11 Reflexiones finales
En este libro hemos estudiado numerosas técnicas de detección de los diferentes tipos de anomalías, desde aproximaciones estadísticas clásicas hasta modelos provenientes del machine learning. Estas técnicas se emplean en diferentes momentos del proceso de transformar datos en insights para la toma de decisiones. En cada paso, el objetivo de emplear estas herramientas es diferente. Las técnicas estudiadas que emplean estadísticas descriptivas y métricas estadísticas estudiadas en el Capítulo 2, así como la distancia kNN (Capítulo 8), son herramientas que comúnmente se emplean en el proceso de ETL79 (Ver Figura 11.1). En esta parte del proceso, la detección de anomalías tiene como fin garantizar la consistencia e integridad de los datos cargados en las Bodegas de datos.
Figura 11.1: La detección de anomalías en el business analytics
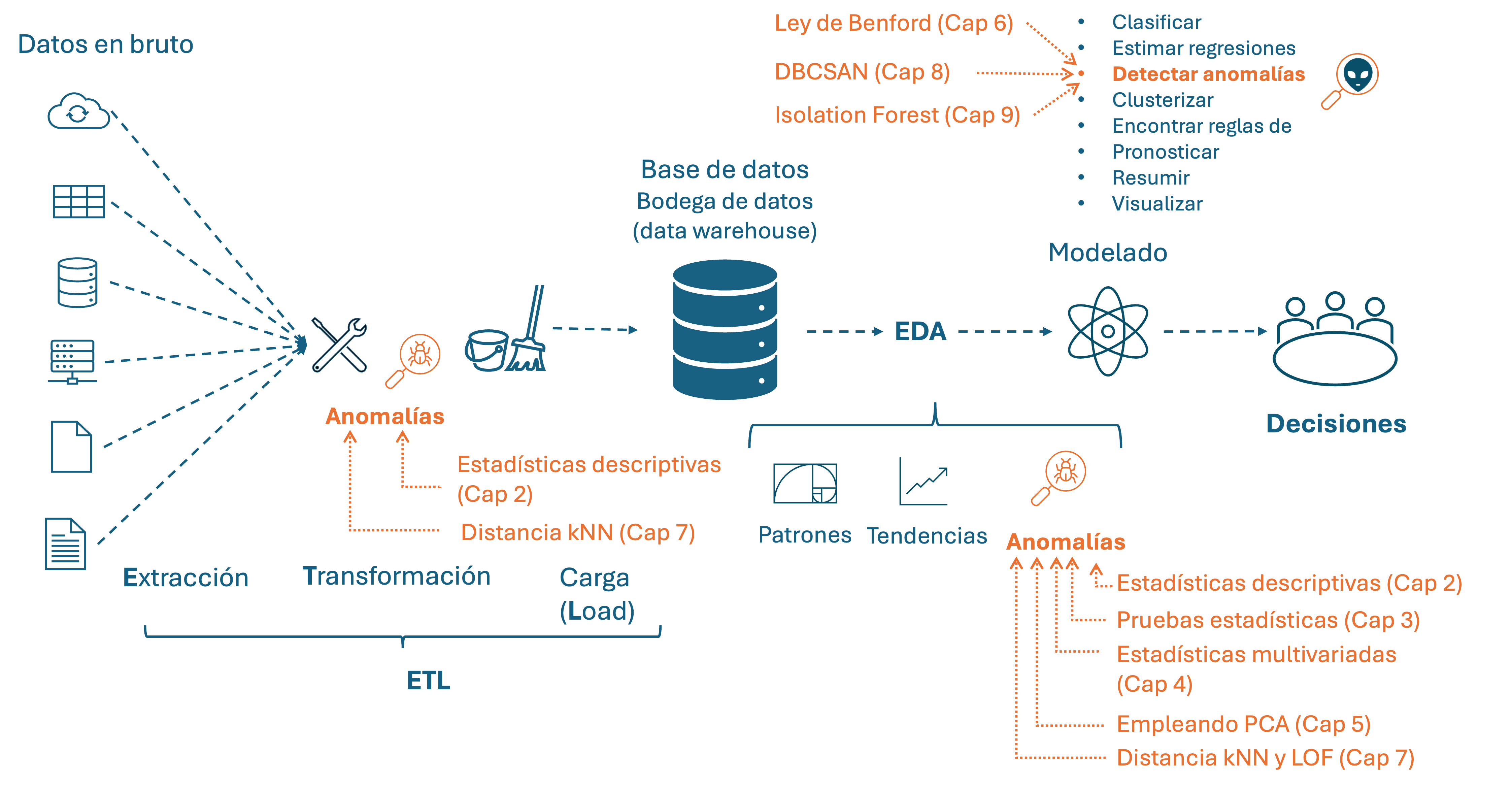
La herramientas para la detección de anomalías también son empleadas en el EDA80 con el fin de de encontrar datos atípicos que podrían afectar los resultados del análisis exploratorio y los modelos que posteriormente se entrenen o estimen. En el EDA típicamente se emplean herramientas como las métricas y estadísticas descriptivas estudiadas en el Capítulo 2, las pruebas estadísticas (Capítulo 3), las técnicas estadísticas para detectar outliers multivariados (Capítulo 4), la técnica del PCA (Capítulo 5) y la distancia kNN y el LOF (Capítulo 8). En la parte inferior derecha de la Figura 11.1 se muestra una representación de esto.
Finalmente, las herramientas de detección de anomalías son empleadas en el modelado como tal de los datos, que es la fase en la que nos concentramos en responder a la pregunta de negocio. En esta fase típicamente se emplean modelos como la Ley de Benford (Capítulo 6), el modelo DBSCAN (Capítulo 9) y el Isolation Forest (Capítulo 10) (Ver parte superior derecha de la Figura 11.1).
De esta manera hemos recorrido un largo camino para estudiar técnicas de detección de anomalías que son útiles para los científicos de datos no solo para responder preguntas de negocio relacionadas con la tarea de detección de anomalías, sino en su trabajo cotidiano que implique el EDA y eventualmente el proceso de ETL.
Si bien el libro ha cubierto una parte fundamental de los modelos disponibles para detectar anomalías, es importante reconocer que existen otros caminos no explorados aquí. Por un lado, dejamos fuera a los modelos supervisados de detección de anomalías, donde el algoritmo aprende a partir de ejemplos etiquetados de observaciones “normales” y “anómalas”. Estos métodos, que incluyen desde regresiones logísticas hasta Random Forests, constituyen un campo vasto que emplea los modelos de clasificación. Estos modelos son desarrollados en detalle en Alonso & Hoyos (2025). Te invitamos a estudiar este texto para complementar tu formación en la tarea de detección de anomalías.
Por otro lado, incluso dentro del aprendizaje no supervisado y de la estadística, existen múltiples aproximaciones que no han sido discutidas. Desde métodos robustos basados en teoría de valores extremos y funciones de densidad, hasta técnicas más recientes de autoencoders81 y variational autoencoders82. La riqueza de modelos posibles refleja que la detección de anomalías sigue siendo un territorio de innovación permanente.
El horizonte de este campo se amplía aún más con la irrupción de los LLM, como GPT o Gemini (Ver Capítulo 7 para una discusión de estos modelos). Aunque su uso en detección de anomalías todavía está en construcción, se vislumbran aplicaciones en la generación de características (feature engineering) asistida, la explicación de patrones complejos y la integración de datos heterogéneos (como por ejemplo textos, imágenes y series de tiempo) en modelos híbridos. Es probable que en los próximos años veamos algoritmos que combinen la potencia predictiva de los LLM con la precisión de los métodos estadísticos y de machine learning.
Con esta obra esperamos haber fortalecido tu caja de herramientas como científico de datos. La detección de anomalías, al final, es una forma de encontrar “la aguja en el pajar”, y dominar diferentes enfoques te permitirá enfrentar problemas diversos, desde la limpieza de datos hasta la identificación de fraudes o fallas críticas en sistemas. Y recuerda, en el mundo del business analytics, ¡la imaginación es el límite!
Referencias
Ver la Sección 3.1 para una discusión de este proceso y su relación con las herramientas de detección de anomalías.↩︎
En la Sección 2.1 se presenta una descripción de este proceso y su relación con las herramientas de detección de anomalías.↩︎
Un autoencoder es una red neuronal diseñada para aprender una representación comprimida de los datos (codificación) y luego reconstruirlos (decodificación). La idea es que, al obligar al modelo a comprimir y luego reconstruir, se revelen patrones ocultos y se identifiquen desviaciones: las anomalías suelen reconstruirse mal, lo que permite detectarlas.↩︎
Las redes neuronales variacionales (en inglés, variational autoencoders) son un tipo de red neuronal probabilística que no solo comprime y reconstruye los datos, sino que además aprende la distribución estadística subyacente. Esto permite generar nuevas observaciones similares a las originales y, en el contexto de anomalías, identificar aquellas que se desvían de la distribución aprendida.↩︎