6 Detección de fraudes y la Ley de Benford
6.1 Introducción
En los capítulos anteriores hemos estudiado diferentes técnicas estadísticas para detectar outliers (Ver Capítulos 2 y 3) y multivariadas (Ver Capítulo 4). La detección de anomalías al ser aplicada a diferentes campos específicos toma denominaciones diferentes. Uno de esos campos más comunes en el mundo de los negocios es la detección de fraudes. En este capítulo emplearemos una técnica estadística que tiene como finalidad detectar anomalías en el primer dígito de los números: la Ley de Benford. Esta herramienta es tal vez de las herramientas más tradicionales para detectar fraudes en el sector financiero, sector salud, los seguros y las agencias gubernamentales.
La detección de fraudes es una de las aplicaciones más comunes de las técnicas de detección de anomalías; de hecho, la detección de fraudes es en sí una disciplina a la cual muchos contadores, estadísticos y científicos de datos dedican su tiempo. En todos los casos, si bien los términos pueden diferir, las técnicas de detección de fraude tienen como finalidad responder a la pregunta: ¿cuál de estas observaciones se comporta de manera diferente a las demás?
En este capítulo, antes de discutir la Ley de Benford, estudiaremos qué se entiende por fraude y los tipos de fraude.
6.2 Detección de fraudes
En general, el fraude se define como un crimen poco común, bien considerado, imperceptiblemente oculto, que evoluciona en el tiempo y, a menudo, cuidadosamente organizado, que aparece en muchos tipos y formas. Empleando herramientas de business analytics, se pueden examinar millones de acciones (transacciones) para detectar patrones y detectar acciones (transacciones) fraudulentas. El fraude es (típicamente) muy raro, pero el costo de no detectarlo puede ser enorme. Por ejemplo, según HSN-Consultants (2021) las compañías de tarjetas de crédito perdieron en 2021 a nivel mundial 6.8 centavos de dólar por cada US$100 de transacciones debido a fraude.
Existen muchas herramientas para detectar fraudes en un conjunto de datos. Estas van desde modelos de regresión logística50, hasta modelos de redes neuronales. Sin importar su origen, todas las herramientas de detección de fraude enfrentan tres grandes retos:
- deben evitar acosar a los buenos clientes.
- deben ser eficientes en su operación. Por ejemplo, en la detección de fraude de tarjetas de crédito se debe tomar una decisión en menos de 8 segundos (HSN-Consultants, 2021).
- debe ser robusto o manejar de alguna manera el desequilibrio que típicamente existe en las muestras. Es decir, típicamente las observaciones con fraude en una muestra son una proporción muy pequeña. Esto le puede generar sesgo a algunas herramientas de analítica. Por ejemplo, el fraude de tarjetas de crédito representa menos del 0.5% de todas las transacciones (HSN-Consultants, 2021).
Toda herramienta de detección de fraudes enfrenta estos tres retos en su tarea de descubrir anomalías. Es decir, detectar eventos que, en comparación con el comportamiento típico, simplemente no “encajan”.
Tipos de fraude
En últimas un fraude es un comportamiento anómalo que dependiendo del contexto y negocio se puede clasificar en los siguientes tipos:
- Fraude contra el lavado de dinero (SARLAF)
- Fraude de tarjetas de crédito
- Fraude aduanero
- Falsificación
- Robo de identidad
- Fraude de seguros
- Fraude hipotecario
- Fraude de no entrega
- Fraude en línea
- Fraude de garantía del producto
- Evasión fiscal
- Fraude de telecomunicaciones
- Robo de inventario
- Fraude de entradas
- Fraude electrónico
- Fraude de compensación de trabajadores
Las características más importantes que debe tener un modelo exitoso de detección de fraudes son:
- Precisión (Accuracy). Debe tener un poder de detección y exactitud altos cuando se marcan los casos como sospechosos de fraude.
- Interpretabilidad: Debe ser relativamente fácil de explicar el procedimiento para la “marcación” de casos fraudulentos. En la mayoría de los casos, se requiere cierto nivel de comprensión para que la dirección confíe en el modelo y permita su aplicación. Y en otras ocasiones se requiere poder explicar en ambientes judiciales lo que hace la herramienta.
- Cumplimiento normativo. Debe cumplir toda la normatividad vigente, incluyendo aquellas relacionadas con la privacidad.
- Costo razonable. Debe tener un costo razonable su aplicación y generar un retorno a la inversión también razonable. Debe evitarse aquellos modelos que tienen altos costos y pocos retornos a la organización.
- Complementar los enfoques basados en expertos. Debe ser un complemento a los enfoques clásicos de detección del fraude basados en expertos. Estos enfoques siguen siendo de uso generalizado y representan un buen punto de partida y una herramienta complementaria a los modelos basados en datos. No es una decisión entre humano y algoritmo, sino, por el contrario, debe ser un complemento del trabajo del humano.
6.3 La ley de Benford
Tal vez, una de las herramientas más sencillas y más usadas para encontrar fraudes en registros es la ley de Benford, o también conocida como la ley de los Primeros Dígitos o el Fenómeno de los Dígitos Significativos.
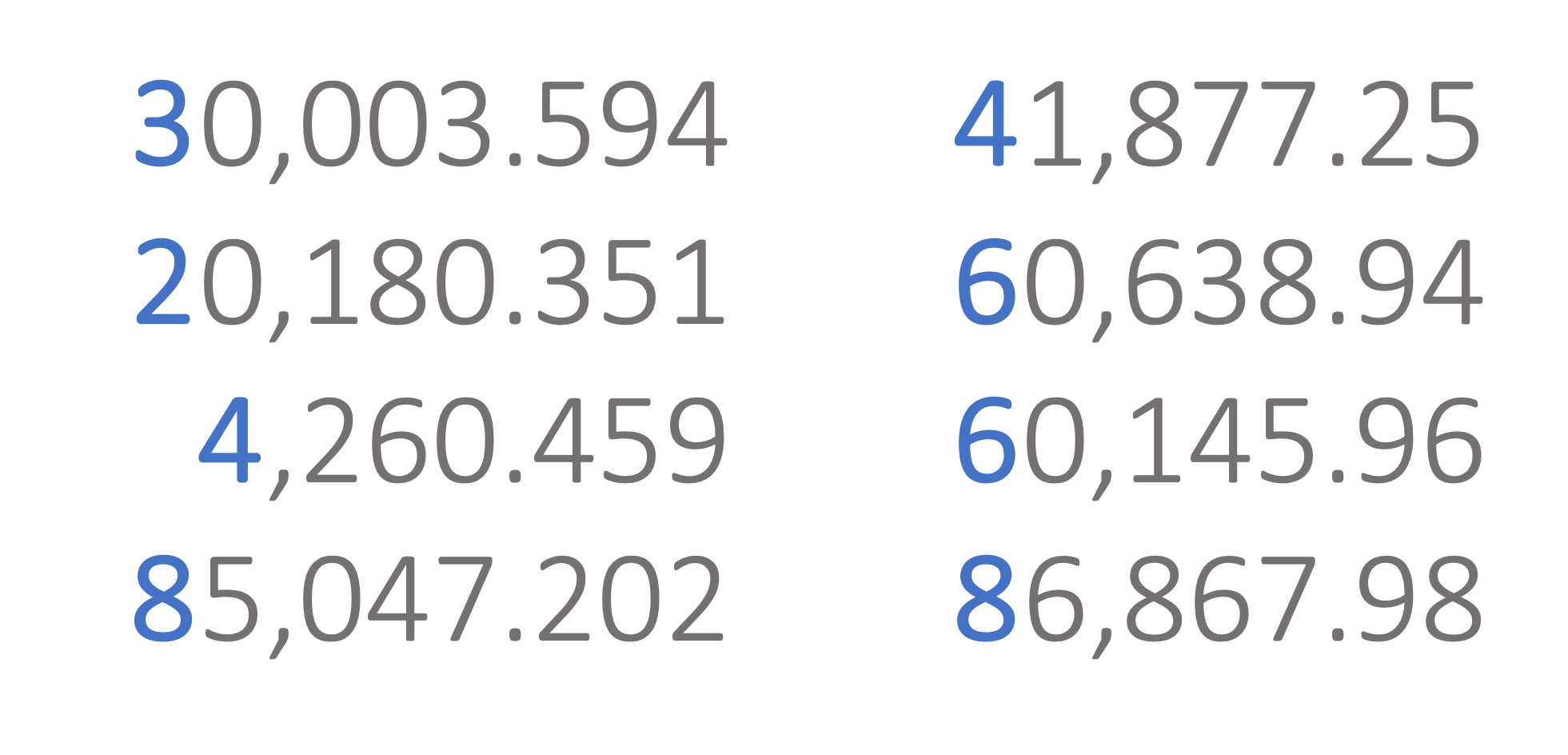
El primer dígito se refiere al dígito más a la izquierda. Por ejemplo, en el número \(123.241\) el primer dígito es el número \(1\) y en el número \(94\) el primer dígito es \(9\). En la Figura 6.1 se presentan 8 números que serían analizados. En la Figura 6.2 se resaltan los dígitos que serán empleados. La Ley de Benford se aplica únicamente a los primeros dígitos y no a todo el número.
Figura 6.1: Ocho números para el análisis

Figura 6.2: Primer dígito (resaltado) de los ocho números para el análisis
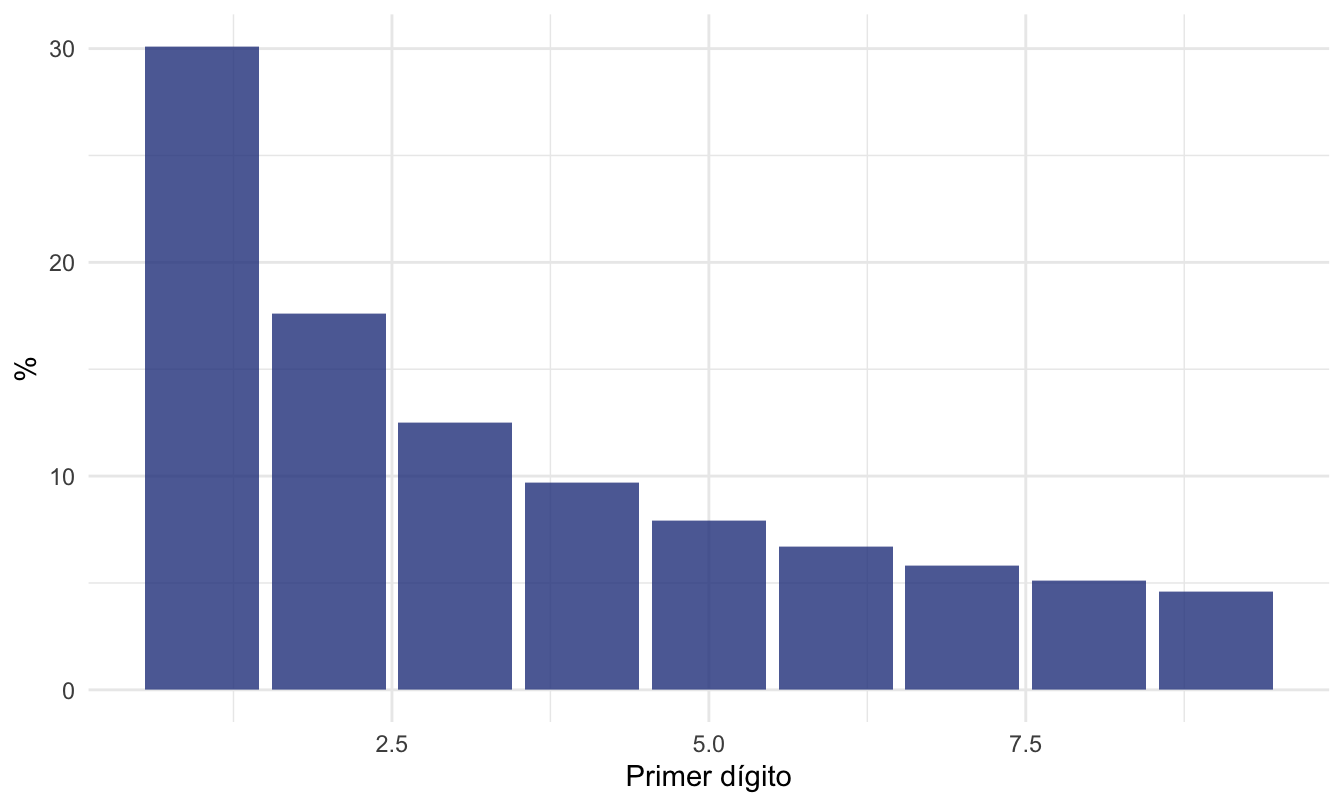
De regreso a la Ley de Benford, por un momento pensemos en un encuestador que no quiere salir a realizar el trabajo de campo para recoger las encuestas y, por el contrario, se dedica a llenar fraudulentamente las encuestas. Lo “natural” sería inventarse números que iniciaran con un número diferente y posiblemente inventar números que de manera uniforme tengan diferentes valores como primera cifra (ver un ejemplo en la Figura 6.3). Pero la Ley de Benford demuestra que existe una distribución muy diferente en unos datos “legítimamente” generados; es más, se espera que la distribución del primer dígito sea más parecida a la presentada en la Figura 6.4. Así, comparando la distribución de la primera cifra de los datos fraudulentamente generados con la esperada por la Ley de Benford (Figura 6.4) permitirá detectar un posible fraude.
En términos sencillos, esta ley implica que el primer dígito de los números encontrados (registros) en bases de datos de fuentes diversas no muestran una distribución uniforme como intuitivamente se esperaría (Ver Figura 6.3), sino que se organizan de tal manera que el dígito “1” es el más frecuente (30.1% de los registros), seguido de “2” (17.6%), “3” (12.5%), y así sucesivamente hasta “9” (4.6%) (Ver Figura 6.4). Es decir, se encuentra que aproximadamente el 30% de los registros deben iniciar por un “1”, el 18% por un “2” y así sucesivamente.
En otras palabras, esta ley establece que en muchos conjuntos de datos numéricos, los números que comienzan con el dígito 1 ocurren con mayor frecuencia que aquellos que comienzan con dígitos más altos. De hecho, según la Ley de Benford, aproximadamente el 30.1% de los números en un conjunto de datos comienzan con el dígito 1, mientras que solo alrededor del 4.6% comienzan con el dígito 9.
Figura 6.3: Distribución aproximadamente uniforme del primer dígito
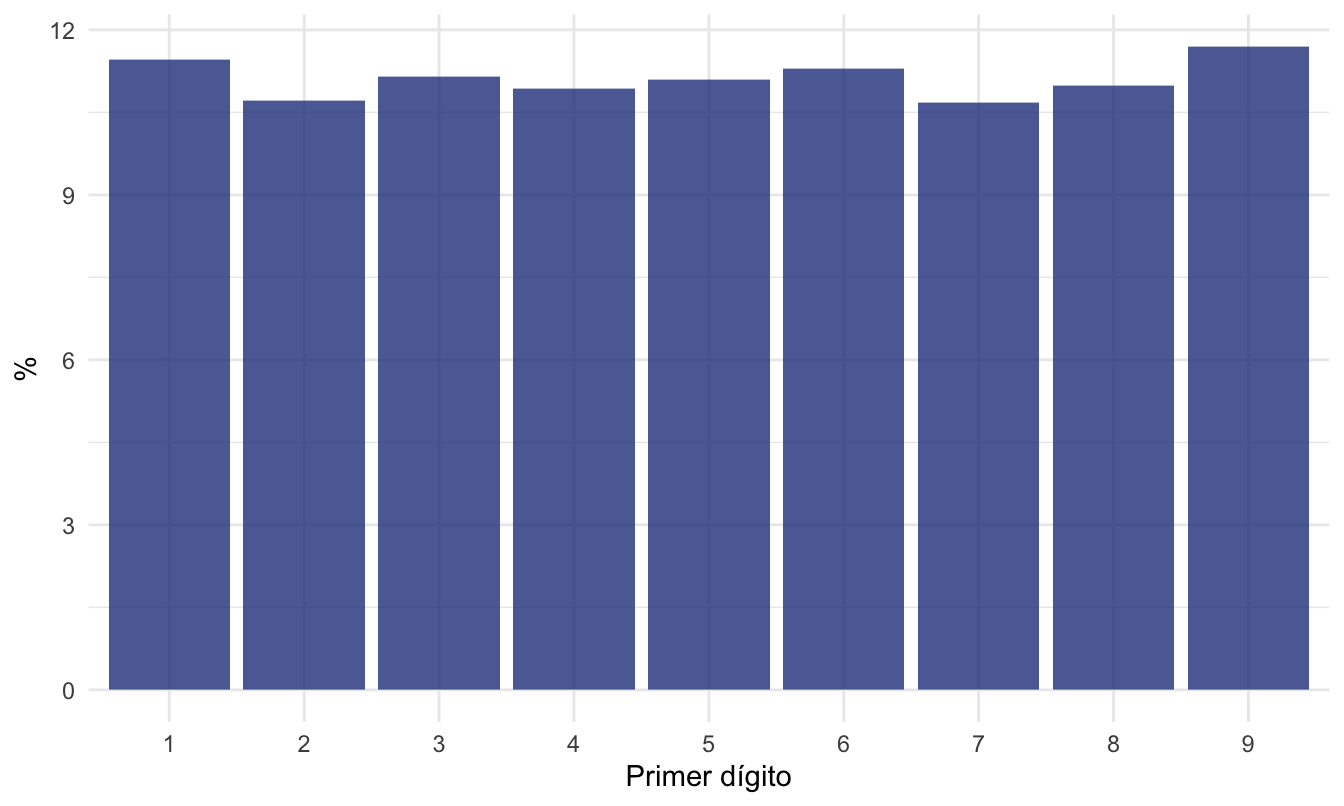
Figura 6.4: Distribución esperada por la Ley de Benford para el primer dígito
La ley de Benford establece que la probabilidad de observar como primer dígito a \(d\) (donde \(d=1,2,\dots 9\)) será:
\[\begin{equation} P(d)=\log_{10}{\left(d+1\right)}-\ \log_{10}{\left(d\right)}=\ \log_{10}{\left(\frac{d+1}{d}\right)=\ \log_{10}{\left(1+\frac{1}{d}\right)}} \tag{6.1} \end{equation}\]
Esto implica que la probabilidad de que ocurra cada uno de los 9 dígitos es como la reportada en el Cuadro 6.1.
| Digito | y |
|---|---|
| 1 | 30.10 |
| 2 | 17.61 |
| 3 | 12.49 |
| 4 | 9.69 |
| 5 | 7.92 |
| 6 | 6.69 |
| 7 | 5.80 |
| 8 | 5.12 |
| 9 | 4.58 |
| Fuente: cálculos propios. |
Antes de continuar es importante aclarar que la Ley de Benford no detecta fraude en sí misma, sino desviaciones en la distribución de los dígitos que pueden ser consistentes con fraude. Y en este sentido esta ley es considerada una herramienta poderosa frente al fraude, pero no es infalible. Por ejemplo, si un fraude es cometido por alguien que conoce la Ley de Benford y genera datos que cumplen con esta ley, entonces la herramienta no detectará el fraude.
6.4 Un poco de historia
Hablemos un poco de la historia de esta Ley. El primer registro sobre el tema se encuentra en un documento del astrónomo y matemático Simon Newcomb (Newcomb, 1881). La historia cuenta que Newcomb, mientras hojeaba páginas de un libro de tablas logarítmicas, notó que las páginas al principio del libro estaban más sucias que las páginas al final. Esto significaba que sus colegas, que compartían la biblioteca, preferían cantidades que comenzaban con el número uno en sus diversas disciplinas. Él documentó esa regularidad en dos páginas publicadas en el American Journal of Mathematics en 1881 (Newcomb, 1881), pero no presentó una demostración de por qué la regularidad debía cumplirse.
En 1938, el físico estadounidense Frank Benford revisó el fenómeno y encontró esa misma regularidad y la llamó la “Ley de Números Anómalos” (Benford, 1938)51. Benford publicó en la revista científica Proceedings of the American Philosophical Society un estudio en el que empleó 20,000 observaciones de datos recopilados de diversas fuentes para documentar la regularidad. Los datos empleados provenían de diferentes fuentes; desde caudales de ríos hasta pesos moleculares de compuestos químicos. También consideró información de costos, números de direcciones, tamaños de población y constantes físicas. Todos ellos, en mayor o menor medida, siguieron una distribución decreciente de manera exponencial. Este físico no solo documentó la regularidad, sino que también presentó una justificación del porqué ocurre; pero no se presentó una demostración de esta.
Posteriormente, en 1995, el fenómeno fue finalmente comprobado de manera estadística por Theodore P. Hill52 (Hill, 1995). El profesor Hill presentó una demostración estadística que da sustento al por qué se cumple esta regularidad. Él encontró que si se generan datos de manera legítima que se recolectan en bases de datos y se toman muestras aleatorias de estas, la distribución del primer dígito de la muestra convergerá a la distribución propuesta por Benford.
6.5 Condiciones necesarias para emplear la Ley de Benford
Se ha demostrado que este resultado se aplica a una amplia variedad de conjuntos de datos, incluidas facturas de electricidad, direcciones, precios de acciones, precios de viviendas, números de población, tasas de mortalidad, longitudes de ríos, etc. En general, una serie de registros numéricos seguirá la ley de Benford cuando esta representa magnitudes de eventos, tales como poblaciones de ciudades, flujos de agua en ríos o tamaños de cuerpos celestes53.
Típicamente se espera que la Ley de Benford funcione bien si se cumplen los siguientes cinco supuestos básicos en los datos:
- Se examinará una variable numérica positiva que no puede tomar el valor de cero.
- Las observaciones para la variable son generadas aleatoriamente, o vienen de un proceso que implica cierto grado de aleatoriedad.
- Los valores que toma la variable no se encuentran restringidos por un máximo o mínimo. Es decir, los datos no están censurados.
- Números no asignados de manera administrativa (como el de las cédulas o identificaciones o turnos).
- Se cuenta con una muestra grande.
- La variable tiene un orden de magnitud relativamente grande (en inglés Magnitude of order). El orden de magnitud es algo así como el rango en el que se pueden observar los datos. Por ejemplo, para que la Ley de Benford funcione debemos tener una variable cuyos valores puedan pasar en los valores que toma de 10, 100, 1,000, 10,000, etc. El orden de magnitud típicamente se mide en una escala logarítmica y se emplea para hacer más intuitivo y comprensible el tamaño de los números con los que se trabaja.
Así, estos supuestos implican que la muestra con la que se trabaja en un análisis que emplee la ley de Benford debe ser grande, no tener límites a los valores que puede tomar la variable que será valorada y se generen de forma aleatoria. Por ejemplo, los salarios por hora de operarios en una fábrica muy probablemente tendrán un mínimo y posiblemente algún máximo. Así no tendría mucho sentido emplear la Ley de Benford para detectar un posible fraude en el salario por hora de los operarios. Tampoco tendría sentido analizar los números telefónicos, números de cuentas bancarias o las cédulas digitadas en una base de datos.
Antes de aplicar la ley de Benford, siempre será necesario asegurarnos de que los supuestos se cumplen. En especial, en la práctica, el supuesto más fácil de violar es que los datos sean generados aleatoriamente sin límites.
Ahora, esto puede sonar restrictivo, pero la verdad no lo es. Por ejemplo, variables como facturas a clientes, desembolsos de dinero, pagos recibidos, artículos de inventario típicamente cumplen los supuestos. Algunos autores recomiendan muestras de al menos 100 observaciones, pero para estar más seguros sería razonable emplear muestras de más de 1000 registros.
Para establecer si se cuenta con un orden de magnitud razonable para la aplicación de esta Ley, se cuenta con el indicador de Orden de Magnitud (conducido como el \(OOM\) por su sigla en inglés). El \(OOM\) se define como:
\[\begin{equation} OOM = log_{10} \left ( \frac{max\left ( X \right )}{min\left ( X \right )} \right ) \tag{6.2} \end{equation}\]
donde \(X\) es la variable que se analizará con la Ley de Benford. Para cumplir el supuesto de la ley de Benford, se espera que \(OOM\) sea superior a 3 (Ver Kossovsky (2021) para una mayor discusión al respecto). También se ha propuesto una versión del \(OOM\) que sea robusta a la presencia de los valores extremos. Esta versión robusta del \(OOM\) (\(ROM\)) se define como: \[\begin{equation} ROM = log_{10} \left ( \frac{P_{99}\left ( X \right )}{P_{1}\left ( X \right )} \right ) \tag{6.3} \end{equation}\] donde \(P_{99}\) y \(P_{1}\) son el percentil 99 y el primero de la variable bajo estudio, respectivamente. Así, como el caso del \(OOM\), se espera que el \(ROM\) sea superior a 3 para tener un orden de magnitud adecuado para aplicar la Ley de Benford. No obstante, algunos autores como Kossovsky (2021) sugieren que incluso valores de \(ROM\) de 2.8 o incluso 2.5 podrían ser aceptables para aplicar la Ley de Benford, pero no por debajo de 2.5. No obstante, la regla común es emplear un \(ROM\) (o \(OOM\)) mayor que 3.
Finalmente, es importante anotar que una variable se ajusta mejor a esta Ley si proviene de una distribución que tiene una media menor que la mediana (sesgo positivo), y los datos no se concentran alrededor de la media. Es decir, para distribuciones no simétricas.
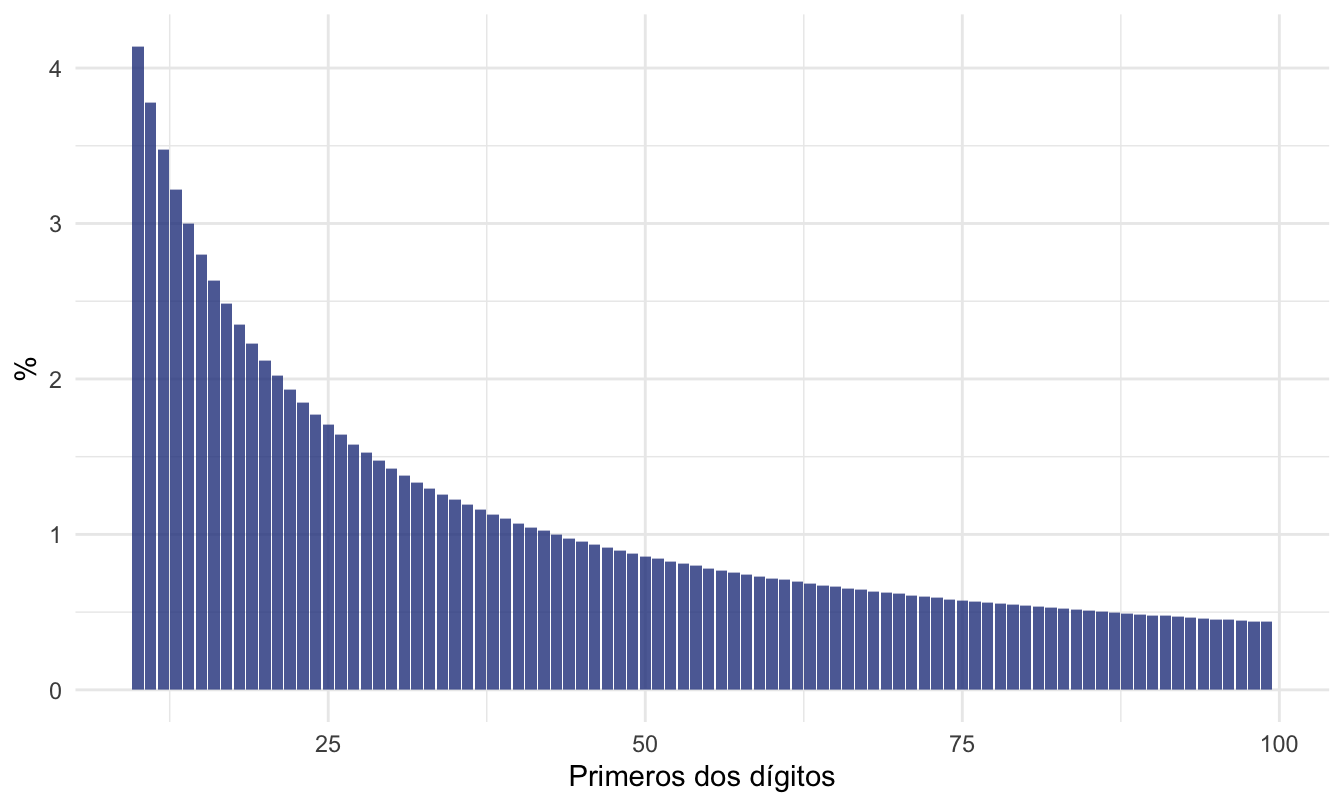
Para pasar a trabajar con un ejemplo, es importante mencionar que, así como existe una distribución para el primer dígito, también existe otra para los dos segundos (ver recuadro), terceros y los demás dígitos. Esa distribución es diferente y corresponde a una generalización de la Ley de Benford. La probabilidad de ocurrencia de los dos primeros dígitos (\(d_1d_2\)), es decir la probabilidad de observar en la primera posición el dígito \(d_1\) y en la segunda \(d_2\), está dada por: \[\begin{equation} P(d_1d_2)=\ \log_{10}{\left(1 + \frac{1}{d_1d_2}\right)} \tag{6.4} \end{equation}\]
donde \(d_1d_2 \in [10,11, \dots 98, 99]\). La probabilidad esperada por la Ley de Benford para los dos primeros dígitos se muestra en la Figura 6.5.
Figura 6.5: Distribución esperada por la Ley de Benford para los dos primeros dígitos
6.6 Implementando la Ley de Benford en R
En lo que resta de este capítulo emplearemos la Ley de Benford y R para detectar si existe algún tipo de anomalía o fraude en las facturas que se reportan en los pedidos que se presentan en la base de datos de facturas recibidas por una división de la empresa de servicios públicos West Coast. Los datos se encuentran en el archivo datosBenford.txt que se puede descargar de la página web del libro (https://www.icesi.edu.co/editorial/deteccion-anomalias). Estos datos son provistos por Nigrini (2012).
Esta base de datos tiene los registros de 184,412 facturas por pagar por parte de la empresa de servicios públicos West Coast a sus proveedores. Los datos corresponden al 2010 y las variables disponibles son:
registro: consecutivo de la facturaVendorNum: número del proveedorDate: fecha de emisión de la facturaAmount: valor de la factura.
La pregunta de negocio que se desea responder en este caso es: ¿tenemos fraudes en el proceso de facturación de los servicios públicos de West Coast? Así, nuestra misión será detectar si existen o no anomalías en el valor facturado (la variable Amount).
Empecemos por cargar los datos.
# Cargar datos
datos_WC <- read.table("./datos/datosBenford.txt", sep = ";", header = TRUE)
glimpse(datos_WC)## Rows: 184,412
## Columns: 4
## $ registro <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 1…
## $ VendorNum <int> 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, 2001, …
## $ Date <chr> "2/01/10", "2/01/10", "2/01/10", "2/01/10", "2/01/10", "2/01…
## $ Amount <dbl> 36.08, 77.80, 34.97, 59.00, 59.56, 50.38, 26.57, 102.17, 25.…Antes de empezar con nuestro análisis, calculemos el \(OOM\) y el \(ROM\) para determinar si el orden de magnitud de los datos permite aplicar la Ley de Benford.
Recuerda que queremos detectar si existen o no anomalías en las facturas por pagar (la variable Amount).
Siguiendo la expresión (6.2), el \(OOM\) se puede calcular con el siguiente código empleando las funciones max() y min() de la base de R:
## [1] 7.427543Y el \(ROM\) se puede construir calculando los percentiles con la función quantile() de la base de R. En este caso, siguiendo (6.3) el \(ROM\) se puede calcular de la siguiente manera:
# calcular el Orden de Magnitud robusto
ROM <- log10(quantile(datos_WC$Amount, 0.99)/ quantile(datos_WC$Amount, 0.01))
ROM## 99%
## 3.702056Tanto el \(OOM\) como el \(ROM\) son superiores a 3. Y los otros supuestos parecen razonables en este caso, así podemos proceder con nuestro análisis del cumplimiento o no de la Ley de Benford en las facturas por pagar de la empresa de servicios públicos West Coast a sus proveedores en el año 2010.
6.6.1 Análisis gráfico
Para construir un gráfico de barras para la frecuencia (histograma) del primer dígito, podemos emplear el paquete benford.analysis (Cinelli, 2018). Para esto debemos primero crear un objeto de clase Benford empleando la función benford() del paquete benford.analysis y posteriormente emplear la función plot() del mismo paquete.
La función benford() crea un objeto con los resultados del análisis de la Ley de Benford. Sus argumentos son:
donde:
- data: un vector con la variable a la que se le realizará el análisis.
- number.of.digits: el número de primeros dígitos para los que se realizará el análisis. Por defecto number.of.digits = 2, lo cual implica que se realiza el análisis para los dos primeros dígitos.
Recuerda que queremos detectar si existen o no anomalías en el valor facturado por pagar (la variable Amount). Por tanto, analicemos primero el primer dígito.
library(benford.analysis)
# se crea el objeto de clase benford
ben_WC <- benford(datos_WC$Amount, number.of.digits = 1)Ahora grafiquemos el resultado empleando la función plot() del paquete benford.analysis. Con el argumento except excluiremos unas visualizaciones que se producen automáticamente y que no son útiles en este momento para nuestro análisis
plot(ben_WC, except=c("second order", "summation",
"mantissa", "chi squared",
"abs diff", "ex summation",
"Legend"), multiple = FALSE )Figura 6.6: Distribución observada (barra) y esperada (línea punteada) del primer dígito para el valor de las facturas por pagar de la empresa West Coast
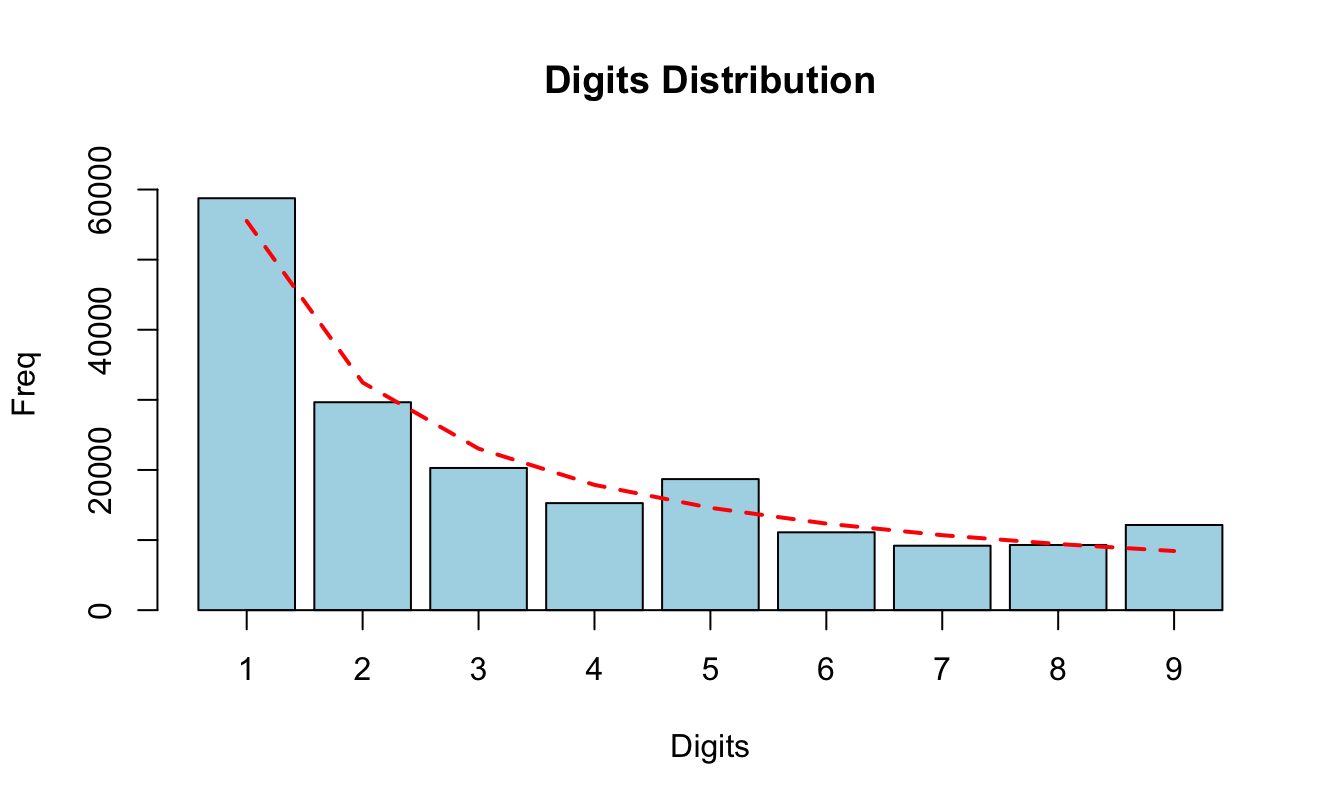
En la Figura 6.6 podemos observar que los dígitos 5 y 9 tienen una frecuencia relativamente alta frente a lo esperado. Podemos crear una tabla con las diferencias (absolutas) entre el número de veces que se observa una cifra y el valor esperado por la Ley de Benford empleando la función suspectsTable() del paquete benford.analysis. Esta función organiza de mayor a menor los dígitos que más se alejan de su valor esperado. Veamos los tres dígitos que más se alejan de lo esperado.
## digits absolute.diff
## <int> <num>
## 1: 5 4093.028
## 2: 9 3710.770
## 3: 1 3245.456El dígito 5 se aleja en 4093.03 veces lo esperado. Nota que los decimales aparecen porque la predicción de la Ley de Benford no necesariamente será un número entero. En este caso esa diferencia es positiva. Algo similar ocurre para el dígito 9.
Ahora bien, es importante reconocer que es imposible que el número observado de veces de un dígito sea exactamente igual a lo esperado por la Ley de Benford. ¡Estamos en el mundo probabilístico! Por eso será importante realizar pruebas estadísticas que nos permitan determinar si existe una diferencia sistemáticamente significativa entre lo observado y lo esperado por la Ley de Benford.
6.6.2 Análisis estadístico
Para determinar si existe o no una diferencia estadísticamente significativa (con un nivel de confianza de \(100 \cdot (1- \alpha)\)% ) será necesario emplear pruebas estadísticas.
La primera prueba que consideraremos es de carácter individual. Para determinar si existe una diferencia entre lo observado y lo esperado para cada uno de los dígitos individualmente, podemos crear un intervalo de confianza para la proporción esperada de apariciones de un dígito como primer dígito en la muestra. Si la proporción observada para ese dígito en la muestra está en el intervalo de lo esperado, entonces podremos afirmar con un \(100 \cdot (1- \alpha)\)% que la proporción observada no discrepa de lo esperado. En otras palabras, se cumple la Ley de Benford para ese dígito.
Una forma de construir un intervalo de confianza del \(100 \cdot (1- \alpha)\)% para la proporción esperada por la Ley de Benford para cada uno de los dígitos (\(d\)) es emplear la siguiente fórmula: \[\begin{equation} P \left ( d \right ) \pm z_{\frac{\alpha}{2}} \cdot \sqrt{n \cdot P(d)\cdot \left ( 1- P \left ( d \right ) \right ) } + \frac{1}{2n} \tag{6.5} \end{equation}\] donde \(P(d)\) es la probabilidad esperada por la Ley de Benford de que aparezca el dígito \(d\) y \(n\) es el número de observaciones.
Esto lo podemos calcular rápidamente con la función signifd.analysis() del paquete BenfordTests (Joenssen, 2015). Esta función tiene los siguientes argumentos:
donde:
- x: es un vector con la variable a la que se le realizará el análisis.
- number.of.digits: el número de primeros dígitos para los que se realizará el análisis. Por defecto digits = 1, lo cual implica que se realiza el análisis para el primer dígito.
- ci_lines: una lista que contiene los niveles de significancia para los intervalos de confianza que se graficarán. Por defecto se graficará un intervalo del 95% de confianza (ci_lines = c(.05)). Nota que se pueden graficar más de un intervalo de confianza.
Empleemos esta función para nuestro ejemplo y construyamos intervalos de confianza con un 99% de confianza.
library(BenfordTests)
#construir intervalos de confianza
signifd.analysis(datos_WC$Amount, digits = 1,
ci_lines = c(.01))Figura 6.7: Intervalos de confianza para la proporción esperada por la Ley de Benford y proporción observada (+) del primer dígito para el valor de las facturas por pagar de la empresa West Coast
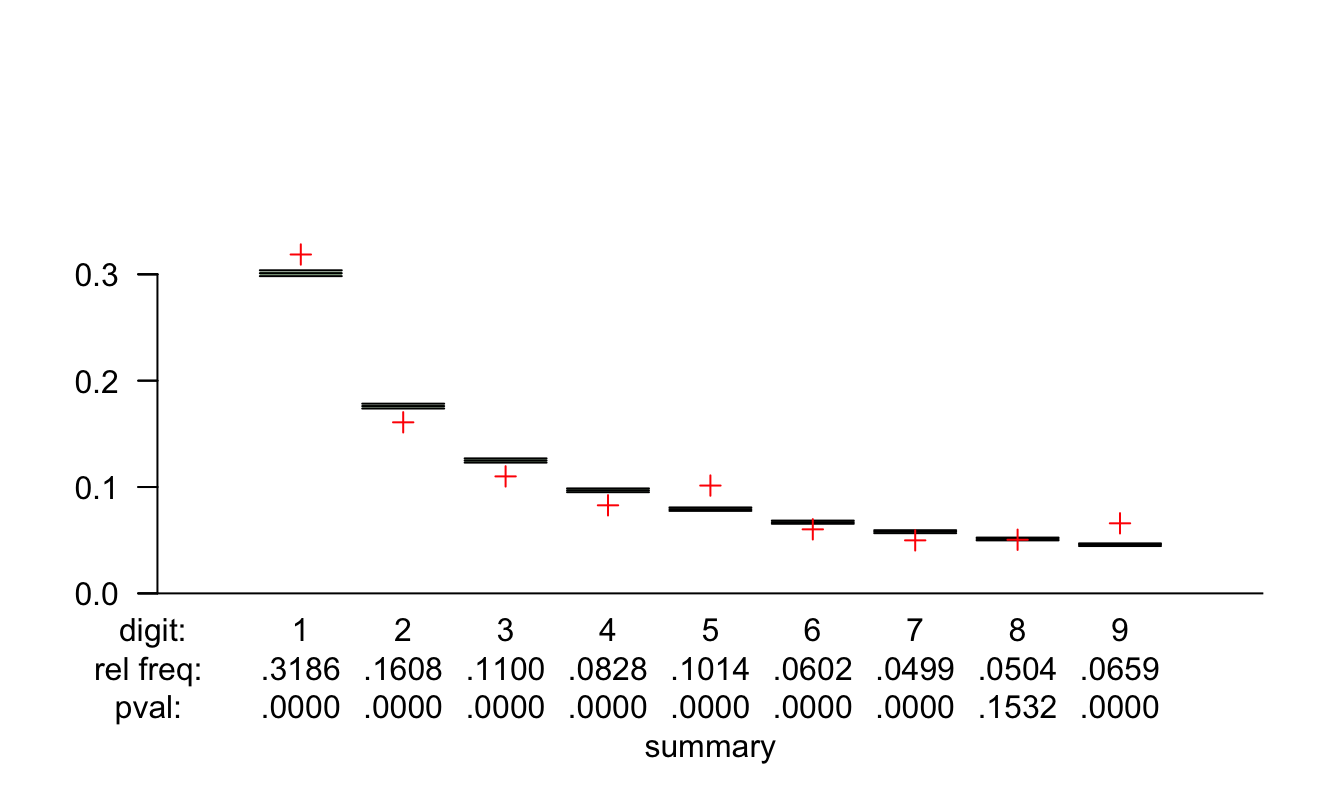
En la Figura 6.7 podemos observar que con excepción del dígito 8, todas las proporciones observadas caen fuera del intervalo esperado por la Ley de Benford. O dicho de otra manera, se puede rechazar la hipótesis54 que la proporción observada es igual a la predicha por la Ley de Benford, a excepción del dígito 8.
No obstante, estas pruebas individuales pueden estar acumulando muchos errores al estar haciendo muchas comparaciones al mismo tiempo. Sería más conveniente emplear una prueba que probara al mismo tiempo si los datos cumplen o no la Ley de Benford55.
La prueba \(\chi ^2\) de Pearson (\(Pearson_{\chi^2}\)) permite probar si la distribución de una muestra observada concuerda con una distribución teórica determinada. En este caso, podemos comprobar la hipótesis nula de que las proporciones observadas para cada dígito (\(\hat P_d\)) concuerdan al mismo tiempo con aquellas previstas por la Ley de Benford (\(P(d)\)) para cada uno de los dígitos (\(d=1, 2 \dots 9\)) versus la alterna de que no (no se cumple la Ley de Benford) empleando el siguiente estadístico de prueba: \[\begin{equation} Pearson_{\chi^2} = N \cdot\sum^{d}{\frac{\left ( \hat P_d - P(d) \right )^2}{P(d)}} \tag{6.6} \end{equation}\]
Este estadístico de prueba sigue una distribución \(\chi ^2\) con 8 grados de libertad para el caso del primer dígito y 9 para el de los dos primeros dígitos. Así, en caso de rechazar la hipótesis nula, tendremos evidencia de que los datos no siguen la Ley de Benford.
Este estadístico lo podemos calcular con la función chisq() del paquete benford.analysis de la siguiente manera:
##
## Pearson's Chi-squared test
##
## data: datos_WC$Amount
## X-squared = 4258.6, df = 8, p-value < 2.2e-16En este caso, con un 99% de confianza, podemos rechazar la hipótesis nula de que la muestra se comporta como lo predice la Ley de Benford.
Otra forma de comprobar el cumplimiento (complience en inglés) de la Ley de Benford fue sugerida por Nigrini (2012). Este autor sugiere emplear Desviación Media Absoluta (\(MAD\) por la sigla del inglés Mean Absolute Deviation) que tiene en cuenta qué tan desviada está cada proporción observada de la teórica sin tener en cuenta el tamaño de la muestra. El \(MAD\) está definido como: \[\begin{equation} MAD=\sum^{d}{\frac{\left| \hat P(d) - P_d \right|}{k}} \tag{6.7} \end{equation}\] donde \(k\) es 9 para el caso del primer dígito y 90 para los dos primeros dígitos56.
Nigrini (2012) provee unos límites para sacar conclusiones con el \(MAD\) (Ver Cuadro 6.2).
| Primer dígito | Dos primeros dígitos | Conlusión (Cumplimiento de la Ley) |
|---|---|---|
| 0.000 to 0.006 | 0.000 to 0.012 | estrecha |
| 0.006 to 0.012 | 0.012 to 0.018 | aceptable |
| 0.012 to 0.015 | 0.018 to 0.022 | marginalmente aceptable (se cumple para algunos dígitos) |
| mayor a 0.015 | mayor a 0.022 | No |
| Fuente: cálculos propios. |
Este estadístico también lo podemos calcular con el paquete benford.analysis por medio de la función MAD() .
## [1] 0.0133147La decisión a partir del Cuadro 6.2 se puede obtener automáticamente con este paquete. De hecho, ya en el objeto ben_WC que habíamos calculado con la función benford() tenemos este resultado. Observa con cuidado el resultado de llamar este objeto.
##
## Benford object:
##
## Data: datos_WC$Amount
## Number of observations used = 184412
## Number of obs. for second order = 65428
## First digits analysed = 1
##
## Mantissa:
##
## Statistic Value
## Mean 0.4951
## Var 0.0918
## Ex.Kurtosis -1.2579
## Skewness 0.0011
##
##
## The 5 largest deviations:
##
## digits absolute.diff
## 1 5 4093.03
## 2 9 3710.77
## 3 1 3245.46
## 4 2 2813.34
## 5 3 2756.20
##
## Stats:
##
## Pearson's Chi-squared test
##
## data: datos_WC$Amount
## X-squared = 4258.6, df = 8, p-value < 2.2e-16
##
##
## Mantissa Arc Test
##
## data: datos_WC$Amount
## L2 = 0.0040803, df = 2, p-value < 2.2e-16
##
## Mean Absolute Deviation (MAD): 0.0133147
## MAD Conformity - Nigrini (2012): Marginally acceptable conformity
## Distortion Factor: -1.065467
##
## Remember: Real data will never conform perfectly to Benford's Law. You should not focus on p-values!La conclusión la muestra automáticamente la función. En este caso, la conclusión es “MAD Conformity - Nigrini (2012): Marginally acceptable conformity”. Es decir, marginalmente aceptable, lo cual implica que algunos dígitos se cumplen la Ley de Benford y otros no.
Esto quiere decir que los datos de las facturas por pagar a sus proveedores de la empresa de servicios públicos West Coast en el año 2010 no cumplen la Ley de Benford. Estamos frente a la posibilidad de un fraude.
6.6.3 Trabajando con los casos problemáticos.
Cuando se detecta un posible fraude, será necesario buscar dónde está presente. Ya vimos cómo descubrir aquellos dígitos con la mayor desviación a lo esperado por la Ley de Benford con la función suspectsTable() . En nuestro ejemplo esos dígitos son el 5 y el 9. Esto quiere decir que las facturas que inician con estos dígitos son las principales sospechosas de fraude.
Esto implicará que el siguiente paso será sacar de la base de datos aquellas facturas cuyos montos inicien con 5 y 9 para un análisis más minucioso. Eso lo podemos hacer con la función getDigits() del paquete benford.analysis. Necesitamos tres argumentos. El objeto de clase benford, la base de datos original y qué (primer) dígito queremos extraer. Por ejemplo, guardemos en un objeto todos los registros (las observaciones) que inician con los dígitos 5 y 9.
# Extraer registros con primer dígito 5 y 9
digitos_5_9 <- getDigits(ben_WC, datos_WC, digits=c(5, 9))
head(digitos_5_9)## registro VendorNum Date Amount
## <int> <int> <char> <num>
## 1: 4 2001 2/01/10 59.00
## 2: 5 2001 2/01/10 59.56
## 3: 6 2001 2/01/10 50.38
## 4: 12 2001 2/01/10 55.22
## 5: 15 2001 2/01/10 55.29
## 6: 19 2001 2/01/10 94.29Con este objeto de clase data.frame ya se puede empezar el análisis de las facturas sospechosas en otras áreas de la organización.
Otra tarea que nos gustaría hacer es encontrar los duplicados. Explora las funciones duplicatesTable() y getDuplicates() del paquete benford.analysis. Por ejemplo,
#imprimir los duplicados por orden decreciente
duplicatesTable(ben_WC)
#obtener las observaciones de los 2 valores con más duplicados
duplicados <- getDuplicates(ben_WC, datos_WC,how.many=2) Por otro lado, no consideramos el análisis de los dos primeros dígitos. Con lo estudiado tú puedes constatar que tampoco se cumple la ley de Benford para los dos primeros dígitos. Esto podría ayudar a acotar la búsqueda de los fraudes. ¡Realiza este análisis!
6.7 Comentarios Finales
En este capítulo hemos definido lo que se entiende por fraude y cómo la tarea de detección de fraudes es un caso especial de la detección de anomalías. También estudiamos la Ley de Benford, que es una herramienta estadística para encontrar anomalías univariadas. Específicamente, estudiamos cómo encontrar anomalías relacionadas con el primer dígito, pero es muy fácil generalizar lo estudiado para los primeros dos dígitos.
La Ley de Benford ofrece una aproximación estadística sencilla y poderosa para detectar irregularidades en datos, especialmente los contables y financieros. No obstante, debe complementarse con otras técnicas de auditoría y de análisis de anomalías, pues por sí sola no constituye una prueba concluyente de fraude.
También es importante anotar que el cumplimiento de esta Ley no necesariamente significa que no existe fraude. Significa que no se adulteraron las cifras, no se generaron de manera artificial. ¡Pero el fraude puede estar presente de muchas otras maneras! Por eso es común que se combinen diferentes aproximaciones de detección de anomalías en la búsqueda de fraude.
Hasta el capítulo anterior habíamos discutido técnicas de detección de anomalías que son especialmente útiles en los procesos de ETL y EDA. En el ETL común el uso de técnicas univariadas para la detección de outliers, mientras que en el EDA el análisis de outliers multivariados es más común. La técnica que estudiamos en este capítulo no se emplea típicamente en los procesos de ETL ni de EDA. La ley de Benford es una herramienta que es empleada típicamente en el moldeamiento como tal de los datos, que están directamente relacionados con responder una pregunta específica de negocio.
Si recordamos la ilustración presentada en la introducción del Capítulo 3 (Ver Figura 6.8), la Ley de Benford estaría ubicada en la parte superior derecha. En los Capítulos 9 y 10 estaremos estudiando herramientas, que al igual que la Ley de Benford, son más empleadas en el modelado necesario para responder preguntas específicas de negocio. Pero antes, en el Capítulo 8 estudiaremos unas técnicas del aprendizaje de máquina para detectar anomalías que hacen parte de las herramientas empleadas en el EDA.
Figura 6.8: La Ley de Benford como herramienta de modelado en el mundo del business analytics
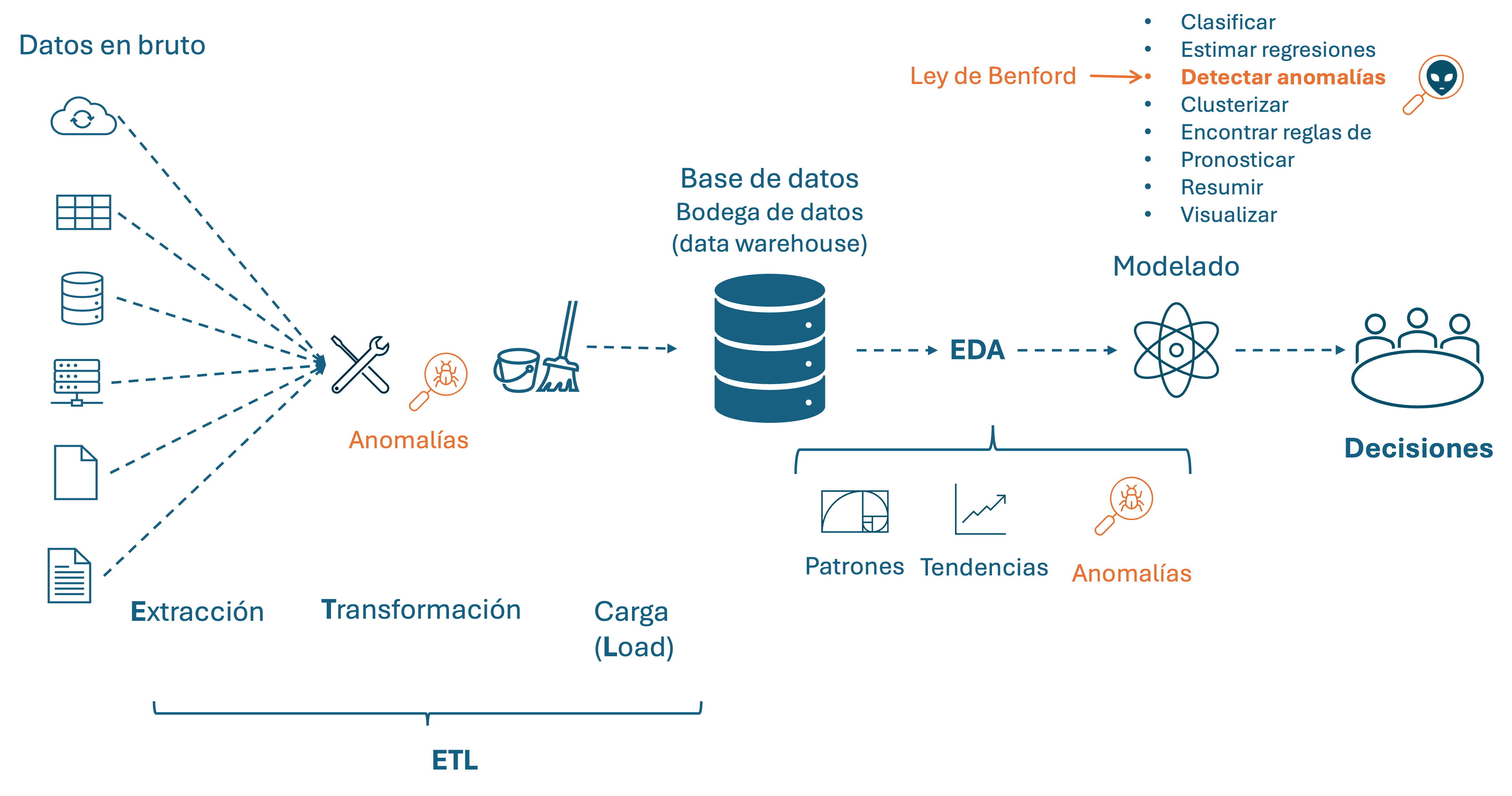
Con este capítulo se concluye la primera parte del libro, que está dedicada a las técnicas estadísticas para la detección de anomalías. En la tercera parte del libro estudiaremos técnicas de aprendizaje de máquina o ML (por sus siglas en inglés de Machine Learning) para la detección de anomalías. En el Capítulo 8 estudiaremos técnicas basadas en la distancia entre observaciones, en el Capítulo 9 estudiaremos técnicas basadas en la densidad de las observaciones y en el Capítulo 10 estudiaremos técnicas basadas en árboles de decisión.
Referencias
Para una discusión del modelo Logit puedes consultar el capítulo 3 de Alonso & Hoyos (2025).↩︎
Una reimpresión del artículo original se encuentra en Benford (2012).↩︎
Theodore P. Hill era en ese momento profesor de matemáticas de la Universidad de Georgia Tech en los Estados Unidos.↩︎
En el siguiente enlace puedes encontrar diferentes ejemplos en los que funciona la Ley de Benford: https://testingbenfordslaw.com.↩︎
En este caso podemos emplear los valores p (pval). Recuerda que podemos rechazar la hipótesis nula con un 99% (95%) de confianza si el valor p es menor que 0.01 (0.05).↩︎
Si estás familiarizado con el análisis estadístico de la regresión múltiple, este es el mismo problema de estar empleando muchas pruebas individuales para sacar conclusiones sobre un conjunto de pendientes. Siempre será mejor una prueba estadística conjunta.↩︎
\(k\) es el número de posibles combinaciones de dígitos.↩︎