7 ¿Qué es el Machine Learning (ML)?
En los Capítulos 2 al 6 nos concentramos en métodos estadísticos para la detección de anomalías. Estos modelos, desarrollados por la estadística, suelen estar fundamentados en una teoría probabilística explícita y en supuestos formales que permiten hacer inferencia sobre parámetros poblacionales. Ahora damos un paso distinto, en la tercera parte de este libro (Métodos de origen en el machine learning no supervisado) exploraremos métodos cuya raíz proviene del campo conocido como Machine Learning (ML).
El término ML (aprendizaje de máquina en español57) hace referencia a un conjunto de algoritmos que, a partir de datos, “aprenden” patrones sin necesidad de estar guiados por un modelo teórico previo o supuestos sobre la población de la que provienen los datos. La diferencia con la aproximación estadística tradicional es sutil pero fundamental. Mientras la estadística clásica busca principalmente explicar y validar hipótesis sobre relaciones poblacionales entre variables. Es decir, se centra en la inferencia sobre lo que ocurre en una población, el ML se preocupa por la capacidad de predicción y generalización del algoritmo frente a nuevos datos.
Otra diferencia está en la forma de trabajar con los supuestos. En la estadística, el punto de partida son supuestos sobre la distribución de los datos (normalidad, homocedasticidad, independencia, etc.). En este mundo la validez de los resultados depende que los supuestos de los modelos empleados sean validados. En cambio, en el ML los supuestos son menos estrictos y, en muchos casos, el enfoque es más empírico: se evalúa el rendimiento del modelo en función de su capacidad para predecir o clasificar correctamente nuevos datos, sin necesidad de validar formalmente los supuestos estadísticos. En el ML el énfasis está en la práctica y en la utilidad del modelo, más que en su fundamentación teórica o la capacidad de hacer inferencia sobre la población de la que provienen los datos. En este mundo la inferencia sobre el comportamiento poblacional no es el objetivo principal. Y por eso en este mundo los resultados típicamente no implican intervalos de confianza o pruebas de hipótesis.
Antes de iniciar esta sección del libro, es importante aclarar la relación de conceptos como el machine learning y la inteligencia artificial (IA). La IA es un campo amplio de las ciencias de la computación que desarrolla sistemas capaces de realizar tareas que normalmente requieren inteligencia humana, como el razonamiento, el aprendizaje, la percepción y la toma de decisiones. Dentro de la IA se encuentran áreas no mutuamente excluyentes como machine learning, deep learning, procesamiento de lenguaje natural, visión por computador, robótica, planificación y sistemas expertos (Mukhamediev et al., 2022).
El área más relevante de la IA para el business analytics es el machine learning, entendido como el conjunto de algoritmos que aprenden de los datos y generalizan a nuevos casos. Dentro de este se encuentra el deep learning, que utiliza redes neuronales profundas para identificar patrones complejos en grandes volúmenes de datos. Los modelos de lenguaje a gran escala (LLM), como GPT o Gemini, constituyen ejemplos recientes de deep learning aplicados al procesamiento del lenguaje natural, capaces de generar texto coherente y contextualizado (Bommasani et al., 2022). En Alonso & Serrano (2025) puedes encontrar una mayor discusión sobre estos temas.
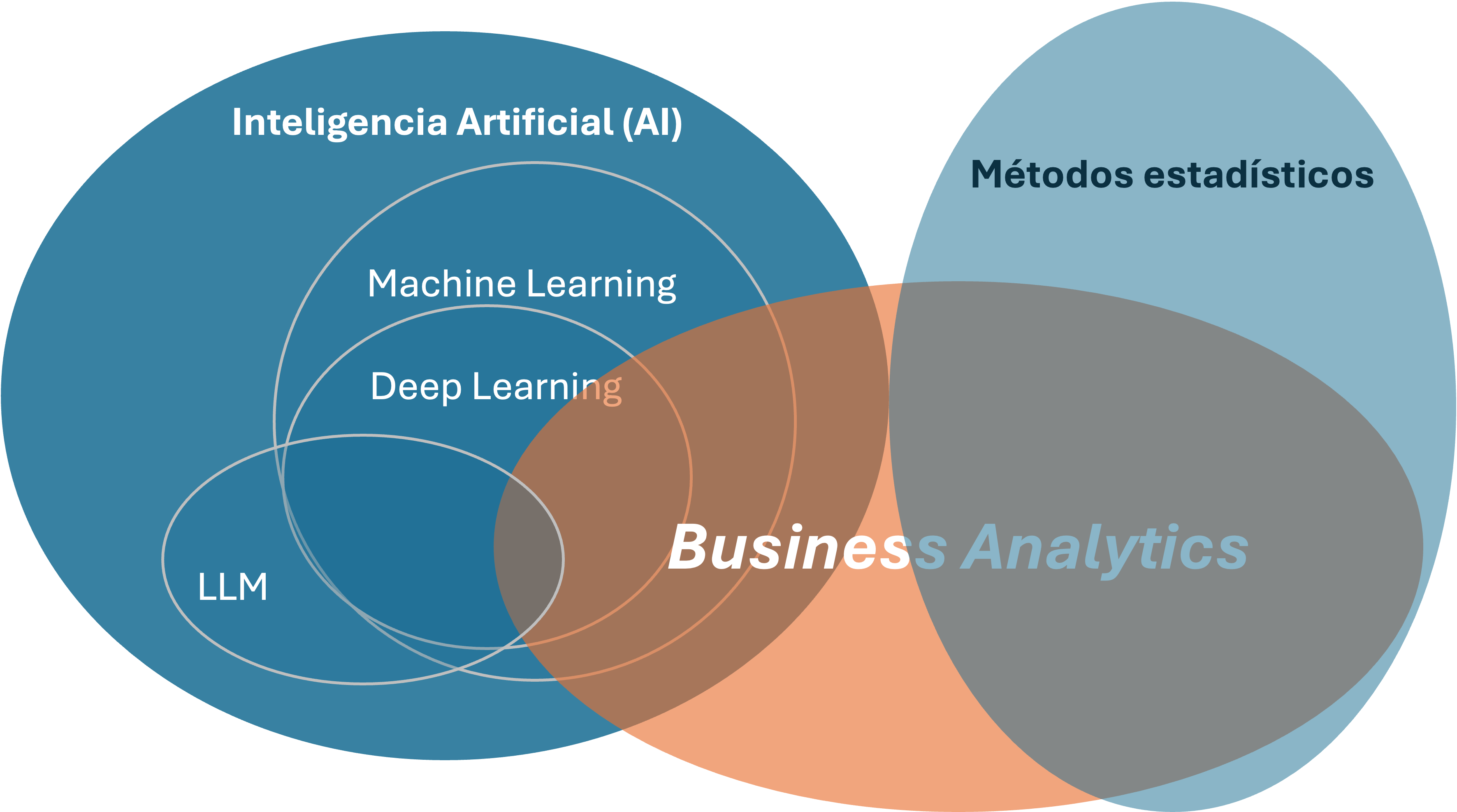
El ML es parte de la IA, pero no toda la IA es ML (Alonso & Serrano, 2025). Mientras que la IA también incluye métodos simbólicos y enfoques basados en reglas, el ML representa el componente que aprende directamente de los datos. La Figura 7.1 resume esta jerarquía conceptual de manera esquemática. El ML como subconjunto dentro del amplio dominio de la IA58.
Figura 7.1: Relación entre la IA, la estadística y el business analytics
En el ML se distinguen dos grandes familias de algoritmos: supervisados y no supervisados. En el aprendizaje supervisado, los datos contienen una variable objetivo conocida (etiqueta) y el modelo aprende a predecirla. Por ejemplo la tarea de clasificación o la regresión son ejemplos de aprendizaje supervisado. En la detección de anomalías, los métodos supervisados se emplean cuando se cuenta con un conjunto de datos etiquetados que identifican cuáles observaciones son normales y cuáles son anomalías. El modelo aprende a distinguir entre ambas clases basándose en las características de los datos. Sin embargo, en la práctica, este tipo de datos etiquetados son escasos o inexistentes, lo que limita la aplicabilidad de los métodos supervisados para la detección de anomalías.
En el aprendizaje no supervisado, en cambio, no existe una etiqueta previa. El objetivo es descubrir estructuras ocultas en los datos, como agrupaciones de individuos (clústering) o la identificación de observaciones atípicas (detección de anomalías). En la detección de anomalías, los métodos no supervisados son especialmente útiles cuando no se dispone de etiquetas que identifiquen las anomalías. El modelo busca patrones en los datos y señala aquellas observaciones que se desvían significativamente de estos patrones como posibles anomalías. Este es el caso de los ejemplos que hemos estudiado hasta ahora en este libro y los que estudiaremos en los siguientes capítulos.
La Figura 7.1 también ilustra la relación entre la estadística y el business analytics. El business analytics es un campo interdisciplinario que combina estadística, ML, gestión empresarial y toma de decisiones basada en datos para resolver problemas empresariales. En conjunto, estas disciplinas permiten a las organizaciones extraer valor de sus datos para mejorar la eficiencia operativa, optimizar estrategias y tomar decisiones informadas (Alonso & Serrano, 2025). En los Capítulos 2, 3, 4, 5 y 6 nos concentramos en métodos estadísticos para la detección de anomalías.
En esta parte del libro (Capítulos 8, 9 y 10) nos concentraremos en métodos de origen en el ML, particularmente en los métodos no supervisados, que como se mencionó en el Capítulo 1 son los tipos de modelos en los que nos concentramos en este libro ya que la mayoría de herramientas para detectar anomalías en el mundo del aprendizaje supervisado corresponden a modelos de clasificación que puedes estudiar en profundidad en Alonso & Hoyos (2025).
En el Capítulo 8 estudiaremos los métodos basados en la distancia entre observaciones, particularmente el método de los k vecinos más cercanos (kNN). En el Capítulo 9 estudiaremos los métodos basados en densidad, particularmente el método DBSCAN y sus variantes. Finalmente, en el Capítulo 10 estudiaremos los métodos basados en árboles de decisión, particularmente el método Isolation Forest. Con el estudios de estas aproximaciones podemos completar nuestra caja de herramientas para la detección de anomalías en datos no etiquetados como anómalos.