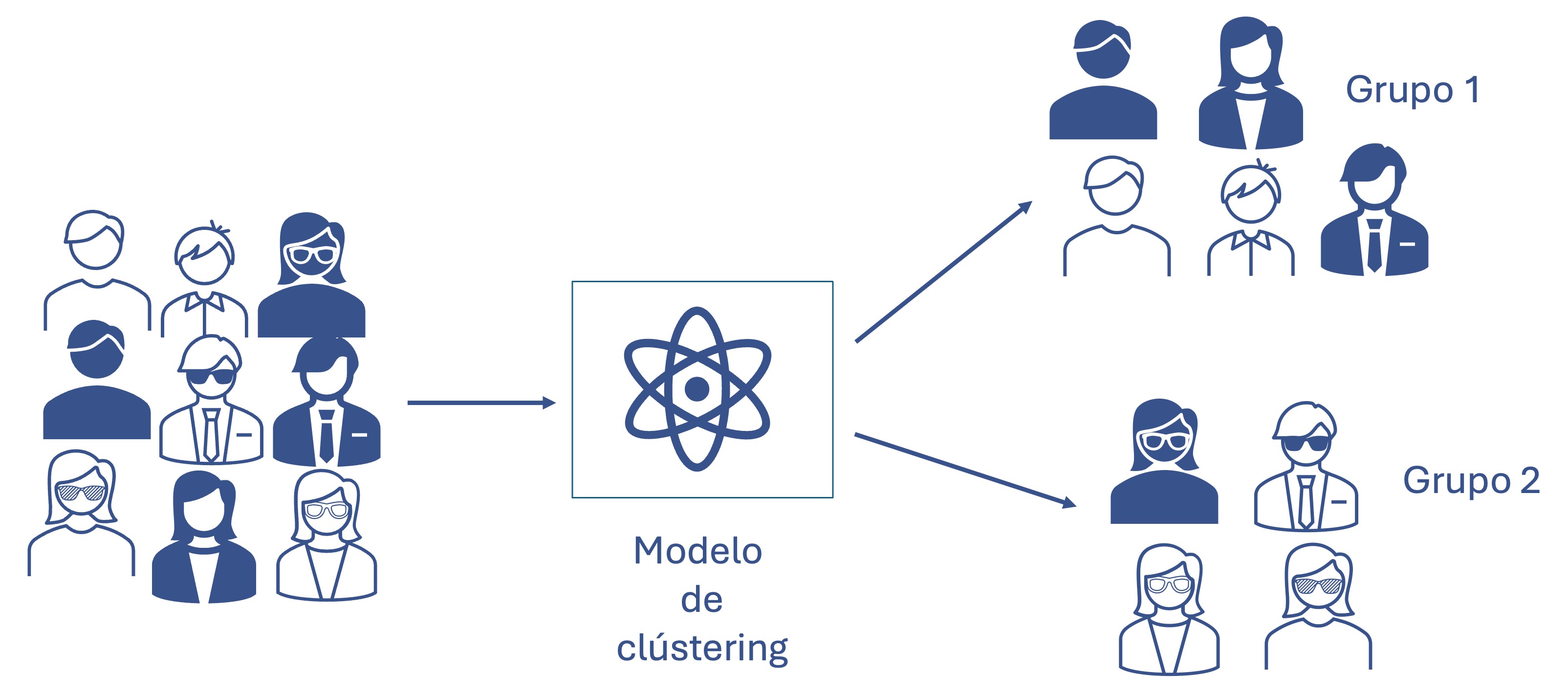
Figura 1.2: Material multimedia: tarea de clústering

Para realizar las diferentes tareas de analítica empleamos modelos o algoritmos8. En el ejemplo de la Figura 1.1, el modelo de clústering encuentra dos grupos: los que tienen gafas y los que no. A los grupos o conjuntos de individuos se les puede denominar de manera intercambiable como: conglomerados, clases, grupos o clústeres.
La creación de grupos (clústering) es bastante útil en el mundo de los negocios. Por ejemplo, en el mercadeo es una herramienta vital para la construcción de la estrategia y las decisiones tácticas. Supongamos que se tienen mil clientes, lo que hace muy difícil gerenciar a cada cliente de manera diferente. Pero cuando se arman grupos de clientes (clústeres de clientes) esto permite concentrarse en ellos de manera diferente. Dicho de otra forma, esto permite entender cómo se comportan los miembros de la población empleando conjuntos de individuos similares, tarea que es mucho más sencilla que intentar entender el comportamiento individual. A esto se le conoce como segmentación de clientes.
A través del clústering, las organizaciones pueden optimizar la calidad de los mensajes que envían al público, como promociones de productos con mayor poder de adquisición o un servicio posventa acorde con la última compra. Esto refuerza la relación con los clientes y, en consecuencia, aumenta las ventas y la fidelidad con las marcas.
Otra aplicación del clústering la podemos encontrar en el sector de venta al por menor y en el comercio electrónico. En estos sectores un reto importante es ser asertivo en la distribución de los productos. El clústering puede ayudar a resolver este reto: empleando datos de los puntos de ventas o zonas9 es posible perfilar qué tipo de productos se venderán mejor en cada agrupación de puntos de venta. Esto permite que la logística realice un despacho personalizado a cada tienda para maximizar las ventas.
El clústering también puede ser empleado para asignar de una manera eficiente un factor importante en un proceso productivo. Por ejemplo, en el sector salud, el clústering puede utilizarse para identificar grupos de pacientes con síntomas o afecciones similares. Esta información puede ayudar a los hospitales a asignar el personal médico, los equipos y los planes de tratamiento, garantizando que los recursos se utilicen al máximo de su potencial. Las aplicaciones son muchas.
Por otro lado, aunque suene raro, es importante notar que los modelos de clústering también pueden servir para realizar la tarea de detección de anomalías y en especial la detección de fraudes. Las técnicas de clústering pueden identificar patrones anómalos en grandes conjuntos de datos transaccionales. En este contexto, los algoritmos de clústering pueden identificar grupos de transacciones que se desvían del comportamiento “normal”, ayudando a las instituciones financieras y a las agencias de seguridad a detectar posibles intentos de fraude y a tomar las medidas oportunas. Por ejemplo, una empresa de tarjetas de crédito puede utilizar el clústering para identificar grupos de transacciones con patrones sospechosos, como compras de alto valor en diferentes lugares dentro de un período corto. Esta información permite a la empresa señalar posibles actividades fraudulentas y proteger los intereses financieros de sus clientes.
Los modelos de clústering se estiman o entrenan empleando una muestra de individuos10 para los cuales se cuenta con observaciones de algunas de sus características. Este tipo de tarea no tiene una variable a explicar e implica que el modelo o algoritmo aprenda sobre la estructura de los datos que caracterizan a los individuos. Así, estos modelos corresponden a lo que se conoce como aprendizaje no supervisado11, pues la muestra no contiene una variable objetivo que se encuentra etiquetada con la pertenencia o no de una observación a un grupo12. La misión del modelo o algoritmo es aprender cuál es el patrón que permitiría armar los grupos de individuos, dada las características de estos.
Regresando a las tareas del business analytics, una manera más común de clasificar los ejercicios de analítica es según su propósito. En ese caso, se tienen cuatro tipos de analítica (Ver Figura 1.3):
Analítica Descriptiva: Esta analítica se enfoca en resumir y visualizar los datos para obtener información sobre lo que ha sucedido en el pasado. Ayuda a comprender patrones y tendencias.
Analítica Diagnóstica: Esta analítica busca entender por qué algo ha sucedido. Examina los datos para identificar las causas raíz de los problemas o éxitos pasados.
Analítica Predictiva: Esta analítica utiliza modelos estadísticos y de aprendizaje de máquina para hacer pronósticos y predecir eventos futuros.
Analítica Prescriptiva: Esta analítica se centra en recomendar acciones y soluciones óptimas para lograr un objetivo.
Figura 1.3: Material multimedia: tipos de analítica

Estos cuatro tipos de analítica engloban las ocho tareas del business analytics. La tarea de clústering permite realizar analítica descriptiva y prescriptiva (Ver Figura 1.4).
Figura 1.4: Relación entre las tareas de analítica y los tipos de analítica

La analítica descriptiva responde a la pregunta: ¿qué está pasando en el negocio?13. El análisis de clústering permite describir los patrones (la estructura) de los datos identificando grupos de elementos similares entre sí. De hecho, los métodos o algoritmos que nos permiten construir los clústeres se consideran como métodos exploratorios de datos, pues nos permiten entender características de un conjunto de estos14.
La analítica predictiva busca responder la pregunta: ¿qué es posible que ocurra? Los modelos de clústering podrán ser empleados para determinar a qué grupo, probablemente, pertenecería un nuevo individuo, dadas sus características. Por ejemplo, una vez que se han identificado grupos de clientes con comportamientos similares, se puede aplicar un patrón identificado en los datos para predecir, usando las características del nuevo cliente y el modelo, el grupo al que pertenecería ese nuevo individuo.
La analítica prescriptiva busca responder la pregunta ¿qué necesito hacer? Los modelos de clústering nos permiten hacer este tipo de analítica al sugerir qué deberíamos hacer en algunas situaciones. Por ejemplo, si se requiere agrupar los clientes para una segmentación de consumidores, este análisis nos podrá sugerir cuántos grupos emplear y cómo asignar a cada cliente a su respectivo grupo.
1.2 Comentarios Finales
Las técnicas de construcción de clústeres pueden responder, por sí solas, una pregunta de negocio o pueden hacer parte de la exploración de los datos antes de desarrollar modelos complejos y probar distintas hipótesis. Estos métodos de clústering no incluyen ninguna teoría detrás, al tiempo que permiten que las observaciones (o casos) sean agrupados según la estructura propia sin necesidad de establecer ninguna variable dependiente y variables explicativas.
Precisamente, la característica de las técnicas de clústering de dejar que los datos se agrupen por si solos, presenta uno de los retos más importantes. Estamos frente a una tarea en la que queremos detectar cuáles son las agrupaciones “naturales” de las observaciones, pero no tenemos cómo observar cuáles serían los “verdaderos” grupos.
Para aclarar este punto, consideremos una tarea como la de pronosticar. Esa tarea implica estimar o entrenar un método para que se acerque a lo que ocurrió históricamente y este aprendizaje nos permite generar pronósticos. Pronósticos que podemos comparar con lo que realmente ocurra en el futuro y así establecer el error del pronóstico. Este tipo de tareas se conocen como aprendizaje supervisado.
Por otro lado, en la tarea de clústering tenemos un conjunto de datos para diferentes individuos y debemos construir los grupos sin tener un valor real que nos permita entrenar o estimar y que haga posible realizar una evaluación de los grupos formados frente a un valor “real” de pertenencia a un grupo. Este tipo de tareas se conoce como aprendizaje no supervisado. En este tipo de aprendizaje dejamos que la técnica determine los patrones de datos por sí misma. Las técnicas de clústering generan una variable (o característica) que no está en los datos originales observados que es la membresía a un grupo, mientras que los métodos de aprendizaje supervisado están diseñados para “generar” una variable que ya estaba en los datos originales.
En el Capítulo 2 estudiaremos la intuición detrás de las técnicas que generan clústeres y qué medidas podemos emplear para determinar si las agrupaciones que construimos son razonables.
Referencias
Para una discusión detallada de esta tarea y como implementarla en R se puede consular Alonso & Hoyos (2025a)↩︎
Para una discusión detallada del modelo clásico de regresión y como implementarlo en R se puede consular Alonso (2024).↩︎
Para una discusión detallada de esta tarea y como implementarla en R se puede consular Alonso & Arboleda (2025).↩︎
Para una discusión detallada de esta tarea y como implementarla en R se puede consular Alonso (2022)↩︎
Los modelos o algoritmos en algunos casos pueden ser útiles para hacer más de una tarea de analítica, como veremos más adelante. Por eso es importante distinguir entre la tarea de analítica y los modelos y algoritmos.↩︎
Como por ejemplo de ingreso promedio de la región, el clima, los hábitos de consumo y la edad.↩︎
Típicamente para los modelos de clústering se emplean muestras de corte transversal. Es decir, a muchos individuos se les observa sus características y la variable objetivo en el mismo período. En este libro concentraremos la atención en algoritmos de clústering que emplean datos de corte transversal. No obstante, es importante anotar que existen algoritmos de clústering que se emplean sobre series de tiempo de diferentes individuos; es decir, sobre datos de panel. Este tipo de clústering está por fuera del alcance de este libro. ↩︎
En el campo del aprendizaje de máquina se distinguen dos tipos de aprendizaje: supervisado y no supervisado. En el aprendizaje no supervisado los datos no contienen etiquetas o la “respuesta correcta”. El aprendizaje no supervisado busca descubrir patrones o estructuras ocultas en los datos.↩︎
Es decir, la respuesta “correcta” de pertenecer a un grupo no es conocida.↩︎
Para ver una introducción rápida al tipo de datos que se emplean en el business analytics ver el video disponible en el siguiente enlace: https://youtu.be/2OxY2UTI_Bs.↩︎
Las técnicas de construcción de clústeres también se pueden considerar como otra técnica de reducción de datos. Noten que en el caso de métodos de reducción de variables como el Análisis de Componentes Principales (PCA por su sigla en inglés) se generan grupos de variables, pero aquí los grupos se forman con los individuos. Por eso se puede considerar como una técnica de reducción de datos.↩︎