1 Introducción
En los últimos años se ha acelerado la transformación del mundo de los negocios por la cada vez más grande disponibilidad de mayores volúmenes de información y capacidad de cómputo que permiten emplear modelos de analítica para responder preguntas de negocio y así generar valor a las organizaciones (Alonso, 2024). Emplear herramientas de business analytics y Big Data permite tanto optimizar los procesos actuales de la organización como generar características diferenciadoras para cada organización.
Los datos se han convertido en un recurso estratégico para las organizaciones, y el business analytics es la herramienta con la que las organizaciones pueden monetizar ese recurso (Alonso, 2024). El business analytics es el proceso científico de transformar datos en insights con el propósito de tomar mejores decisiones (Alonso, 2024).
En el mundo del business analytics nos enfrentamos a preguntas de negocios que implican identificar lo inesperado, lo excepcional, lo que se desvía de lo habitual. Este desafío es fundamental en muchas áreas de las organizaciones: por ejemplo, en la planta de producción se desea detectar el producto anómalo y en el área contable se desea encontrar fraudes. La identificación de lo inesperado, lo excepcional, lo que se desvía de lo habitual, se conoce en el mundo del business analytics como la tarea de detección de anomalías.
En este libro, exploraremos en profundidad algunos de los modelos que se emplean en la detección de anomalías y su implementación en R (R Core Team, 2025). Como lo discutiremos, encontrar lo inesperado, lo excepcional, lo que se desvía de lo habitual dependerá en parte del contexto del negocio y del tipo de datos de los que dispongamos. Así mismo, las herramientas (modelos) que se emplean para encontrar estas anomalías son muy diferentes y tienen diferente naturaleza.
Antes de entrar en el detalle de las técnicas, estudiaremos en este capítulo qué es la tarea de detección de anomalías, qué tipo de analítica se puede desarrollar con esta tarea, qué se entiende por anomalía y los tipos de anomalías que podemos encontrar. Esto permitirá entender de manera más fácil las herramientas que tenemos a nuestra disposición para la detección de anomalías y cuándo se debería emplear cada una de ellas.
1.1 Tareas de analítica y tipos de analítica
El proceso científico de transformar datos en insights para la toma de decisiones parte de una buena pregunta de negocio. A partir de los datos disponibles, los científicos de datos deberán escoger la mejor herramienta para responder a la pregunta de negocio planteada. Las respuestas a las preguntas de negocio implican diferentes tareas que se pueden clasificar en una de las siguientes categorías3:
- Clasificar4.
- Estimar regresiones5.
- Detectar anomalías.
- Clusterizar (Agrupar)6.
- Encontrar reglas de asociación (o buscar coocurrencia de productos)7.
- Pronosticar.
- Resumir.
- Visualizar8.
La tarea de detección de anomalías tiene como finalidad encontrar al individuo (observación) que se comporta de manera diferente a los demás. En otras palabras, la tarea de detección de anomalías se emplea para encontrar aquel caso (observación) que no sigue el patrón de las otras observaciones.
Por ejemplo, en algunas situaciones se deseará determinar si el patrón de compra de un sujeto se desvía significativamente de lo normal (norma establecida). Otro ejemplo podría ser en el área de producción, donde se desea identificar productos defectuosos que no cumplen con los estándares de calidad establecidos. En el área de finanzas y contabilidad, la detección de anomalías puede emplearse para identificar transacciones financieras inusuales que podrían indicar fraude o errores contables. En el área de recursos humanos, la detección de anomalías puede ayudar a identificar patrones de comportamiento inusuales entre los empleados que podrían indicar problemas de desempeño o mal uso de los recursos de la organización. En el área de logística, la detección de anomalías puede emplearse para identificar patrones inusuales en la cadena de suministro que podrían indicar problemas en la entrega o distribución de productos. En la Figura 1.1 se presenta una representación gráfica de esta tarea.
Figura 1.1: Tarea de detección de anomalías
Las preguntas de negocio que se pueden responder con la tarea de detección de anomalías pueden ser muy variadas. Por ejemplo, en el área de mercadeo pueden surgir preguntas como:
- ¿Cuáles son los patrones de comportamiento de los clientes en línea que podrían indicar actividad fraudulenta?
- ¿Qué campañas publicitarias han generado un aumento inusual en el tráfico del sitio web?
- ¿Existen segmentos de clientes que están mostrando un comportamiento de compra atípico?
En el área de ventas las preguntas pueden ser del tipo:
- ¿Qué transacciones de ventas son significativamente mayores o menores que lo habitual y requieren una revisión más detallada?
- ¿Qué regiones geográficas están experimentando un aumento inusual en las ventas?
- ¿Existen productos que están experimentando un cambio repentino en la demanda?
En el área de finanzas y contabilidad de una organización pueden surgir preguntas de negocio que implican la tarea de detección de anomalías como las siguientes:
- ¿Qué transacciones financieras son anómalas y podrían indicar fraude?
- ¿Cuáles son los patrones de gastos inusuales que podrían indicar problemas en la gestión financiera?
- ¿Cuáles son las transacciones contables que no cumplen con las normativas o políticas internas?
- ¿Qué cuentas muestran cambios inusuales en los saldos?
- ¿Existen patrones de facturación que podrían indicar actividades fraudulentas?
En el área de recursos humanos también pueden surgir preguntas como:
- ¿Cuáles son los patrones de comportamiento de los empleados que podrían indicar un mal uso de los recursos de la organización?
- ¿Existen discrepancias inusuales en los registros de asistencia o tiempo de trabajo?
- ¿Qué tendencias de rotación de personal son atípicas y podrían requerir intervención?
En el área de producción las preguntas pueden ser como las siguientes:
- ¿Qué patrones de producción son anómalos y podrían indicar problemas de calidad o mantenimiento?
- ¿Existen discrepancias inusuales en los niveles de inventario?
- ¿Qué máquinas o equipos están experimentando un aumento inusual en el tiempo de inactividad?
En el área de logística las preguntas podrían ser como las siguientes:
- ¿Cuáles son los patrones de distribución que son atípicos y podrían indicar problemas en la cadena de suministro?
- ¿Existen retrasos inusuales en la entrega de productos a los clientes?
- ¿Qué rutas de transporte están experimentando un aumento inusual en los costos?
En general, las preguntas pueden ser muy variadas y dependen del área funcional y de la industria a la que pertenece la organización. La gama de preguntas de negocio que se pueden responder con la tarea de detección de anomalías es muy grande.
Por otro lado, es importante anotar que los datos que se emplean para realizar la detección de anomalías pueden corresponder a muestras de corte transversal9 o series de tiempo10. Las muestras pueden o no contener una variable con anomalías previamente marcadas o no. Es decir, en algunas situaciones podemos tener datos en los cuales ya se rotuló cuáles observaciones son anomalías y cuáles no. En este caso, la tarea de detección de anomalías corresponderá a modelos de aprendizaje supervisado11, en especial modelos de clasificación. Para este tipo de modelos, la muestra contiene la variable objetivo (es anomalía o no) que se encuentra etiquetada12. La misión del modelo o algoritmo es aprender de esos datos cuál es el patrón que permitiría predecir la categoría (anomalía o no) de un individuo dadas las características de este. En este libro no estudiaremos los modelos de detección de anomalías de aprendizaje supervisado. Si quieres estudiar estos modelos, puedes estudiar los modelos de clasificación que pueden servir también para detectar anomalías. Para estudiar los modelos de clasificación te recomendamos consultar a Alonso & Hoyos (2025).
En otras oportunidades, la muestra con la que se cuenta no tiene rotuladas las observaciones que se consideran anomalías. En esta situación, la misión del algoritmo que empleemos es detectar cuáles observaciones son anómalas. En este caso la tarea de detección de anomalías implicará emplear modelos de aprendizaje no supervisado, pues la muestra no contiene una variable objetivo que se encuentra etiquetada con la pertenencia o no de una observación a un grupo13. La misión del modelo o algoritmo es aprender de esos datos cuál es el patrón que permitiría determinar los individuos (dadas las características de estos) que son anómalos.
En otras palabras, en el caso de la tarea de detección de anomalías, dependiendo de la muestra disponible y de la pregunta de negocio, se pueden emplear modelos de aprendizaje supervisado o no supervisado. En este libro nos concentraremos en modelos de aprendizaje no supervisado para detectar anomalías.
Regresando a las tareas del business analytics, una manera más común de clasificar los ejercicios de analítica es según su propósito (Alonso & Serrano, 2025). En ese caso se tienen cuatro tipos de analítica (Ver Figura 1.2):
Analítica Descriptiva: Esta analítica se enfoca en resumir y visualizar los datos para obtener información sobre lo que ha sucedido en el pasado. Ayuda a comprender patrones y tendencias.
Analítica Diagnóstica: Esta analítica busca entender por qué algo ha sucedido. Examina los datos para identificar las causas raíz de los problemas o éxitos pasados.
Analítica Predictiva: Esta analítica utiliza modelos estadísticos y de aprendizaje de máquina para hacer pronósticos y predecir eventos futuros.
Analítica Prescriptiva: Esta analítica se centra en recomendar acciones y soluciones óptimas para lograr un objetivo.
Figura 1.2: Material multimedia: tipos de analítica

Figura 1.3: Relación entre las tareas de analítica y los tipos de analítica
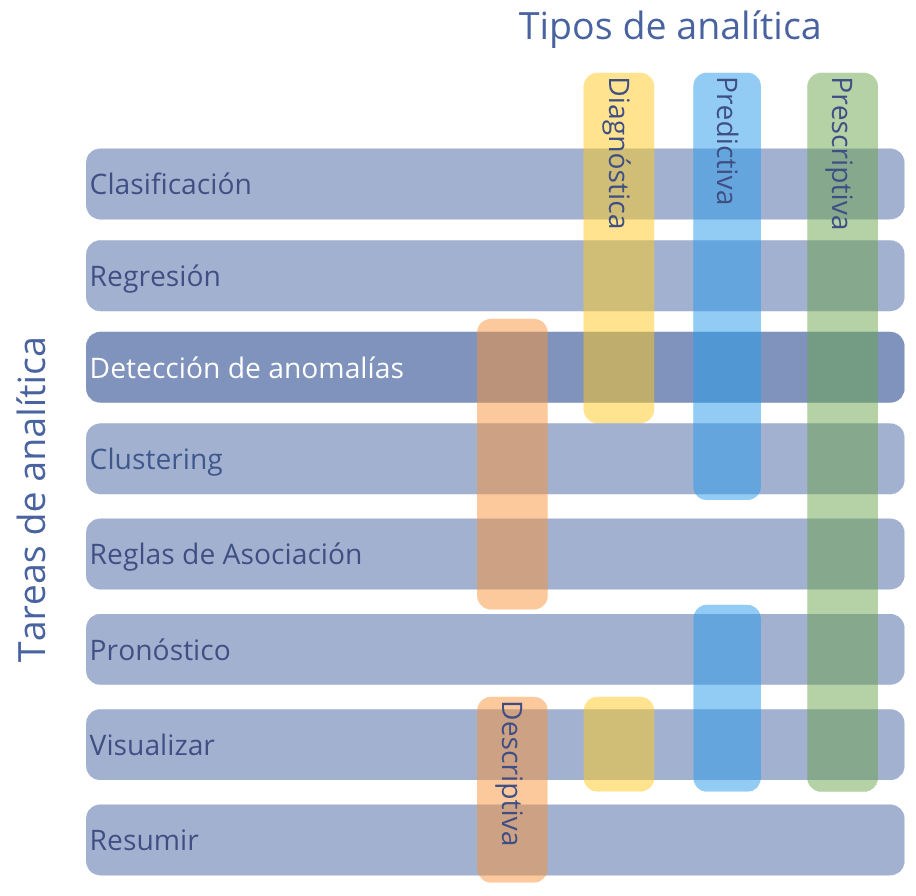
La analítica descriptiva responde a la pregunta ¿qué está pasando en el negocio?14. La detección de anomalías permite comprender qué está pasando en un momento determinado. Por ejemplo, puede identificar transacciones financieras inusuales, patrones de comportamiento de clientes atípicos o fluctuaciones en los datos de producción que requieren atención. Esta información descriptiva es fundamental para comprender la situación actual de la organización. De hecho, algunos de los métodos o algoritmos que se emplean en esta tarea se consideran como métodos exploratorios de datos, pues nos permiten entender características de un conjunto de datos. En el Capítulo 2 estudiaremos métodos que se pueden incluir en la etapa de exploración de datos para realizar cualquier tipo de tarea de analítica.
La analítica diagnóstica responde a la pregunta ¿por qué está pasando algo? En el contexto de las preguntas de detección de anomalías, dependiendo de los modelos y datos que se empleen, se podrá determinar por qué un individuo es considerado una anomalía. Esto podrá ocurrir en especial cuando se puedan emplear modelos de aprendizaje supervisado y modelos de clasificación como el Logit. La detección de anomalías se puede emplear para comprender por qué ciertos eventos inusuales están ocurriendo. Por ejemplo, podría identificar que las ventas anormalmente bajas de un periodo se deben a un cambio en la estrategia de marketing. Este nivel de análisis ayuda a identificar las causas raíz de los problemas o tendencias inusuales.
La analítica predictiva busca responder a la pregunta ¿qué es posible que ocurra? Los modelos de detección de anomalías también pueden emplearse para predecir futuros eventos inusuales. Por ejemplo, podría predecir posibles fraudes basándose en patrones de comportamiento pasados o anticipar problemas de calidad en la producción. Esto permite a las organizaciones tomar medidas preventivas antes de que ocurran eventos no deseados.
La analítica prescriptiva busca responder a la pregunta ¿qué necesito hacer? La detección de anomalías puede emplearse para recomendar acciones específicas para abordar eventos inusuales. Por ejemplo, podría recomendar cambios en las políticas de seguridad informática para evitar brechas de seguridad o ajustes en la cadena de suministro para mitigar problemas de logística. Esto ayuda a las organizaciones a tomar decisiones informadas y proactivas para mejorar su desempeño.
Hasta aquí hemos hablado de la tarea de analítica, el tipo de preguntas que puede responder y el tipo de análisis que se quiere realizar, pero aún no hemos definido qué es una anomalía. En la siguiente sección nos concentraremos en esto.
1.2 Anomalías: definición y tipos
Una anomalía es algo que difiere “significativamente” de lo que se considera común o “normal”15. En otras palabras, la tarea implica buscar una desviación, un error, un evento inusual, una excepción o patrones de comportamiento diferentes. Una anomalía corresponde a un evento raro (observación) que no encaja en el patrón y, por tanto, parece sospechoso. Una anomalía puede definirse como una observación o un conjunto de ellas que no parece seguir el mismo patrón que el resto de los datos en una o varias de sus características. Es decir, ¡es como la tarea de encontrar una aguja en un pajar!
Anomalías y outliers
El término outlier (o valor atípico en español) nace de la estadística y corresponde a una observación que difiere significativamente de las otras observaciones (Grubbs, 1969). Inicialmente el interés de los estadísticos y usuarios de la estadística para detectar outliers era “tratar” estas observaciones anómalas que pueden distorsionar el análisis y modelado estadístico.
El término anomalía se utiliza en la ciencia de datos y áreas relacionadas con la detección de patrones y comportamiento inusual en un sentido más amplio que la definición de outlier. Como se mencionó anteriormente, una anomalía es una observación que se desvía notablemente de un patrón o comportamiento esperado en un conjunto de datos.
Así se podría afirmar que todo outlier es una anomalía, pero no necesariamente una anomalía es un outlier.
En el contexto de la ciencia de datos, notarás que cuando se emplean técnicas estadísticas para detectar anomalías, se empleará mas el término outlier que anomalía. Y cuando empleamos técnicas de aprendizaje de máquina para encontrar observaciones anormales, nos referiremos a estas como anomalías.
Cuando la anomalía es en una observación, se le denomina anomalía puntual (Point anomaly en inglés). Una anomalía puntual se define como una única observación (data point) que es inusual o anómala en comparación con el resto de las observaciones. Las anomalías puntuales suelen ser un valor extremo en una de las características (variable) de la observación. Estas anomalías son relativamente fáciles de identificar, ya que son puntos únicos que se encuentran lejos de donde se encuentran la mayoría de los datos. Este tipo de anomalía también se conoce como anomalía global.
Por ejemplo, un día del mes de abril puede presentar una temperatura muy alta frente a lo esperado. En este caso, la observación es el día, la variable es la temperatura y tenemos un día anómalo: una anomalía puntual. Consideremos otro ejemplo, en un conjunto de datos de ventas diarias, una anomalía puntual podría ser un día con una venta extremadamente alta o extremadamente baja en comparación con los otros días. Identificar estas anomalías puede ser importante para comprender las causas subyacentes de las fluctuaciones en las ventas y tomar medidas para abordarlas. En los Capítulos 2, 3 , 4 y 5 estudiaremos técnicas para detectar este tipo de anomalías. En el Capítulo 8 estudiaremos la técnica conocida como la distancia kNN que también es empleada para detectar anomalías globales.
Por otro lado, una anomalía colectiva (collective anomaly en inglés) es un conjunto de observaciones similares (en una o varias variables) que pueden considerarse anómalas en conjunto cuando se comparan con el resto de los datos. Regresando a nuestro ejemplo de la temperatura, podríamos tener una semana entera en el mes de abril con temperaturas anormalmente altas. En ese caso tenemos una anomalía colectiva. Las observaciones con anomalía colectiva pueden ser también cada una de ellas anomalías puntuales, pero no siempre debe ser así. Por ejemplo, en el caso de las temperaturas diarias podemos tener una ola de calor, un solo día caliente para abril puede considerarse algo normal, pero varios días de temperaturas altas consecutivos pueden hacer que el evento se considere una anomalía. Análogamente, en el caso de las ventas diarias podríamos ver ventas durante una semana o un mes que sean anormalmente bajas. Esas ventas serían una anomalía colectiva.
Las anomalías colectivas, también son conocidas como anomalías distribuidas o anomalías grupales. Estas anomalías pueden ser difíciles de identificar, ya que no están presentes en puntos individuales, sino en patrones o grupos de datos.
Otro ejemplo de anomalía colectiva, que nos permite entender mejor el concepto, lo podríamos encontrar en datos del tráfico de una ciudad. Una anomalía colectiva podría ser un patrón de tráfico inusual que afecta a varias calles o manzanas de la ciudad al mismo tiempo. Identificar estas anomalías colectivas puede requerir técnicas como el análisis de clústering con el método DBSCAN que estudiaremos en el Capítulo 9 o el Isolation Forest que estudiaremos en el Capítulo 10.
Otra forma de clasificar las anomalías tiene que ver con el contexto. Las anomalías contextuales, también conocidas como anomalías locales, son observaciones que son anómalas en un contexto específico pero normales en otro contexto. Estas anomalías pueden ser difíciles de detectar, ya que requieren una comprensión profunda del dominio del problema y del contexto en el que se recopilaron los datos.
Por ejemplo, regresando al ejemplo de la temperatura, un día de 30 grados Celsius podría considerarse normal en un enero en una ciudad de una región tropical como la costa atlántica colombiana, pero anómala para una ciudad en el norte de los Estados Unidos en ese mismo mes. Identificar estas anomalías contextuales puede requerir no solo el análisis de los datos en sí, sino también información adicional sobre el entorno en el que se recopilaron los datos. En los Capítulos 8 estudiaremos la métrica LOF que permite la identificación de anomalías locales. En los Capítulos 9 y 10 también estudiaremos técnicas que permiten identificar este tipo de anomalías: DBSCAN y Isolation Forest.
Otra forma de clasificar16 las anomalías es dependiendo del número de features que se consideren. Las anomalías univariadas son valores atípicos que se detectan considerando únicamente una variable (o característica). En el Capítulo 2 discutiremos más sobre este tipo de anomalías y estudiaremos métodos para detectar este tipo de anomalías. En los Capítulos 3 y 6 también estudiaremos técnicas para detectar anomalías univariadas.
Por otro lado, las anomalías multivariadas son valores atípicos que se detectan considerando múltiples variables simultáneamente. En este caso, la anomalía se identifica en el contexto de la relación entre dos o más dimensiones de datos. En la introducción del Capítulo 2 se presenta una discusión sobre la diferencia entre estas anomalías y las univariadas. En los Capítulos 4 y 5 discutimos técnicas que solo están diseñadas para detectar anomalías multivariadas. En los Capítulos 8 a 10 estudiaremos técnicas que permiten detectar tanto anomalías univariadas como multivariadas.
Anomalías y excepciones
En el contexto de la ciencia de datos, las anomalías y las excepciones son conceptos que se utilizan como sinónimos. Si bien ambos conceptos se emplean para describir eventos o casos que se desvían de lo que se considera normal o esperado, existen diferencias sutiles entre estos dos conceptos.
Una anomalía se refiere a una observación o evento que es “significativamente” diferente de la mayoría de los otros eventos en un conjunto de datos. Por otro lado, una excepción se refiere a un caso que se aparta de una regla, norma o criterio establecido. En este sentido, una excepción puede ser una anomalía, pero no necesariamente.
Las excepciones pueden ser eventos o situaciones que no siguen el patrón general o que no cumplen con ciertas condiciones predefinidas. Por ejemplo, en un sistema de detección de fraudes, una transacción que excede un cierto límite establecido podría considerarse una excepción, aunque no sea necesariamente una anomalía si es una transacción legítima.
Así, mientras que una anomalía se refiere a una observación inusual en un conjunto de datos, una excepción se refiere a un caso que se aparta de una regla o norma establecida, que puede o no ser una anomalía dependiendo del contexto y la interpretación. De acuerdo con la pregunta de negocio y los datos disponibles, en algunas situaciones la tarea de detección de anomalías se puede convertir en una tarea de detección de excepciones. En ambos casos, el objetivo es identificar eventos o situaciones que requieren una atención especial o una acción inmediata.
Las diferentes formas de clasificar las anomalías enumeradas anteriormente no son mutuamente excluyentes. Noten que unas anomalías contextuales podrían ser anomalías grupales y esas podrían ser univariadas o multivaridas. No existe una única taxonomía de las anomalías, estas definiciones de las anomalías son construidas típicamente para ilustrar el tipo de anomalía que un método puede detectar. Es más, las anomalías en campos específicos pueden tomar nombres especiales o clasificaciones especiales. Un ejemplo de esto es el campo de la detección de fraudes (Ver Sección 6.2).
En el mundo de los negocios, el análisis de anomalías puede aparecer en diferentes contextos. Por ejemplo, en los procesos productivos se quisiera detectar una anomalía en la planta de producción antes de que ocurra y solucionar los problemas antes de que ocurran. Esto permite ahorrar mucho dinero. En el e-marketing se emplea la detección de anomalías para, por ejemplo, detectar cambios en el costo por clic (CPC) de una campaña, identificar un número inusualmente bajo de visitantes a una página web (podría haberse dañado un enlace a esa página). Se puede emplear para detectar puntos de venta con un comportamiento anormalmente bajo o alto frente a los de los demás puntos de venta. En el mantenimiento predictivo, es común detectar anomalías en equipos o maquinaria industrial para predecir fallas y realizar mantenimiento preventivo. Esto típicamente puede reducir costos y tiempos de inactividad. En el área de la salud se pueden detectar patrones anómalos en datos de pacientes para identificar enfermedades o condiciones médicas antes de que se manifiesten clínicamente.
1.3 Comentarios finales
En este capítulo, hemos explorado la importancia de la detección de anomalías en el ámbito de las organizaciones. Desde anomalías puntuales hasta anomalías colectivas, contextuales y multivariadas, estas desviaciones de lo “normal” pueden tener un impacto significativo en las organizaciones y sus operaciones.
La detección de anomalías nos permite identificar eventos inusuales, patrones de comportamiento atípicos y tendencias anómalas en los datos. Esto nos brinda la oportunidad de comprender mejor los problemas, tomar decisiones informadas y, en muchos casos, tomar medidas preventivas.
En los próximos capítulos, exploraremos diferentes técnicas y herramientas para la detección de anomalías, así como su implementación en R. Aprenderemos cómo aplicar modelos de aprendizaje no supervisado para la detección de anomalías. Pero antes de entrar a estudiar los modelos de aprendizaje de máquina, estudiaremos la aproximación estadística a la detección de anomalías.
¡Sigue leyendo para descubrir más sobre este apasionante campo de la detección de anomalías en el mundo del business analytics y cómo puedes implementarlo en R!
Referencias
Ver Alonso & Serrano (2025) para una discusión completa de qué es el *business analytics**, la importancia de la pregunta de negocio y los elementos que componen una buena pregunta de negocio.↩︎
Para una discusión detallada de esta tarea y cómo implementarla en R se puede consultar Alonso & Hoyos (2025)↩︎
Para una discusión detallada del modelo clásico de regresión y cómo implementarlo en R se puede consultar Alonso (2024).↩︎
Para una discusión detallada de esta tarea y cómo implementarla en R se puede consultar Alonso et al. (2025).↩︎
Para una discusión detallada de esta tarea y cómo implementarla en R, se puede consultar Alonso & Arboleda (2025).↩︎
Para una discusión detallada de esta tarea y cómo implementarla en R se puede consular Alonso (2022).↩︎
Es decir, a muchos individuos se les observa sus características y la variable objetivo (si aplica) en el mismo período.↩︎
En otras palabras, se observa el mismo individuo en diferentes periodos de tiempo, regularmente espaciados.↩︎
En el campo del aprendizaje de máquina se distinguen dos tipos de aprendizaje: supervisado y no supervisado. En el aprendizaje no supervisado, los datos no contienen etiquetas o la “respuesta correcta”. El aprendizaje no supervisado busca descubrir patrones o estructuras ocultas en los datos. En el Capítulo 7 se presenta una breve introducción a estos conceptos. En el Capítulo 11 de Alonso & Serrano (2025) se presenta una introducción mas extensa a estos conceptos.↩︎
Es decir, con la respuesta correcta ya conocida.↩︎
Es decir, la respuesta “correcta” de ser anomalía no es conocida.↩︎
Para ver una introducción rápida al tipo de datos que se emplean en el business analytics ver el video disponible en el siguiente enlace: https://youtu.be/2OxY2UTI_Bs.↩︎
En este contexto el término “normal” no se refiere a la distribución normal sino a la acepción más común y coloquial del término. Es decir, por normal queremos decir habitual u ordinario.↩︎
Otro tipo de anomalía específica para las muestras de series de tiempo son las anomalías temporales, también conocidas como anomalías secuenciales, son observaciones que se desvían significativamente de la tendencia temporal general de los datos. Por ejemplo, en una serie de ventas diarias, una anomalía temporal podría ser un pico de ventas inesperado en un día que normalmente tiene ventas bajas. Estas anomalías pueden ser difíciles de detectar, ya que requieren un análisis de series de tiempo para identificar patrones anómalos en el tiempo. En este libro no estudiaremos técnicas para detectar este tipo de anomalías.↩︎